






RFM模型
为了进行精细化运营,可以利用RFM模型对用户价值指数(衡量历史到当前用户贡献的收益)进行计算,其中:
R:(Recency,最近一次消费),R值越大,表示客户交易发生的日期越久,反之则交易发生的日期越近
F:(Frequency,消费频率),F值越大,表示客户交易越频繁,反之则表示客户交易不够活跃(此处选择购买产品数量作F)
M:(Monetary,消费金额),M值越大,表示客户价值越高,反之则表示客户价值越低。
pivot_table()函数创建透视表
Python的透视函数——pivot_table()。
pd.pivot_table(index=[],columns = [], values = [], aggfunc = [])
其中,index指的是分组的时候选择哪个字段作为索引,columns指的是指定的列名是什么,values可以决定保留哪些属性字段,aggfunc决定对每个字段执行的函数,默认sum。
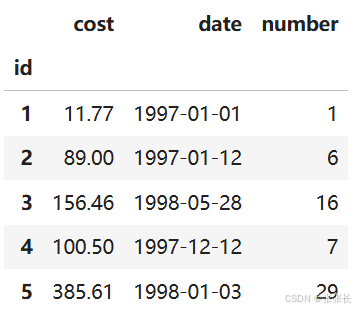
接着,我们对用户消费数据采用pivot_table()函数。主要想得到:每个订单('id')最近的一次消费时间,总消费金额(‘cost’),总消费次数(‘number’)。
rfm = data.pivot_table(index = 'id',
values = ['number', 'cost', 'date'],
aggfunc = {'date':'max', 'number':'sum', 'cost':'sum'})
## 消费产品数 消费总金额 最近一次消费时间
rfm.head()查看rfm中的数据:
接着,我们将其转化为对应的R,F,M数据:
其实,我们想要的F,M数据已经得到了,只需要给它们改个名字就可以。
但是,R——消费频率的数据还没有得到,我们以最后一次消费时间作为当前时间,统计用户(‘id’)最后一次的购买时间距当前时间所隔的天数,天数越小,说明用户的消费越频繁。
rfm["R"] = -(rfm.date-rfm.date.max())/np.timedelta64(1, 'D') # 取相差的天数,保留一位小数
rfm.rename(columns = {'number':'F', 'cost':'M'},inplace = True)
print(rfm)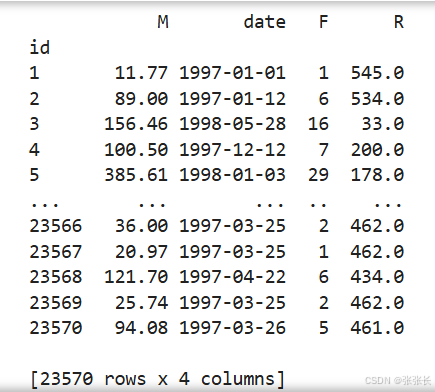
用户分层
将已有的R,F,M数据转化为0/1数据,为每个类似于‘001’的数据打上相应的、合理的标签,即完成了对用户的分层。
print(rfm[['R', 'F', 'M']].apply(lambda x:x - x.mean())) # 每个数据与均值作比较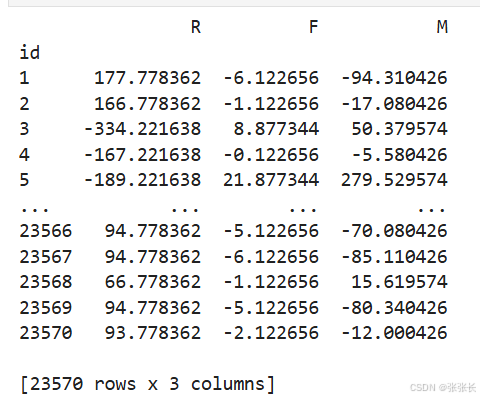
我们假设每个数若为正数,给它对应成‘1’,否则为‘0’。
def aggfc(k):
level = k.apply(lambda x:'1' if x>0 else '0')
leable = level.R + level.M + level.F
d = {
'111':'重要价值客户',
'011':'重要保持客户',
'101':'重要挽留客户',
'001':'重要发展客户',
'110':'一般价值客户',
'010':'一般保持客户',
'100':'一般挽留客户',
'000':'一般发展客户',
}
result = d[leable]
return result
rfm['lable'] = rfm[['R', 'F', 'M']].apply(lambda x:x-x.mean()).apply(aggfc, axis = 1)
rfm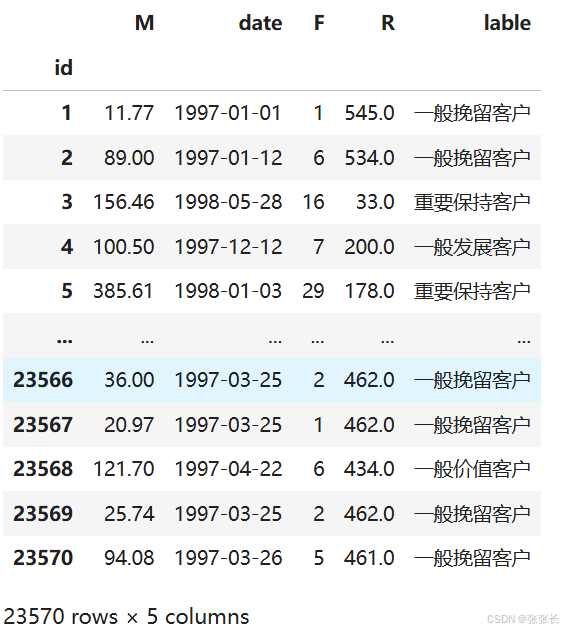
此时,就完成了对每个数据的分层。
分层数据可视化
# 客户分层可视化
rfm.loc[rfm.lable == '重要价值客户', 'color'] = 'g'
rfm.loc[~(rfm.lable == '重要价值客户'), 'color'] = 'r'
rfm.plot.scatter('F', 'R', c = rfm.color)
plt.show()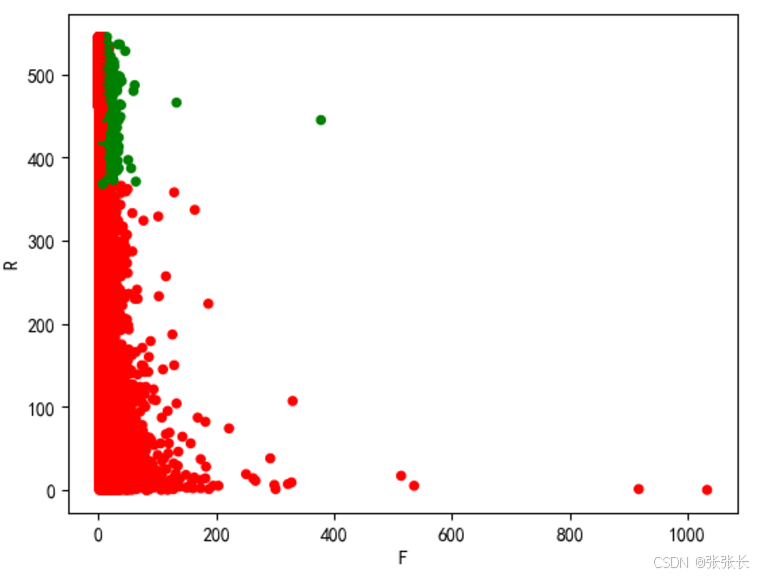

















 7192
7192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









