







欢迎大家关注全网生信学习者系列:
- WX公zhong号:生信学习者
- Xiao hong书:生信学习者
- 知hu:生信学习者
- CDSN:生信学习者2

随机森林是常用的非线性用于构建分类器的算法,它是由数目众多的弱决策树构建成森林进而对结果进行投票判断标签的方法。
随机森林用于分类器的算法过程,
- 随机切分样本,然后选择2/3用于建模,剩余1/3用于验证袋外误差;
- 随机选择特征构建决策树,每个叶子节点分成二类;
- 根据GINI系数判断分类内部纯度程度,进行裁剪树枝;
- 1/3数据预测,根据每个决策树的结果投票确定标签;
- 输出标签结果,并给出OOB rate
随机的含义在于样本和特征是随机选择去构建决策树,这可以有效避免偏差,另外弱分类器组成强分类器也即是多棵决策树组成森林能提升模型效果。
本文旨在通过R实现随机森林的应用,总共包含:
- 下载数据
- 加载R包
- 数据切割
- 调参(选择最佳决策树数目)
- 建模(重要性得分)
- 多次建模选择最佳特征数目(基于OOB rate)
- 多元回归分析筛选相关特征
- 风险得分
- 重新建模
- 模型效能评估
下载数据
本文所需的数据来自于Breast-cancer-risk-prediction项目的BreastCancer_clean.csv,大家通过以下链接下载:
- 百度网盘链接:https://pan.baidu.com/s/10BBCZO9iJkwmXJW4Y7QRQQ
- 提取码: 请关注WX公zhong号_生信学习者_后台发送 随机森林二分类 获取提取码
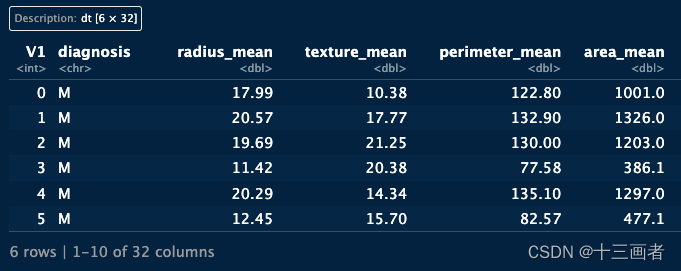
该数据集包含569份恶性和良性肿瘤的样本的32类指标,通过这些特征构建区分恶性和良性肿瘤的随机森林分类器
The Breast Cancer datasets is available machine learning repository maintained by the University of California, Irvine. The dataset contains 569 samples of malignant and benign tumor cells.
加载R包
knitr::opts_chunk$set(message = FALSE, warning = FALSE)
library(dplyr)
library(tibble)
library(randomForest)
library(ggplot2)
library(data.table)
library(caret)
library(pROC)
# rm(list = ls())
options(stringsAsFactors = F)
options(future.globals.maxSize = 1000 * 1024^2)
group_names <- c("M", "B")
导入数据
datset <- data.table::fread("clean_data.csv")
head(datset)
数据标准化
上述每一类特征的单位存在较大的不同,在做线性的算法分类模型时候需要对数据标准化,降低不同单位带来的影响。因为随机森林是非线性的算法,所以暂时不需要对特征进行标准化。
数据切割
对数据集按照70%的比例划分成训练集和测试集,其中训练集用于构建模型,测试集用于评估模型效能。
另外,在这一步前也有教程对特征进行选择,筛选组间差异大的特征用于建模。
这里使用 caret::createDataPartition函数进行划分数据集,它能够根据组间比例合理分割数据。
mdat <- datset %>%
dplyr::select(-V1) %>%
dplyr::rename(Group = diagnosis) %>%
dplyr::mutate(Group = factor(Group, levels = group_names)) %>%
data.frame()
colnames(mdat) <- make.names(colnames(mdat))
set.seed(123)
trainIndex <- caret::createDataPartition(
mdat$Group,
p = 0.7,
list = FALSE,
times = 1)
trainData <- mdat[trainIndex, ]
X_train <- trainData[, -1]
y_train <- trainData[, 1]
testData <- mdat[-trainIndex, ]
X_test <- testData[, -1]
y_test <- testData[, 1]
调参(选择最佳决策树数目)
随机森林算法的参数众多,本文选择对mtry和ntree两个参数进行调参,其他均使用默认参数。
- mtry:随机选择特征数目
- ntree:构成森林的决策树数目
# N-repeat K-fold cross-validation
myControl <- trainControl(
method = "repeatedcv",
number = 10,
repeats = 3,
search = "random",
classProbs = TRUE,
verboseIter = TRUE,
allowParallel = TRUE)
# customRF
# https://machinelearningmastery.com/tune-machine-learning-algorithms-in-r/
customRF <- list(type = "Classification",
library = "randomForest",
loop = NULL)
customRF$parameters <- data.frame(
parameter = c("mtry", "ntree"),
class = rep("numeric", 2),
label = c("mtry", "ntree"))
customRF$grid <- function(x, y, len = NULL, search = "grid") {}
customRF$fit <- function(x, y, wts, param, lev, last, weights, classProbs, ...) {
randomForest(x, y, mtry = param$mtry, ntree=param$ntree, ...)
