






建议看完再动手,要不还要重新装一下
一:原来的安装方法,但是显示安装的是cpu版本的torch
1.下载代码
2.创建YOLOv12的环境
conda create -name yolov12 python=3.113.安装requirements,注释掉第三行
flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
pip install -r requirements.txt4.因为是Windows系统,需要下载:windows版FlashAttention
下载地址:https://github.com/kingbri1/flash-attention/releases
需要知道Cuda、Pytorch、python版本
下载后放在YOLOv12的根目录下
cuda版本,打开cmd,命令行输入nvidia-smi 我的是12.2
打开requirements,显示torch 2.2.2 所以我的pytorch是2.2.2
python我安装的是3.11
所以下载这个
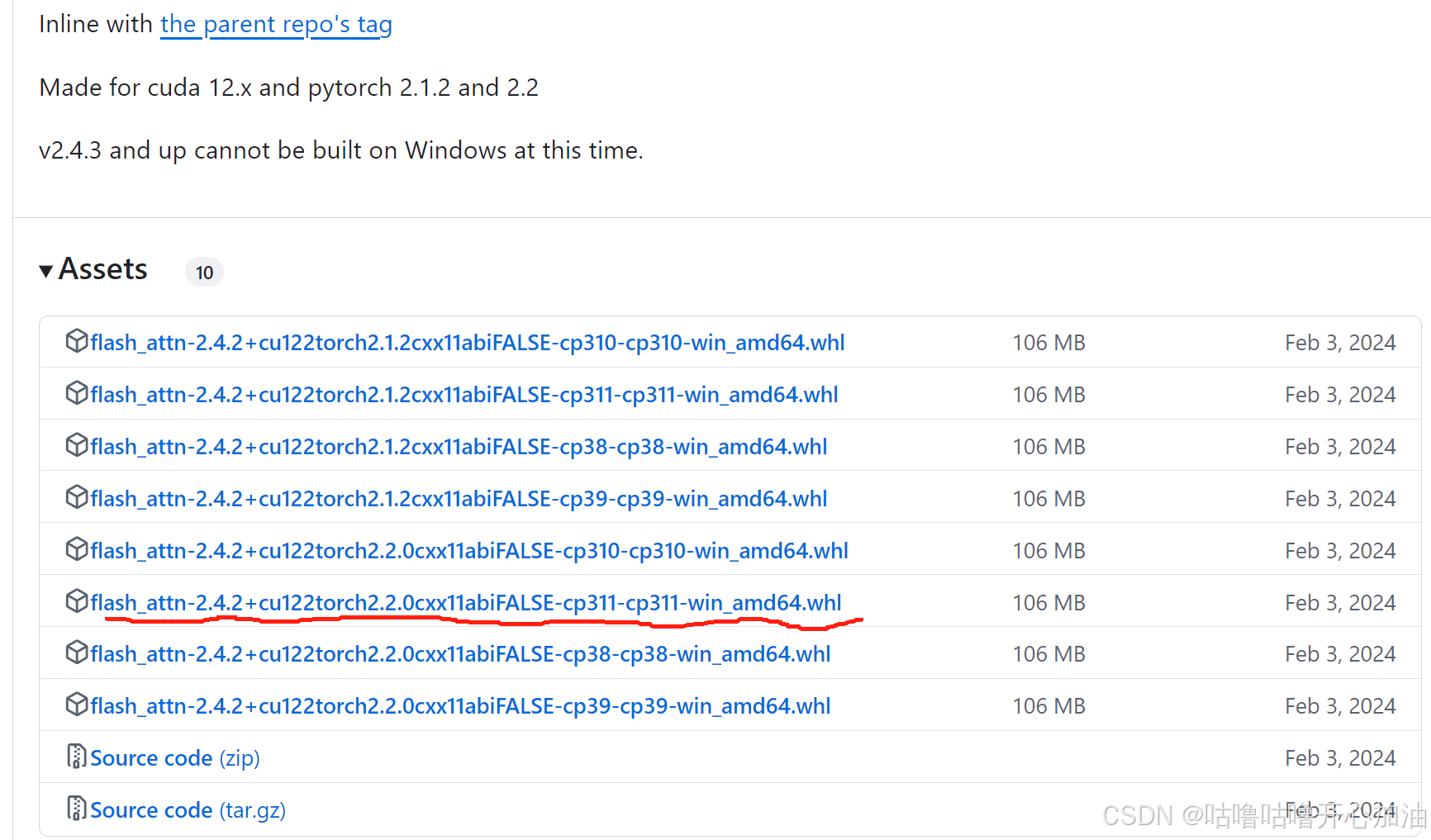
