






一、DeepSeek质控能力矩阵

自然语言理解、知识图谱引擎、规则推理系统、联邦学习框架的组合体现了DeepSeek在智能质控中的多重优势。通过非结构化文本解析、诊疗逻辑验证、规则执行和多中心模型优化,不仅提升了数据处理效率,还能根据医院间数据的差异不断优化模型的泛化能力。
二、关键技术实现
1. 缺陷检测算法
通过实体识别(NER)、规则匹配和逻辑推理,DeepSeek能够自动检测病历中的各类缺陷,提高了诊疗过程的规范性和安全性。
def detect_defect(emr_text):
# 实体识别
entities = deepseek.ner(emr_text)
# 规则匹配
rule_violations = rule_engine.check(entities)
# 逻辑推理
logic_errors = knowledge_graph.validate(entities)
return rule_violations + logic_errors
2. 智能修正建议
系统能够生成详细的缺陷修正建议,并提供标准化的修正示例,这对医生的日常工作提供了极大的支持,有助于减少因书写不规范引发的医疗风险
{
"缺陷类型": "规范性缺陷",
"问题描述": "诊断名称不规范",
"错误示例": "肺部感染(非标准名称)",
"建议修正": "J18.901 肺炎",
"依据来源": "ICD-11编码规范2023版"
}
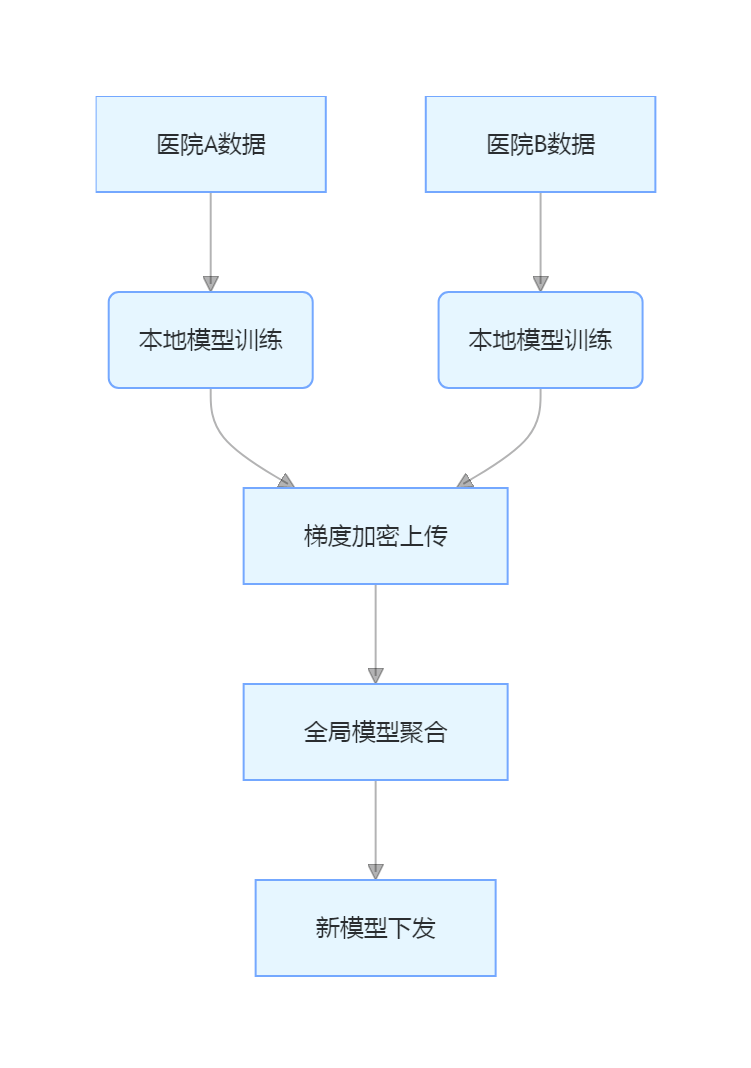
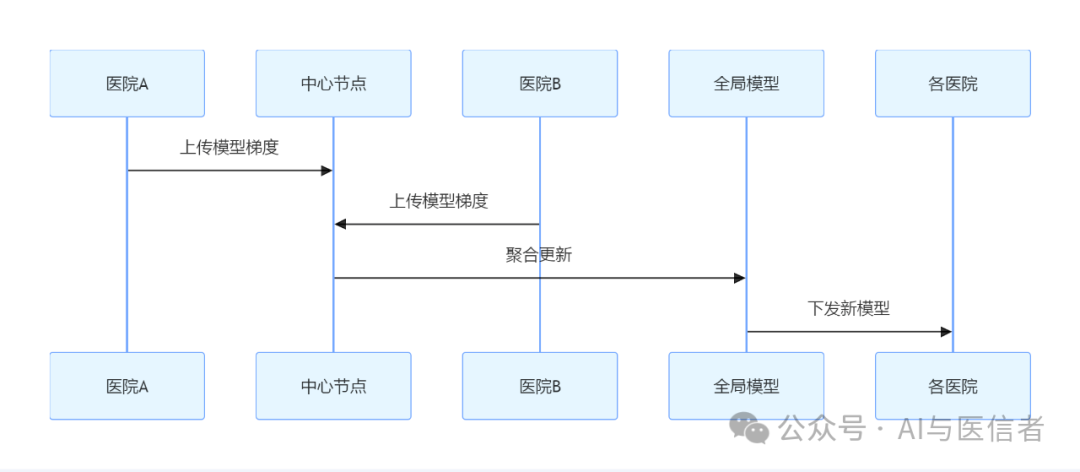
3. 联邦学习框架
这一机制能够在保护医院数据隐私的同时,提升模型的普适性和精准度。通过聚合各医院的数据梯度,持续优化全局模型,最终实现跨医院、跨区域的质控能力提升。
三、五层质控体系架构
1. 数据治理层
通过对病历数据的预处理(文本解析、信息抽取、标准化映射)和质量标记,确保系统输入的数据质量,为后续的智能分析打下基础。
# 病历数据预处理流程
def preprocess(emr_data):