}
customRF$predict <- function(modelFit, newdata, preProc = NULL, submodels = NULL) {
predict(modelFit, newdata)
}
customRF$prob <- function(modelFit, newdata, preProc = NULL, submodels = NULL) {
predict(modelFit, newdata, type = "prob")
}
customRF$sort <- function(x) {x[order(x[, 1]), ]}
customRF$levels <- function(x) {x$classes}
# tuning parameters
tuneGrid <- expand.grid(
.mtry = c(2:15), # sqrt(ncol(X_train))
.ntree = seq(500, 2000, 500))
# Register parallel cores
doParallel::registerDoParallel(4)
# train model
set.seed(123)
tune_fit <- train(
Group ~.,
data = trainData,
method = customRF, #"rf",
trControl = myControl,
tuneGrid = tuneGrid,
metric = "Accuracy",
verbose = FALSE)
## Plot model accuracy vs different values of Cost
print(plot(tune_fit))
## Print the best tuning parameter that maximizes model accuracy
optimalVar <- data.frame(tune_fit$results[which.max(tune_fit$results[, 3]), ])
print(optimalVar)


结果:
- 最佳随机特征数目(使用32个特征用于建模,从中随机抽取7个特征构建决策树):7
- 最佳决策树数目:1000
建模
使用上述最佳参数建模
set.seed(123)
rf_fit <- randomForest(
Group ~ .,
data = trainData,
importance = TRUE,
proximity = TRUE,
mtry = optimalVar$mtry,
ntree = optimalVar$ntree)
rf_fit
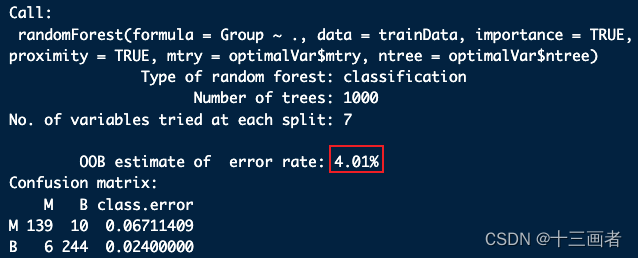
结果:
- 该模型的袋外误差OOB仅为4.01%,也即是准确率高达95.99%。
特征的重要性得分
获取所有特征的重要性得分,此处使用MeanDecreaseAccuracy。
imp_biomarker <- tibble::as_tibble(round(importance(rf_fit), 2), rownames = "Features") %>%
dplyr::arrange(desc(MeanDecreaseAccuracy))
imp_biomarker

结果:
- MeanDecreaseAccuracy描述的是平均降低准确度,比如该模型剔除area_worst特征,则它的准确将下降24.52%。
多次建模选择最佳特征数目(基于OOB rate)
上述模型选了所有32个特征用于建模,这是单次建模的结果,为了更好确定最佳特征数目,采用五次建模的结果寻找最小OOB rate对应的特征数目作为最佳特征数目。
另外,最佳决策树数目参考第一次模型的 1000,也作为本次最佳决策树数目。
error.cv <- c()
for (i in 1:5){
print(i)
set.seed(i)
fit <- rfcv(trainx = X_train,
trainy = y_train,
cv.fold = 5,
scale = "log",
step = 0.9,
ntree = optimalVar$ntree)
error.cv <- cbind(error.cv, fit$error.cv)
}
n.var <- as.numeric(rownames(error.cv))
colnames(error.cv) <- paste('error', 1:5, sep = '.')