安装完成后,安装flash_attn,后面的名字按照自己的修改
pip install flash_attn-2.3.3+cu122-cp31-cp311-win_amd64.whl5.开发环境中安装 Python 包的命令,用于开发和调试阶段
pip install -e .剩下就可以在准备自己的数据集开始训练啦
参考:
https://blog.csdn.net/heart_warmonger/article/details/145726360
https://blog.csdn.net/r502818330/article/details/138783932
https://blog.csdn.net/heart_warmonger/article/details/145726360
二:安装GPU版本的pytorch
删除掉刚刚安装的环境
1.创建yolov12的环境
conda create -name yolov12 python=3.112.进入yolov12的环境,去pytorch官网找2.2.2版本的pytorch(或者找你相应的版本)
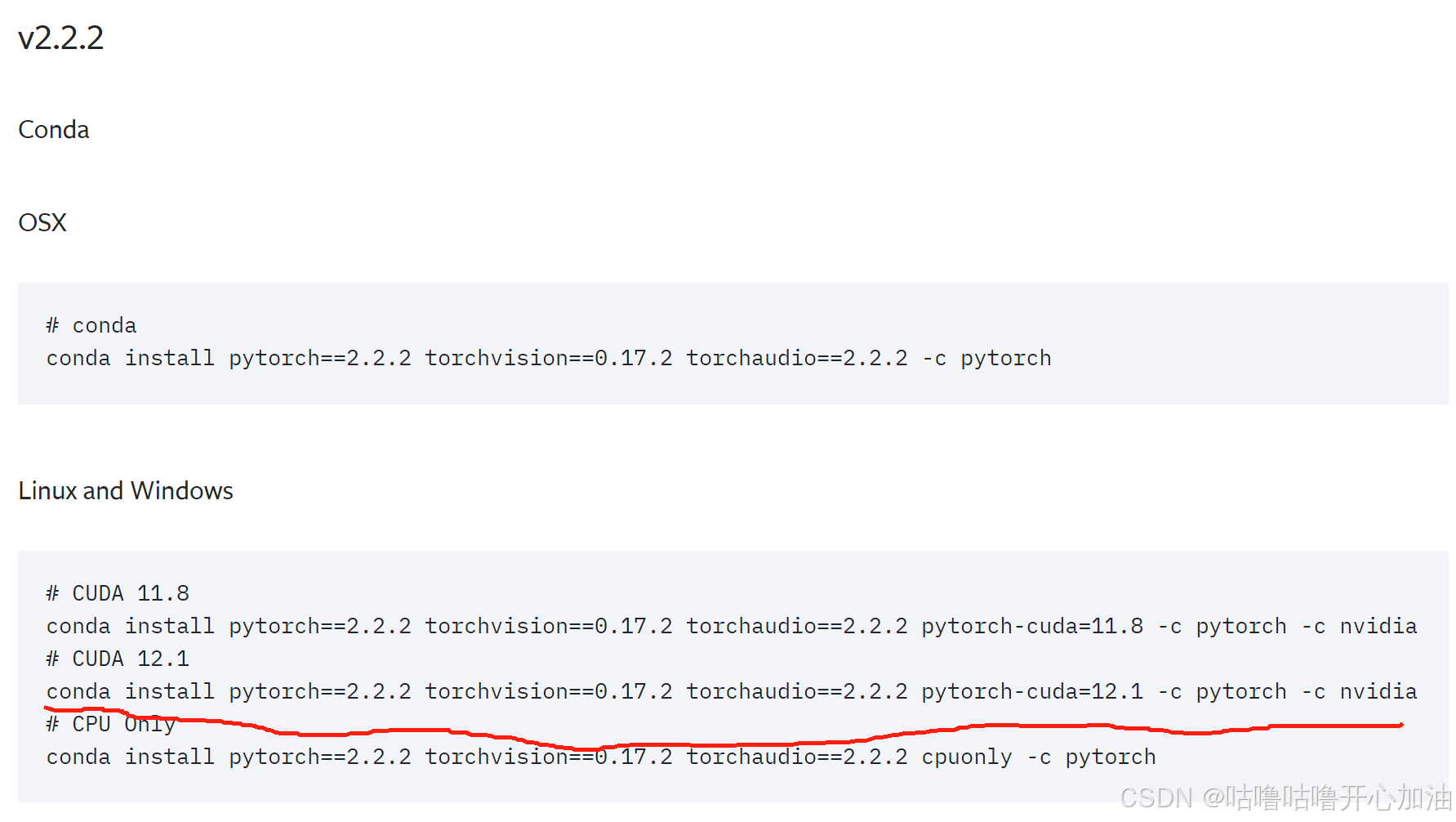
我选择的是这个,进入你创建的环境中,下载这个
3.打开yolov12文件,删除之前的解释器,打开刚刚配置的新的。
打开解释器设置,配置新的环境,也可以将原来的环境删掉
4.requirements的第一行和第二行torch和torchvision删掉,安装requirements
打开终端,找到Command Prompt,相当于 anaconda版的cmd 命令提示窗
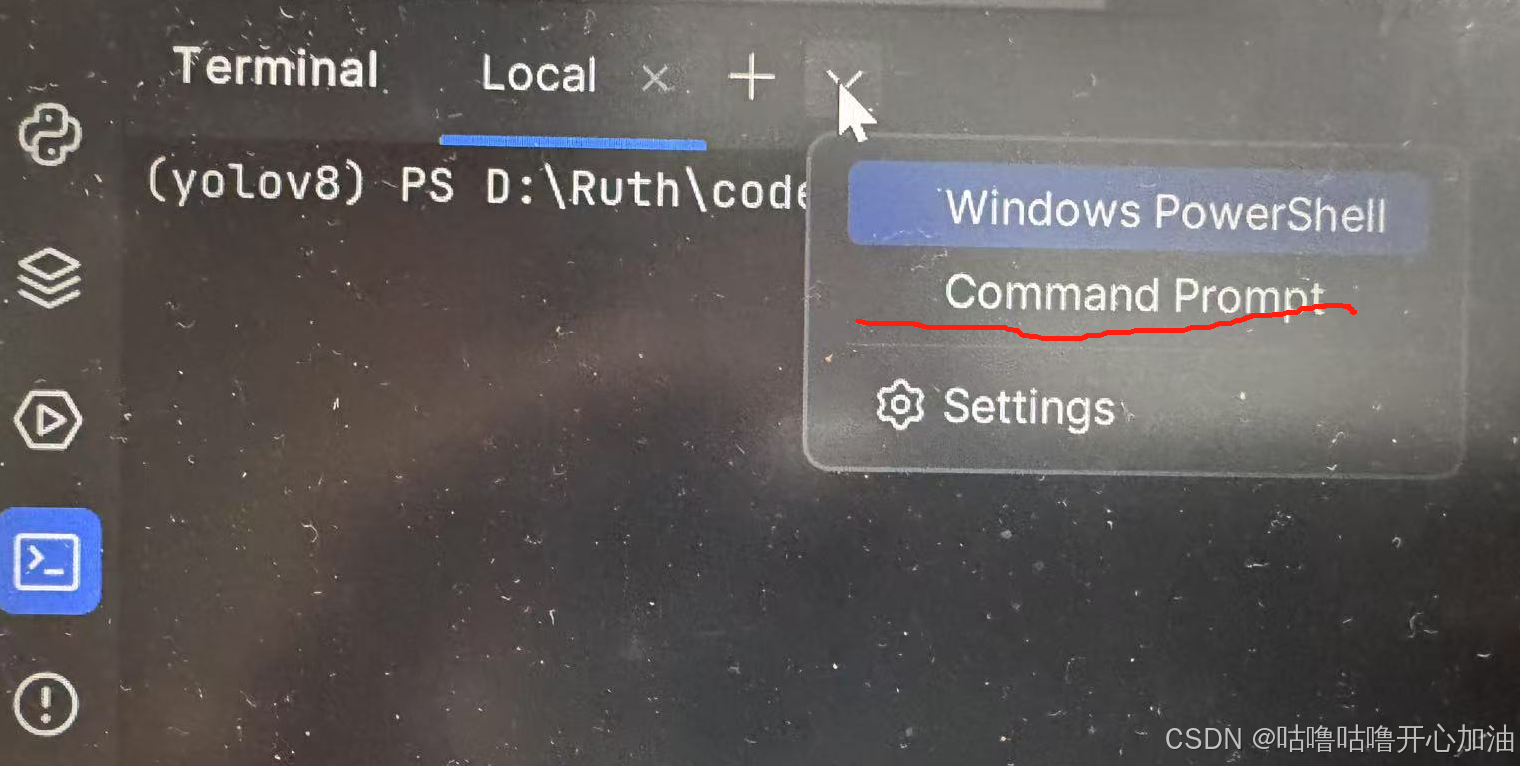
pip install -r requirements.txt5.安装flash_attn和开发环境中安装 Python 包的命令
pip install flash_attn-2.3.3+cu122-cp31-cp311-win_amd64.whlpip install -e .ok,可以正常运行啦
三:虽然跑起来了,但是出现了FlashAttention is not available on this device. Using scaled_dot_product_attention instead.
