






大佬们,安装flash attention后,我用代码检测我的版本号:
import flash_attn
print(flash_attn.__version__) # 查看 Flash Attention 的版本结果为:
2.7.0.post2安装包是大佬发布的:Releases · bdashore3/flash-attention
我的cuda,torch,Python的型号分别为:
cuda = 12.4
torch= 2.5.1
python = 3.12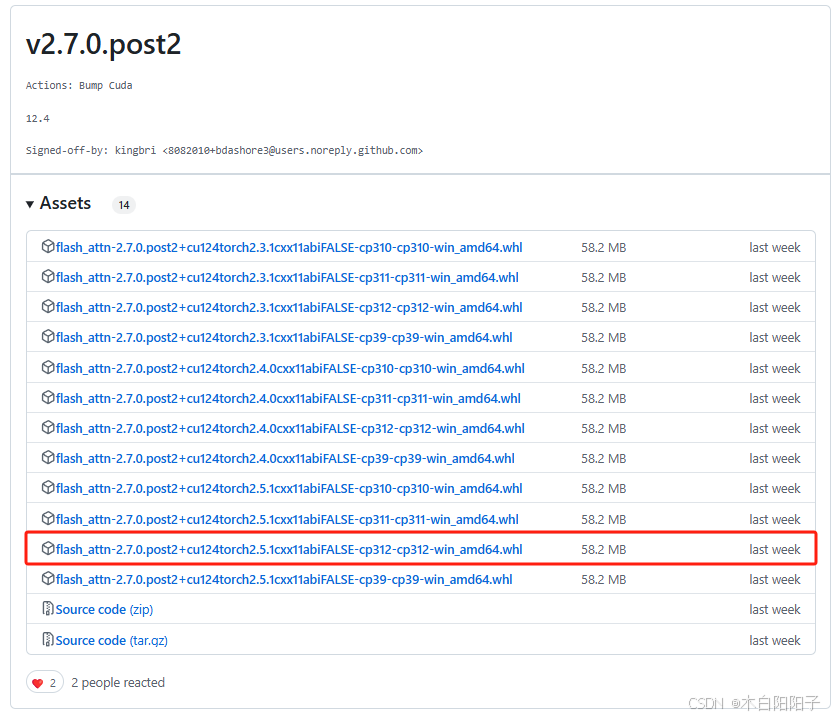
安装的红框里面的whl文件,参考的是这一篇文章:Windows系统安装flash-attn速度非常慢解决方法_flash-attn windows-CSDN博客
现在也不知道为什么,就还是报警:
D:\Worksoftware\Anaconda3\envs\py312_CUDA12_pytorch241\Lib\site-packages\torch\nn\functional.py:5560: UserWarning: 1Torch was not compiled with flash attention. (Triggered internally at C:\cb\pytorch_1000000000000\work\aten\src\ATen\native\transformers\cuda\sdp_utils.cpp:555.)
attn_output = scaled_dot_product_attention(q, k, v, attn_mask, dropout_p, is_causal)求助一下,孩子要被这个transformer计算速度折磨到崩溃了

















 2541
2541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