err.mean <- apply(error.cv, 1, mean)
err.df <- data.frame(num = n.var,
err.mean = err.mean,
error.cv)
head(err.df[, 1:6])
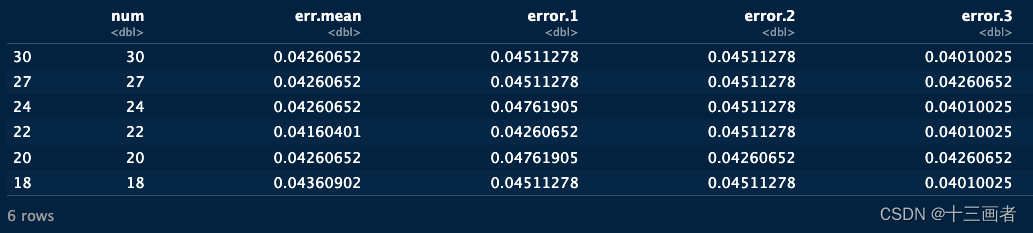
结果:
- 从OOB的结果看,每次建模的数值都会存在波动。
可视化上述OOB rate结果
optimal <- err.df$num[which(err.df$err.mean == min(err.df$err.mean))]
main_theme <-
theme(
panel.background = element_blank(),
panel.grid = element_blank(),
axis.line.x = element_line(linewidth = 0.5, color = "black"),
axis.line.y = element_line(linewidth = 0.5, color = "black"),
axis.ticks = element_line(color = "black"),
axis.text = element_text(color = "black", size = 12),
legend.position = "right",
legend.background = element_blank(),
legend.key = element_blank(),
legend.text = element_text(size = 12),
text = element_text(family = "sans", size = 12))
pl <-
ggplot(data = err.df, aes(x = err.df$num)) +
geom_line(aes(y = err.df$error.1), color = 'grey', linewidth = 0.5) +
geom_line(aes(y = err.df$error.2), color = 'grey', linewidth = 0.5) +
geom_line(aes(y = err.df$error.3), color = 'grey', linewidth = 0.5) +
geom_line(aes(y = err.df$error.4), color = 'grey', linewidth = 0.5) +
geom_line(aes(y = err.df$error.5), color = 'grey', linewidth = 0.5) +
geom_line(aes(y = err.df$err.mean), color = 'black', linewidth = 0.5) +
geom_vline(xintercept = optimal, color = 'red', lwd = 0.36, linetype = 2) +
coord_trans(x = "log2") +
scale_x_continuous(breaks = c(1, 5, 10, 20, 30)) +
labs(x = 'Number of Features ', y = 'Cross-validation error rate') +
annotate("text",
x = optimal,
y = max(err.df$err.mean),
label = paste("Optimal = ", optimal, sep = ""),
color = "red") +
main_theme
pl
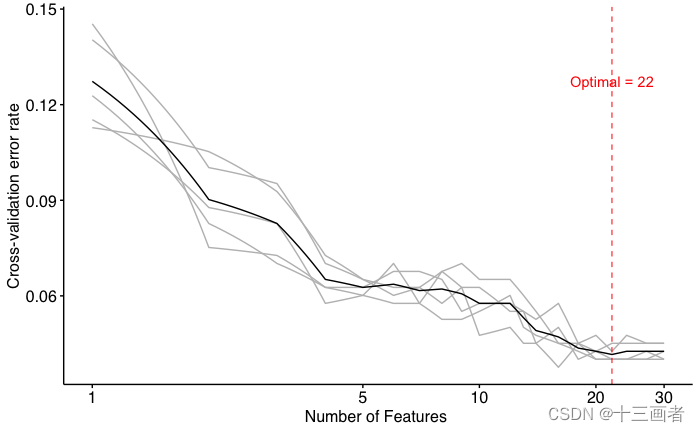
结果:
- 袋外误差OOB rate从特征数目为1到特征数目为20呈快速下降趋势,虽然下降数目仅在小数点二位上;
- 最佳特征数目是22,也即是选择重要性得分最高的22个特征即可(原本是32个特征,剔除10个特征用于建模)。
22个特征重要性得分可视化
imp_biomarker[1:optimal, ] %>%
dplyr::select(Features, MeanDecreaseAccuracy) %>%
dplyr::arrange(MeanDecreaseAccuracy) %>%
dplyr::mutate(Features = forcats::fct_inorder(Features)) %>%
ggplot(aes(x = Features, y = MeanDecreaseAccuracy))+
geom_bar(stat = "identity", fill = "white", color = "blue") +
labs(x = "", y = "Mean decrease accuracy") +
coord_flip() +
main_theme
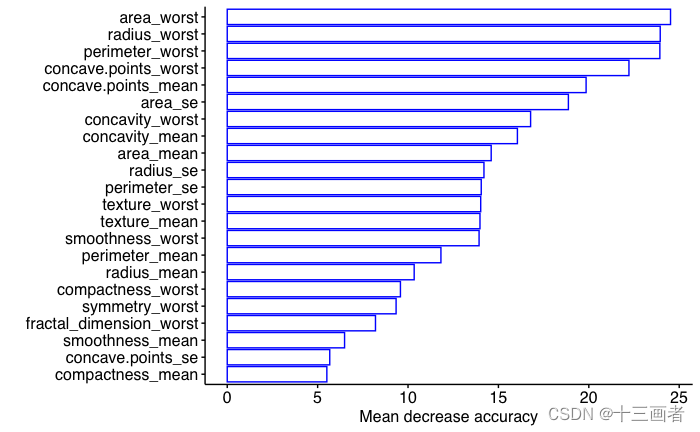
结果:
- MeanDecreaseAccuracy得分最高的是area_worst(MDA = 24.52%)
多元回归分析筛选相关特征
上述22个特征在建模过程还是偏多,可以通过多元回归分析筛选与响应变量(分类变量)最相关的自变量。
- 转换字符型标签成数值型
- 标准化自变量,降低不同单位的影响
- 采用logist regression算法
该步骤可选择也可不选择,因为后续分析发现如果严格按照pvalue < 0.05则仅能筛选到2-3个特征。
mdat_mulvar <- mdat |>
dplyr::select(all_of(c("Group", imp_biomarker[1:optimal, ]$Features))) |>