大概查了一下,感觉版本的问题,现在在下载pytorch的时候,cuda选择的是12.1,而之前下载的attn的cuda是12.2版本的,所以重新下载了一下,因为看到了可兼容性,而python版本是3.11,所以下载的这个
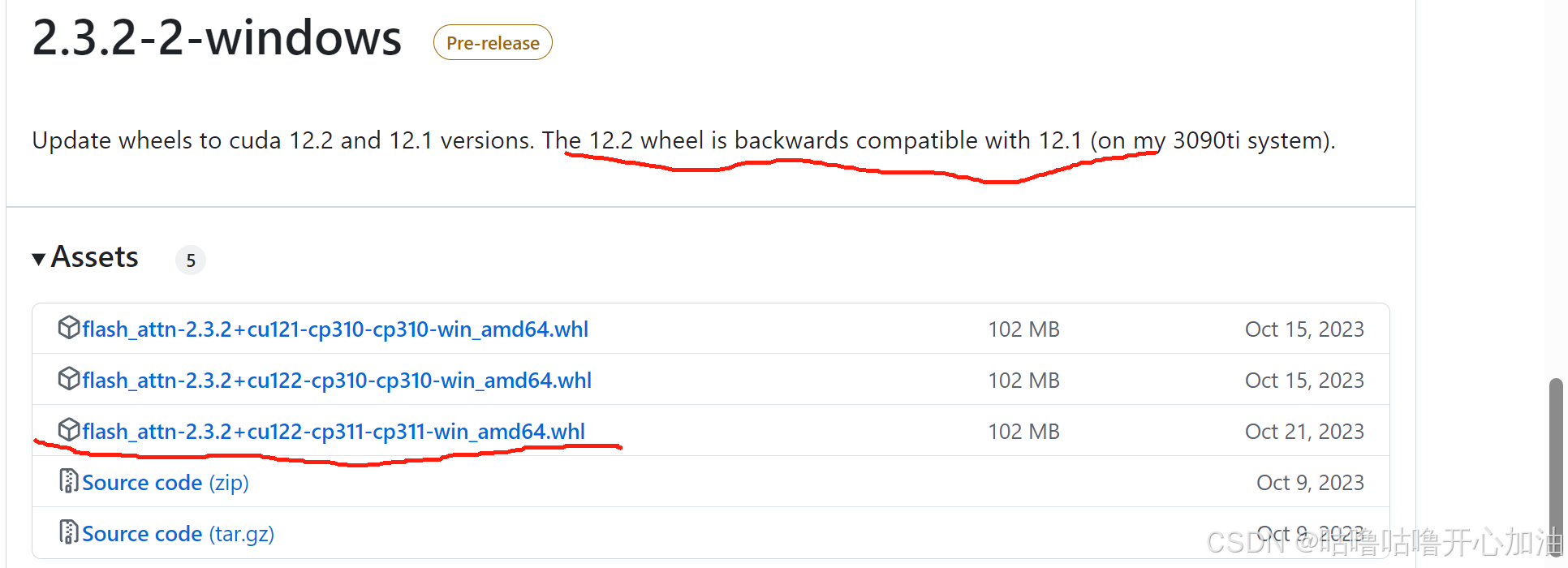 重新下载一下,还是不行。
重新下载一下,还是不行。
最后查了一下他们是干什么用的。
FlashAttention:这是一种高效的注意力机制实现,它通过优化内存访问和计算过程,显著提升了注意力计算的速度和效率,尤其在处理长序列数据时优势明显。很多深度学习模型(包括目标检测领域的 YOLO 系列)会利用它来加速训练和推理过程。
FlashAttention is not available on this device:表明当前使用的设备(通常是 GPU)不支持 FlashAttention。这可能是因为 GPU 的硬件版本不满足要求、CUDA 版本不兼容或者缺少必要的依赖库等原因
