







目录
一、概述
该论文提出高保真的单图像生成3D纹理网格的卷积重建模型(CRM),通过单输入图像生成六正交视图图像,并且利用U-Net网络生成高分辨率的三平面表示,再采用Flexicubes作为几何表示,来端到端的优化纹理网格。CRM模型可以在10秒钟生成高保真的纹理网格。
(1)添加了规范坐标图的扩散生成(CCM),丰富模型对空间关系和几何的理解
(2)直接使用Flexicubes作为几何表示,可以直接进行梯度优化,并端到端得到纹理网格,相比于以往需要间接通过NeRF或3DGS来进行表示,该方法的推理流程更加简单和高质量。
(3)U-Net使用了UNet2DModel模块,而不是basic unet或是其他resblock模块。
二、相关工作
1、三维生成中的分数蒸馏
首先是DreamFusion钟提出了分数蒸馏采样SDS,可以利用大规模图像扩散模型进行迭代式精炼3D模型以对齐具体的prompts或者图像,这也是实现了不在3D数据集上训练就轻松实现3D生成。
另外是ProlificDreamer提出的变分分数蒸馏VSD,进一步改善了SDS的过饱和问题,并提高多样性。对于Zero123,MVDream,ImageDream等方法缓解了使用3D数据微调扩散模型中多视角的问题,也有一些方法针对于速度和质量,但是基于分数蒸馏的方法仍然需要几分钟或者几小时进行生成。
2、稀疏视角下的3D生成
SyncDreamer生成多视图一致的图像,在使用NeuS进行重建。
Wonder3D采用跨域扩散模型,将2D图像和3D模型之间的生成过程统一到同一个扩散框架中,从而实现单张图像到3D模型的端到端生成。
Direct2.5提高了2.5D扩散的模型,但是仍然需要稀疏视角下重建工作的测试时间的优化。
3、前馈3D生成模型
前馈神经网络相较于上述方法来说,重建速度更快。近期的工作主要在Objaverse大型3D数据集上训练,如One-2-3-45,通过输入图像生成多视角图像,并通过网络获得3D对象。LRM系列通过Transformer来提高生成模型质量。TGS和LGM使用GS Splatting来作最后的几何表示。而我们的方法基于一个更有战略性设计的结构以及端到端的输出Mesh。
三、前置知识
1、零信噪比训练
Zero-SNR方法,可以在扩散模型训练中缓解初始高斯噪声与训练样本最大噪声之间的差异问题,提高模型的质量和鲁棒性。
2、FlexiCubes
FlexiCubes是一种高品质的等值面表示法,专门针对几何、视觉甚至物理目标的基于梯度的网格优化设计。
Flexicubes通过双重Marching Cubes算法从特征网格中提取高保真的几何细节,而不需要后处理步骤,实现端到端训练。也包含了SDF、Color、weight等信息,更好地表达几何细节,生成更高质量的纹理网格。
四、CRM
CRM框架由三部分组成,单视图生成多视图,CCM生成,纹理网格生成。
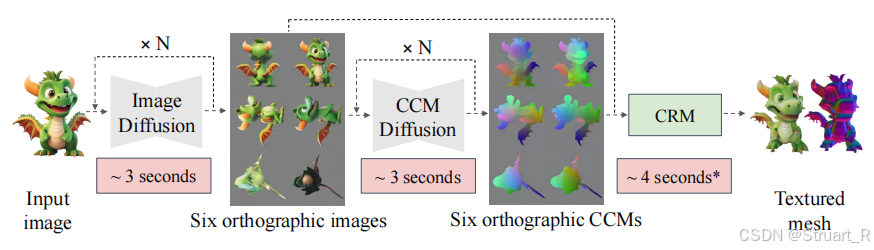
1、单视图生成多视图
首先输入单张输入图像,经过预训练的ImageDream的扩散模型生成多视图,预训练模型是在Objaverse上进行训练,原有的ImageDream是生成四视角图像,而我们添加两个上下视图,扩展到六视图图像。
2、CCM生成
CCM(Canonical Coordinate Map)规范坐标映射,一种包含3通道的图像,值在[0,1]之间,表示点在标准空间中的坐标,相较于RGB图像相比,包含了更多的几何信息,更好地预测3D物体的几何形状。
通过之前生成的六视图作为输入,通过初始化的ImageDream得到6个正交的CCM。
在训练过程中引入了Zero-SNR,随机裁剪,轮廓增强方式。在后续的消融实验中发现,Zero-SNR和随机裁剪都对于定量的指标有一定提升,但是轮廓增强没有提升,但是提升了对于数据集以外的数据的鲁棒性。
3、纹理网格生成
首先将之前输入的六视图RGB与六视图CCM进行拼接成四个图像得到12维特征(256*768*12)。之后通过卷积的U-Net进行解码,此处的U-Net使用diffusers库中的UNet2DModel得到32维的Rolled-out Triplane特征,之后reshape成三个平面(256*256*72*3)。
之后通过三个包含两个隐藏层的MLP分别生成Flexicubes几何网格的SDF,颜色,权重,之后重建为带有纹理的Mesh网格。
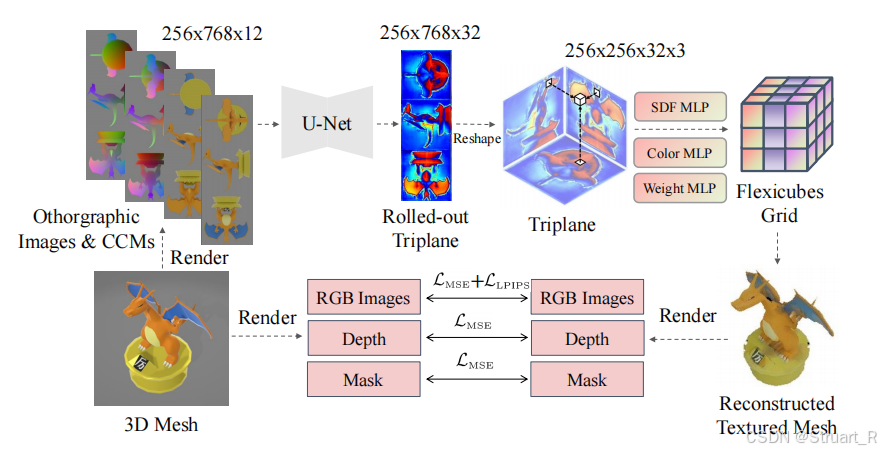
4、损失函数
损失函数分为三个部分,纹理损失,深度图损失,Mask损失。此外还增加了网格质量正则化损失。
纹理损失:MSE损失+LPIPS损失
深度图损失:MSE损失
Mask损失:MSE损失
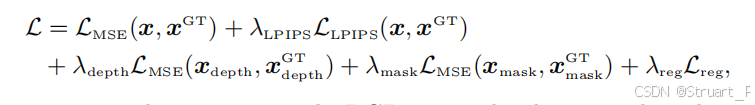
五、实验
下面实验使用GSO数据集,由谷歌提出,其中包括1030个扫描对象和其元数据,目的是使用机器人基于高保真的3D模型,在环境中进行识别和抓取的工作。