dplyr::mutate(Group = ifelse(Group == group_names[1], 1, 0))
mdat_mulvar[, -1] <- scale(mdat_mulvar[, -1], center = TRUE, scale = TRUE)
fma <- formula(paste0(colnames(mdat_mulvar)[1], " ~ ",
paste(colnames(mdat_mulvar)[2:ncol(mdat_mulvar)], collapse = " + ")))
fit <- glm(fma, data = mdat_mulvar, family = "binomial")
dat_coef <- coef(summary(fit)) |>
as.data.frame() |>
dplyr::slice(-1) |>
dplyr::filter(`Pr(>|z|)` < 0.2) |>
tibble::rownames_to_column("FeatureID")
head(dat_coef)

结果:
- 在选择Pr(>|z|) < 0.05后,结果不好,后将阈值设置为Pr(>|z|) < 0.2,最终5个特征符合要求。
疾病风险得分
nomogram是一类可以可视化上述5个特征对恶性肿瘤贡献的图形,它也是通过多元线性回归对疾病贡献得到打分,然后分别累加各个特征对疾病的得分得到一个总分,最后总分对应疾病分享百分比。
该处没有对自变量进行标准化,本来是要做的,但考虑到每个指标所含有的临床学意义,就使用了原始值。
library(rms)
selected_columns <- c("Group", dat_coef$FeatureID)
nom_optimal <- trainData %>%
dplyr::select(all_of(selected_columns)) |>
dplyr::mutate(Group = ifelse(Group == "B", 0, 1))
ddist <- datadist(nom_optimal[, -1])
options(datadist = "ddist")
fit_nom <- lrm(formula(paste0(colnames(nom_optimal)[1], " ~ ",
paste(colnames(nom_optimal)[2:ncol(nom_optimal)], collapse = " + "))),
data = nom_optimal)
nom <- nomogram(fit_nom, fun = plogis, funlabel = "Risk of Disease")
plot(nom)

结果:
concave points_mean(凹点), concavity_worst(凹度), texture_worst(质地) 和 symmetry_worst(对称) 都随着数值增大获得更高的疾病得分, 而 compactness_mean(紧密) 则是数值越高,疾病得分越低。综合这五个指标的疾病得分即可获得疾病总得分,然后再对应到疾病风险概率上。
Notice: 上述四个指标均与乳腺癌发生正相关,而最后一个指标则是负相关,这在临床上也是符合要求的
比如:
- concave points_mean_= 0.04 (20 points)
- concavity_worst = 1.2 (20 points)
- texture_worst = 25 (10 points)
- symmetry_worst = 0.4 (10 points)
- compactness_mean = 0.25 (20 points)
计算得分总和:
- 20 + 20 + 10 + 10 + 20 = 80
80分对应疾病风险概率是100%,也即是说某位检查者的上述五类指标符合该要求,意味着她有100%的概率患有恶性乳腺癌。
重新建模
使用上述五个指标重新建模
selected_columns <- c("Group", dat_coef$FeatureID)
trainData_optimal <- trainData %>%
dplyr::select(all_of(selected_columns))
testData_optimal <- testData %>%
dplyr::select(all_of(selected_columns))
set.seed(123)
rf_fit_optimal <- randomForest(
Group ~ .,
data = trainData_optimal,
importance = TRUE,
proximity = TRUE,
ntree = optimalVar$ntree)
rf_fit_optimal
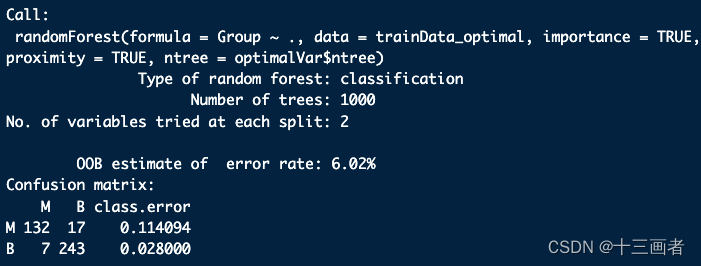
结果:
- 重新构建的模型的袋外误差OOB为6.02%,也即是准确率是93.98%
- 相比32个特征的模型,5个特征的模型准确率下降了**2%**左右,这是一个可以接受的范围
评估模型效能
评估模型效能有各类指数,通常可通过混淆矩阵获取。本文评估仅给出混淆矩阵和ROC曲线。
- 混淆矩阵
group_names <- c("B", "M")
pred_raw <- predict(rf_fit_optimal, newdata = testData_optimal, type = "response")
print(caret::confusionMatrix(pred_raw, testData_optimal$Group))
pred_prob <- predict(rf_fit_optimal, newdata = testData_optimal, type = "prob")