Using scaled_dot_product_attention instead:由于无法使用 FlashAttention,程序会自动切换到 scaled_dot_product_attention 这种标准的点积注意力计算方式。虽然 scaled_dot_product_attention 是一种通用的注意力计算方法,但相比 FlashAttention,其性能和效率可能会有所下降。
检查了一下自己的GPU是是2080基于Turing 架构,并非 Ampere 或更高架构,因此它不满足 FlashAttention 对 GPU 架构的要求。
四:确定batch和workers
https://blog.csdn.net/flamebox/article/details/123011129
1 batch
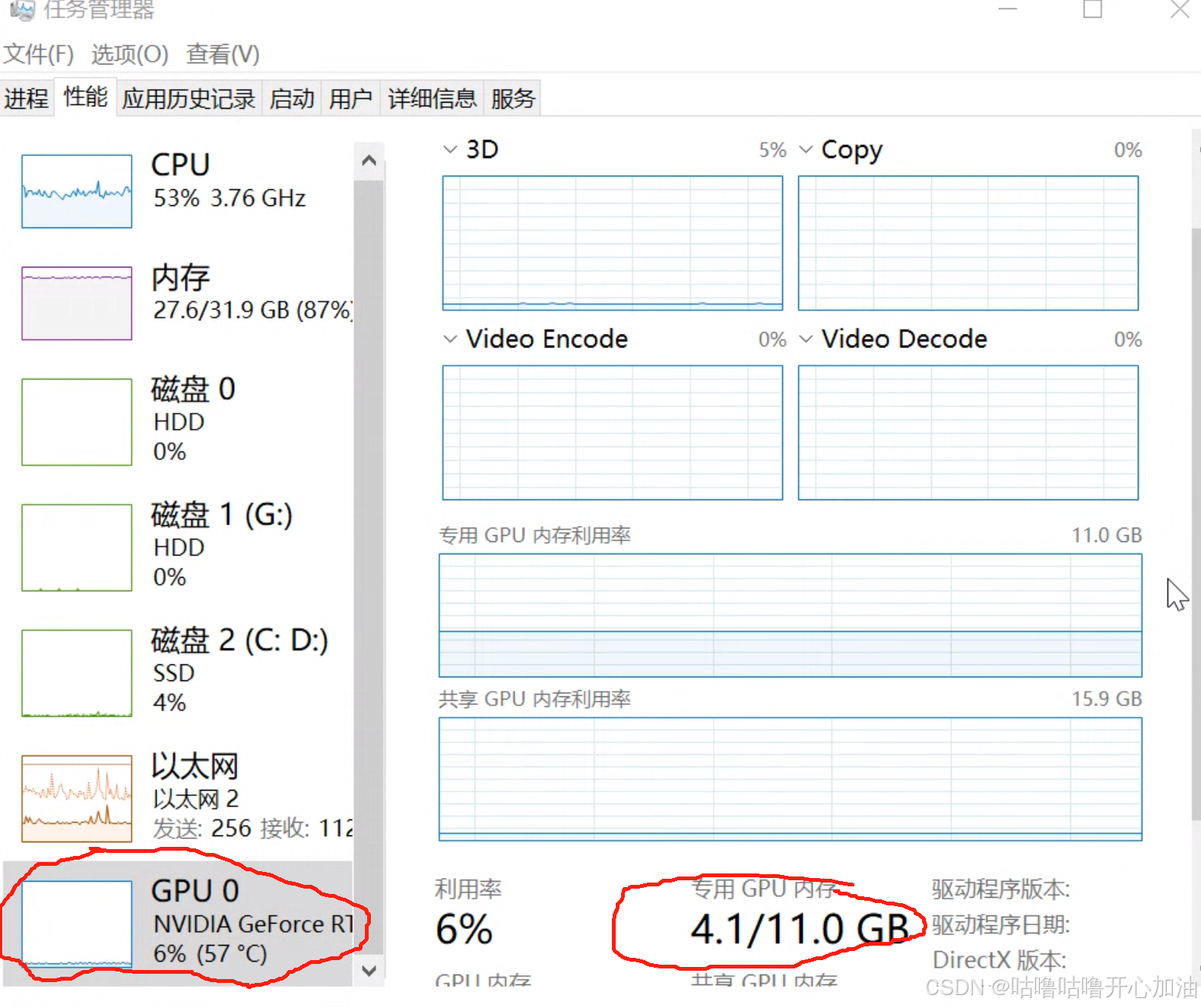
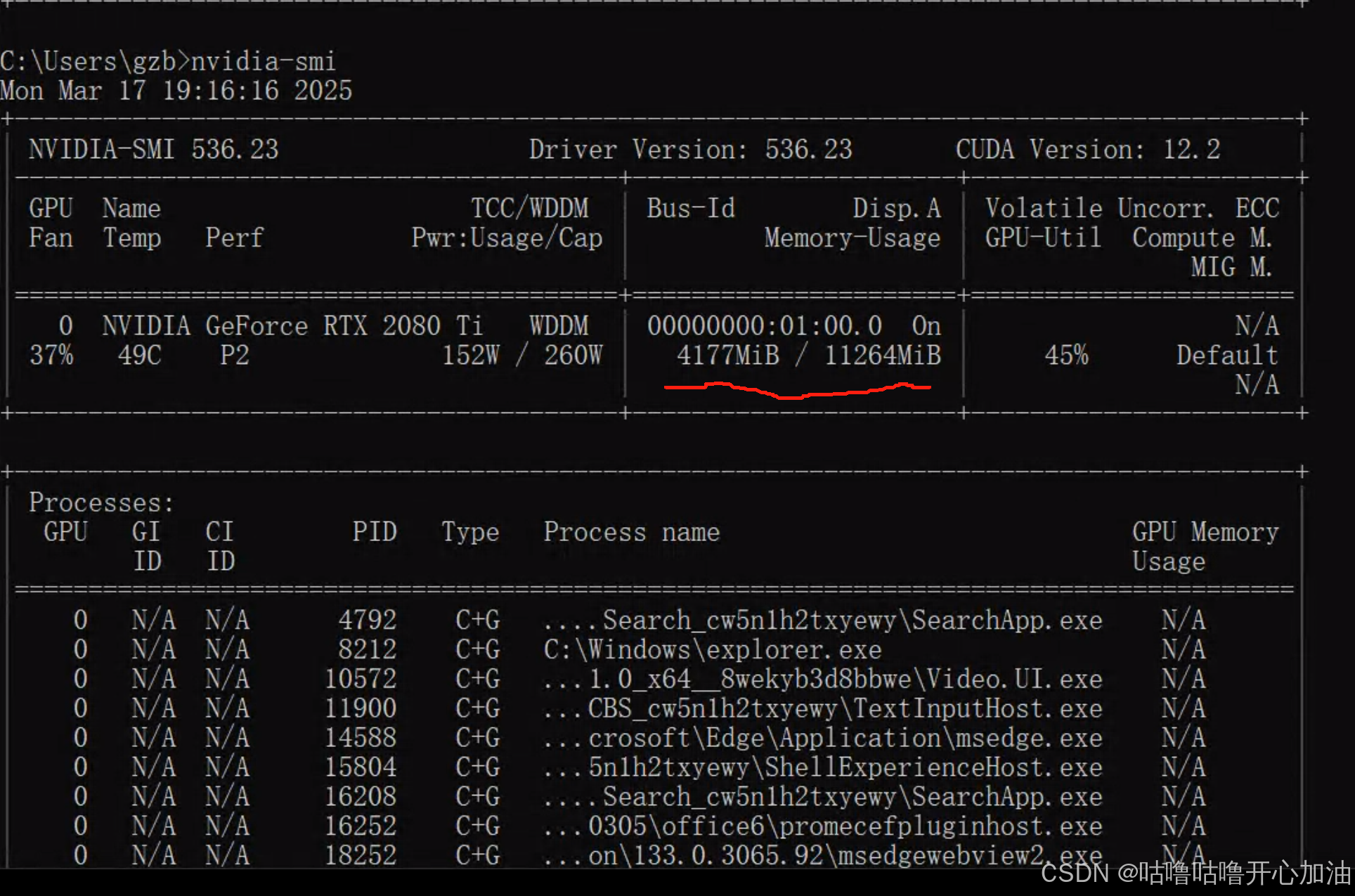
内存和显存的区别
- 功能
- 内存:用于存储计算机系统运行时的程序代码、数据以及操作系统等。它是 CPU 与外部存储设备(如硬盘、固态硬盘)之间的桥梁,CPU 需要处理的数据先从外部存储设备加载到内存,然后 CPU 再从内存中读取数据进行处理,处理后的数据也会先暂存于内存,最后再根据需要写回外部存储设备。