1、3D几何特征的对比
在GSO数据集上计算几何特征考虑倒角距离,体IoU,F-Score。

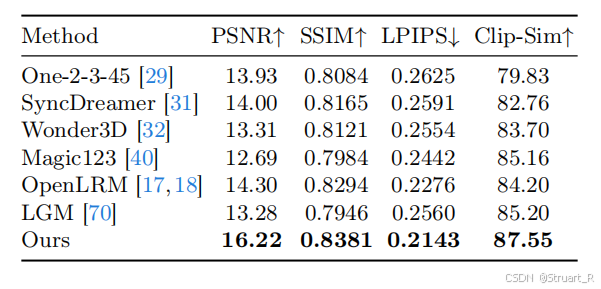
2、3D纹理特征的对比
在GSO数据集上计算纹理特征。
其中Clip-Sim是一种基于OpenAI CLIP的相似度度量指标,通过将图像和文字同时嵌入到多模态空间,计算文本与图像的相似度。
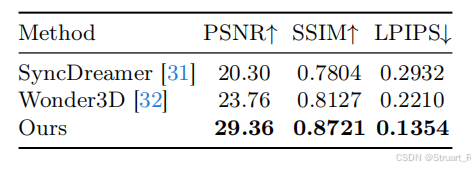
3、渲染视角图像对比
GSO数据集上计算新渲染的视角图像的指标对比
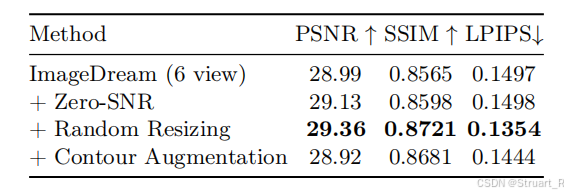
4、消融实验
上面有提到过,在训练过程中引入了Zero-SNR,随机裁剪,轮廓增强方式。在后续的消融实验中发现,Zero-SNR和随机裁剪都对于定量的指标有一定提升,但是轮廓增强没有提升,但是提升了对于数据集以外的数据的鲁棒性。
参考项目:CRM: Single Image to 3D Textured Mesh with Convolutional Reconstruction Model

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