- ROC曲线
AUROC <- function(
DataTest,
PredProb = pred_prob,
label = group_names[1],
DataProf = profile) {
# DataTest = testData
# PredProb = pred_prob
# label = group_names[1]
# DataProf = profile
# ROC object
rocobj <- roc(DataTest$Group, PredProb[, 1])
# Youden index: cutoff point
# plot(rocobj,
# legacy.axes = TRUE,
# of = "thresholds",
# thresholds = "best",
# print.thres="best")
# AUROC data
roc <- data.frame(tpr = rocobj$sensitivities,
fpr = 1 - rocobj$specificities)
# AUC 95% CI
rocobj_CI <- roc(DataTest$Group, PredProb[, 1],
ci = TRUE, percent = TRUE)
roc_CI <- round(as.numeric(rocobj_CI$ci)/100, 3)
roc_CI_lab <- paste0(label,
" (", "AUC=", roc_CI[2],
", 95%CI ", roc_CI[1], "-", roc_CI[3],
")")
# ROC dataframe
rocbj_df <- data.frame(threshold = round(rocobj$thresholds, 3),
sensitivities = round(rocobj$sensitivities, 3),
specificities = round(rocobj$specificities, 3),
value = rocobj$sensitivities +
rocobj$specificities)
max_value_row <- which(max(rocbj_df$value) == rocbj_df$value)
threshold <- rocbj_df$threshold[max_value_row]
# plot
pl <- ggplot(data = roc, aes(x = fpr, y = tpr)) +
geom_path(color = "red", size = 1) +
geom_abline(intercept = 0, slope = 1,
color = "grey", linewidth = 1, linetype = 2) +
labs(x = "False Positive Rate (1 - Specificity)",
y = "True Positive Rate",
title = paste0("AUROC (", DataProf, " Features)")) +
annotate("text",
x = 1 - rocbj_df$specificities[max_value_row] + 0.15,
y = rocbj_df$sensitivities[max_value_row] - 0.05,
label = paste0(threshold, " (",
rocbj_df$specificities[max_value_row], ",",
rocbj_df$sensitivities[max_value_row], ")"),
size=5, family="serif") +
annotate("point",
x = 1 - rocbj_df$specificities[max_value_row],
y = rocbj_df$sensitivities[max_value_row],
color = "black", size = 2) +
annotate("text",
x = .75, y = .25,
label = roc_CI_lab,
size = 5, family = "serif") +
coord_cartesian(xlim = c(0, 1), ylim = c(0, 1)) +
theme_bw() +
theme(panel.background = element_rect(fill = "transparent"),
plot.title = element_text(color = "black", size = 14, face = "bold"),
axis.ticks.length = unit(0.4, "lines"),
axis.ticks = element_line(color = "black"),
axis.line = element_line(size = .5, color = "black"),
axis.title = element_text(color = "black", size = 12, face = "bold"),
axis.text = element_text(color = "black", size = 10),
text = element_text(size = 8, color = "black", family = "serif"))
res <- list(rocobj = rocobj,
roc_CI = roc_CI_lab,
roc_pl = pl)
return(res)
}
AUROC_res <- AUROC(