- 显存:专门为显卡设计,用于存储显卡处理图形数据和图像信息,包括纹理、顶点数据、帧缓冲等。显卡在渲染图像时,会从显存中读取数据进行处理,然后将处理后的结果输出到显示器上显示。
- 性能
- 内存:内存的读写速度相对较慢,但容量较大,一般常见的计算机内存容量有 8GB、16GB、32GB 甚至更高。它主要是为了满足计算机系统整体运行对数据存储和访问的需求,需要与 CPU、硬盘等其他组件协同工作。
- 显存:显存的读写速度非常快,能够满足显卡对图形数据的高速处理和传输要求。不过,显存的容量通常相对较小,常见的有 2GB、4GB、8GB、16GB 等,这是因为显卡在处理图形数据时,需要快速访问数据,所以对速度要求极高,而容量则根据不同的显卡应用场景和性能定位来确定。
2 workers
workers 的数量可以参考 CPU 的核心数。通常可以设置为 CPU 核心数的一半到全部,例如,如果你的 CPU 是 8 核的,那么
workers 可以设置为 4 - 8 之间。然后我自己的是6-12,所以我按照6-8-10-12分别尝试,同时计算第二个epoch的时间,谁最快用谁喽
CPU 的逻辑核数和核心数是不同的概念,主要区别如下:
- 核心数:指的是物理上独立的处理单元,是 CPU 中真正执行指令和进行数据处理的硬件部分。每个核心都有自己独立的运算单元、缓存等,可以独立执行任务。例如,一颗 4 核心的 CPU,就有 4 个物理上相互独立的核心来并行处理数据,核心数越多,理论上能同时处理的任务就越多,计算能力也就越强。
- 逻辑核数:是通过超线程技术(Hyper - Threading Technology)虚拟出来的核心。超线程技术允许每个物理核心同时运行两个或多个线程,使得操作系统和软件看起来好像有更多的核心可用。比如,一颗具有 4 核心且支持超线程技术的 CPU,通过超线程技术可以模拟出 8 个逻辑核心。这样在处理多任务时,每个物理核心可以在不同线程之间快速切换,提高 CPU 资源的利用率,但这种切换会带来一定的性能开销,所以逻辑核心的实际性能通常低于物理核心。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









