






必做题:
- 数据准备:数据集包含100个文件,每个文件里面有多个从维基百科上爬取的内容,每一条以字典形式保存,分为id,url,title,text四个字段,使用text字段的文本训练词向量。
- 读取‘text’字段的文本,并使用jieba进行分词。
- 使用Gensim工具训练词向量,训练方法为Skip-gram,向量维度为100,上下文窗口大小为5,使用负采样方式训练模型。
- 训练完成以后输出词频排名前十的单词向量,并根据训练的词向量找出以下单词最相近的5个单词:“经济”、“铁路”、“科技”、“生活”。 要给出每一部分的代码。
代码
import jieba
import os
from gensim.models import Word2Vec
# 数据准备
data_directory = 'C:\\Users\\hp\\Desktop\\实验4\\实验4数据' # 替换为包含100个文件的目录
sentences = []
# 读取文件并进行分词
for file_name in os.listdir(data_directory):
with open(os.path.join(data_directory, file_name), 'r', encoding='utf-8') as file:
data = file.readlines()
for item in data:
text = eval(item)['text']
words = jieba.lcut(text)
sentences.append(words)
# 使用jieba进行分词
segmented_texts = [' '.join(words) for words in sentences]
# 训练词向量
model = Word2Vec(sentences, sg=1, vector_size=100, window=5, negative=5)
# 输出词频排名前十的单词向量
word_frequencies = model.wv.index_to_key[:10]
print("词频排名前十的单词向量:")
for word in word_frequencies:
print(word, model.wv[word])
# 找出最相近的单词
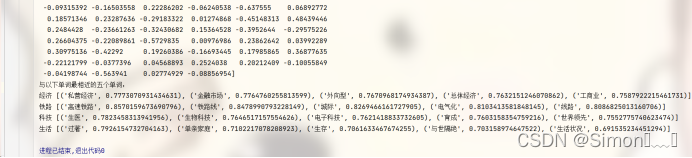
similar_words = ["经济", "铁路", "科技", "生活"]
print("与以下单词最相近的五个单词:")
for word in similar_words:
print(word, model.wv.most_similar(word, topn=5)) 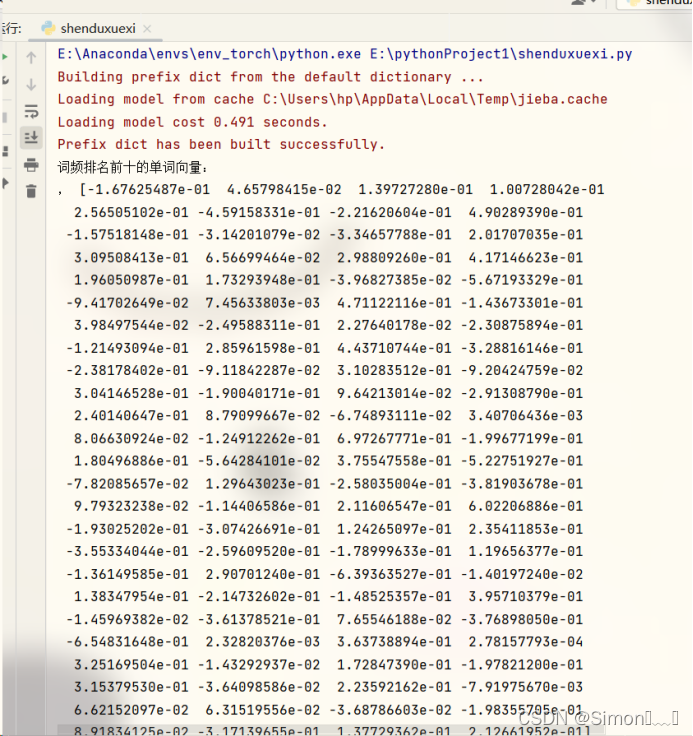
















 1263
1263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