DataTest = testData,
PredProb = pred_prob,
label = group_names[1],
DataProf = optimal)
AUROC_res$roc_pl
结果:
- 混淆矩阵的sensitivity和specificity表明模型具有杰出的效能,能很好区分恶性和良性肿瘤;
- AUC曲线也表明类似的结果(AUC = 0.918)
总结
随机森林构建二分类器是一个很适合的算法,但如何做数据前处理以及调参和评估模型则需要谨慎。本文提供了较为详细的一个操作流,希望能够大家提供参考。最后总结一下:
- 数据分割
- 特征选择
- 挑选模型参数
- 模型评估
系统信息
devtools::session_info()
─ Session info ────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
setting value
version R version 4.1.3 (2022-03-10)
os macOS Monterey 12.2.1
system x86_64, darwin17.0
ui RStudio
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz Asia/Shanghai
date 2023-07-22
rstudio 2023.06.1+524 Mountain Hydrangea (desktop)
pandoc 3.1.1 @ /Applications/RStudio.app/Contents/Resources/app/quarto/bin/tools/ (via rmarkdown)
─ Packages ────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
ade4 1.7-22 2023-02-06 [2] CRAN (R 4.1.2)
ape 5.7-1 2023-03-13 [2] CRAN (R 4.1.2)
backports 1.4.1 2021-12-13 [2] CRAN (R 4.1.0)
base64enc 0.1-3 2015-07-28 [2] CRAN (R 4.1.0)
Biobase 2.54.0 2021-10-26 [2] Bioconductor
BiocGenerics 0.40.0 2021-10-26 [2] Bioconductor
biomformat 1.22.0 2021-10-26 [2] Bioconductor
Biostrings 2.62.0 2021-10-26 [2] Bioconductor
bitops 1.0-7 2021-04-24 [2] CRAN (R 4.1.0)
bslib 0.5.0 2023-06-09 [2] CRAN (R 4.1.3)
cachem 1.0.8 2023-05-01 [2] CRAN (R 4.1.2)
callr 3.7.3 2022-11-02 [2] CRAN (R 4.1.2)
caret * 6.0-94 2023-03-21 [2] CRAN (R 4.1.2)
checkmate 2.2.0 2023-04-27 [2] CRAN (R 4.1.2)
class 7.3-22 2023-05-03 [2] CRAN (R 4.1.2)
cli 3.6.1 2023-03-23 [2] CRAN (R 4.1.2)
cluster 2.1.4 2022-08-22 [2] CRAN (R 4.1.2)
codetools 0.2-19 2023-02-01 [2] CRAN (R 4.1.2)
colorspace 2.1-0 2023-01-23 [2] CRAN (R 4.1.2)
crayon 1.5.2 2022-09-29 [2] CRAN (R 4.1.2)
data.table * 1.14.8 2023-02-17 [2] CRAN (R 4.1.2)
DBI 1.1.3 2022-06-18 [2] CRAN (R 4.1.2)
devtools 2.4.5 2022-10-11 [2] CRAN (R 4.1.2)
digest 0.6.33 2023-07-07 [1] CRAN (R 4.1.3)
doParallel 1.0.17 2022-02-07 [2] CRAN (R 4.1.2)
dplyr * 1.1.2 2023-04-20 [2] CRAN (R 4.1.2)
e1071 1.7-13 2023-02-01 [2] CRAN (R 4.1.2)
ellipsis 0.3.2 2021-04-29 [2] CRAN (R 4.1.0)
evaluate 0.21 2023-05-05 [2] CRAN (R 4.1.2)
fansi 1.0.4 2023-01-22 [2] CRAN (R 4.1.2)
farver 2.1.1 2022-07-06 [2] CRAN (R 4.1.2)
fastmap 1.1.1 2023-02-24 [2] CRAN (R 4.1.2)
forcats 1.0.0 2023-01-29 [2] CRAN (R 4.1.2)
foreach 1.5.2 2022-02-02 [2] CRAN (R 4.1.2)
foreign 0.8-84 2022-12-06 [2] CRAN (R 4.1.2)
Formula 1.2-5 2023-02-24 [2] CRAN (R 4.1.2)
fs 1.6.2 2023-04-25 [2] CRAN (R 4.1.2)
future 1.33.0 2023-07-01 [2] CRAN (R 4.1.3)
future.apply 1.11.0 2023-05-21 [2] CRAN (R 4.1.3)
generics 0.1.3 2022-07-05 [2] CRAN (R 4.1.2)
GenomeInfoDb 1.30.1 2022-01-30 [2] Bioconductor
GenomeInfoDbData 1.2.7 2022-03-09 [2] Bioconductor
ggplot2 * 3.4.2 2023-04-03 [2] CRAN (R 4.1.2)
globals 0.16.2 2022-11-21 [2] CRAN (R 4.1.2)
glue 1.6.2 2022-02-24 [2] CRAN (R 4.1.2)
gower 1.0.1 2022-12-22 [2] CRAN (R 4.1.2)
gridExtra 2.3 2017-09-09 [2] CRAN (R 4.1.0)
gtable 0.3.3 2023-03-21 [2] CRAN (R 4.1.2)
hardhat 1.3.0 2023-03-30 [2] CRAN (R 4.1.2)
Hmisc * 5.1-0 2023-05-08 [2] CRAN (R 4.1.2)
htmlTable 2.4.1 2022-07-07 [2] CRAN (R 4.1.2)
htmltools 0.5.5 2023-03-23 [2] CRAN (R 4.1.2)
htmlwidgets 1.6.2 2023-03-17 [2] CRAN (R 4.1.2)
httpuv 1.6.11 2023-05-11 [2] CRAN (R 4.1.3)
igraph 1.5.0 2023-06-16 [1] CRAN (R 4.1.3)
ipred 0.9-14 2023-03-09 [2] CRAN (R 4.1.2)
IRanges 2.28.0 2021-10-26 [2] Bioconductor
iterators 1.0.14 2022-02-05 [2] CRAN (R 4.1.2)
jquerylib 0.1.4 2021-04-26 [2] CRAN (R 4.1.0)
jsonlite 1.8.7 2023-06-29 [2] CRAN (R 4.1.3)
knitr 1.43 2023-05-25 [2] CRAN (R 4.1.3)
labeling 0.4.2 2020-10-20 [2] CRAN (R 4.1.0)
later 1.3.1 2023-05-02 [2] CRAN (R 4.1.2)
lattice * 0.21-8 2023-04-05 [2] CRAN (R 4.1.2)
lava 1.7.2.1 2023-02-27 [2] CRAN (R 4.1.2)
lifecycle 1.0.3 2022-10-07 [2] CRAN (R 4.1.2)
listenv 0.9.0 2022-12-16 [2] CRAN (R 4.1.2)
lubridate 1.9.2 2023-02-10 [2] CRAN (R 4.1.2)
magrittr 2.0.3 2022-03-30 [2] CRAN (R 4.1.2)
MASS 7.3-60 2023-05-04 [2] CRAN (R 4.1.2)
Matrix 1.6-0 2023-07-08 [2] CRAN (R 4.1.3)
MatrixModels 0.5-2 2023-07-10 [2] CRAN (R 4.1.3)
memoise 2.0.1 2021-11-26 [2] CRAN (R 4.1.0)
mgcv 1.8-42 2023-03-02 [2] CRAN (R 4.1.2)
mime 0.12 2021-09-28 [2] CRAN (R 4.1.0)
miniUI 0.1.1.1 2018-05-18 [2] CRAN (R 4.1.0)
ModelMetrics 1.2.2.2 2020-03-17 [2] CRAN (R 4.1.0)
multcomp 1.4-25 2023-06-20 [2] CRAN (R 4.1.3)
multtest 2.50.0 2021-10-26 [2] Bioconductor
munsell 0.5.0 2018-06-12 [2] CRAN (R 4.1.0)
mvtnorm 1.2-2 2023-06-08 [2] CRAN (R 4.1.3)
nlme 3.1-162 2023-01-31 [2] CRAN (R 4.1.2)
nnet 7.3-19 2023-05-03 [2] CRAN (R 4.1.2)
parallelly 1.36.0 2023-05-26 [2] CRAN (R 4.1.3)
permute 0.9-7 2022-01-27 [2] CRAN (R 4.1.2)
phyloseq 1.38.0 2021-10-26 [2] Bioconductor
pillar 1.9.0 2023-03-22 [2] CRAN (R 4.1.2)
pkgbuild 1.4.2 2023-06-26 [2] CRAN (R 4.1.3)
pkgconfig 2.0.3 2019-09-22 [2] CRAN (R 4.1.0)
pkgload 1.3.2.1 2023-07-08 [2] CRAN (R 4.1.3)
plyr 1.8.8 2022-11-11 [2] CRAN (R 4.1.2)
polspline 1.1.23 2023-06-29 [1] CRAN (R 4.1.3)
prettyunits 1.1.1 2020-01-24 [2] CRAN (R 4.1.0)
pROC * 1.18.4 2023-07-06 [2] CRAN (R 4.1.3)
processx 3.8.2 2023-06-30 [2] CRAN (R 4.1.3)
prodlim 2023.03.31 2023-04-02 [2] CRAN (R 4.1.2)
profvis 0.3.8 2023-05-02 [2] CRAN (R 4.1.2)
promises 1.2.0.1 2021-02-11 [2] CRAN (R 4.1.0)
proxy 0.4-27 2022-06-09 [2] CRAN (R 4.1.2)
ps 1.7.5 2023-04-18 [2] CRAN (R 4.1.2)
purrr 1.0.1 2023-01-10 [2] CRAN (R 4.1.2)
quantreg 5.95 2023-04-08 [2] CRAN (R 4.1.2)
R6 2.5.1 2021-08-19 [2] CRAN (R 4.1.0)
randomForest * 4.7-1.1 2022-05-23 [2] CRAN (R 4.1.2)
Rcpp 1.0.11 2023-07-06 [1] CRAN (R 4.1.3)
RCurl 1.98-1.12 2023-03-27 [2] CRAN (R 4.1.2)
recipes 1.0.6 2023-04-25 [2] CRAN (R 4.1.2)
remotes 2.4.2 2021-11-30 [2] CRAN (R 4.1.0)
reshape2 1.4.4 2020-04-09 [2] CRAN (R 4.1.0)
rhdf5 2.38.1 2022-03-10 [2] Bioconductor
rhdf5filters 1.6.0 2021-10-26 [2] Bioconductor
Rhdf5lib 1.16.0 2021-10-26 [2] Bioconductor
rlang 1.1.1 2023-04-28 [2] CRAN (R 4.1.2)
rmarkdown 2.23 2023-07-01 [2] CRAN (R 4.1.3)
rms * 6.7-0 2023-05-08 [1] CRAN (R 4.1.2)
rpart 4.1.19 2022-10-21 [2] CRAN (R 4.1.2)
rstudioapi 0.15.0 2023-07-07 [2] CRAN (R 4.1.3)
S4Vectors 0.32.4 2022-03-29 [2] Bioconductor
sandwich 3.0-2 2022-06-15 [2] CRAN (R 4.1.2)
sass 0.4.6 2023-05-03 [2] CRAN (R 4.1.2)
scales 1.2.1 2022-08-20 [2] CRAN (R 4.1.2)
sessioninfo 1.2.2 2021-12-06 [2] CRAN (R 4.1.0)
shiny 1.7.4.1 2023-07-06 [2] CRAN (R 4.1.3)
SparseM 1.81 2021-02-18 [2] CRAN (R 4.1.0)
stringi 1.7.12 2023-01-11 [2] CRAN (R 4.1.2)
stringr 1.5.0 2022-12-02 [2] CRAN (R 4.1.2)
survival 3.5-5 2023-03-12 [2] CRAN (R 4.1.2)
TH.data 1.1-2 2023-04-17 [2] CRAN (R 4.1.2)
tibble * 3.2.1 2023-03-20 [2] CRAN (R 4.1.2)
tidyselect 1.2.0 2022-10-10 [2] CRAN (R 4.1.2)
timechange 0.2.0 2023-01-11 [2] CRAN (R 4.1.2)
timeDate 4022.108 2023-01-07 [2] CRAN (R 4.1.2)
urlchecker 1.0.1 2021-11-30 [2] CRAN (R 4.1.0)
usethis 2.2.2 2023-07-06 [2] CRAN (R 4.1.3)
utf8 1.2.3 2023-01-31 [2] CRAN (R 4.1.2)
vctrs 0.6.3 2023-06-14 [1] CRAN (R 4.1.3)
vegan 2.6-4 2022-10-11 [2] CRAN (R 4.1.2)
withr 2.5.0 2022-03-03 [2] CRAN (R 4.1.2)
xfun 0.39 2023-04-20 [2] CRAN (R 4.1.2)
xtable 1.8-4 2019-04-21 [2] CRAN (R 4.1.0)
XVector 0.34.0 2021-10-26 [2] Bioconductor
yaml 2.3.7 2023-01-23 [2] CRAN (R 4.1.2)
zlibbioc 1.40.0 2021-10-26 [2] Bioconductor
zoo 1.8-12 2023-04-13 [2] CRAN (R 4.1.2)
[1] /Users/zouhua/Library/R/x86_64/4.1/library
[2] /Library/Frameworks/R.framework/Versions/4.1/Resources/library
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
















 1920
1920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