# 非结构化文本解析
parsed = deepseek.nlp.parse(emr_data)
# 关键信息抽取
entities = deepseek.ner(parsed)
# 标准化映射
standardized = emr_mapper(entities)
# 质量标记
return quality_tagging(standardized)
2. 规则引擎层
-
三级规则体系:
通过三级规则体系,确保了对病历的完整性、规范性和逻辑性的全面把控。这个设计非常符合医疗行业对数据精准性的高要求。```
规则类型 检测维度 示例规则 完整性规则 必填项/时间节点 入院记录需包含主诉、现病史等8项 规范性规则 术语/格式标准 诊断名称必须使用ICD-11编码 逻辑性规则 诊疗路径合理性 手术记录与麻醉记录时间逻辑校验
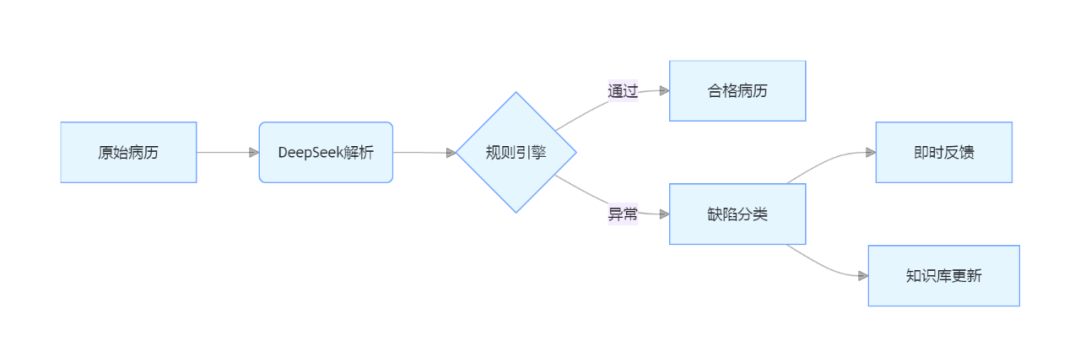
3. 智能分析层
通过DeepSeek解析病历数据并结合规则引擎和知识库进行深度分析,实时提供缺陷反馈,并且自动更新知识库,保证系统的智能性和自我进化能力。
4. 可视化层
通过图表和仪表盘等可视化手段,便于管理者和医生实时掌握质控情况,及时做出调整和改进。
{
tooltip: { trigger: 'item' },
series: [{
type: 'pie',
data: [
{ value: 68, name: '完整性缺陷' },
{ value: 23, name: '规范性缺陷' },
{ value: 9, name: '逻辑性缺陷' }
]
}]
}
5. 持续优化层
联邦学习机制能够实现医院之间的协同学习,逐步提升模型准确性,符合医疗领域的隐私保护要求。
- 联邦学习机制:
四、十二步实施路径
阶段1:需求准备(1-2个月)
-
质控标准梳理:整理医院现有质控规则3000+条
-
数据资产盘点:抽取3年历史病历建立训练集
-
标注系统搭建:开发病历缺陷标注工具
-
知识图谱构建:建立包含疾病-症状-药品关系的医学知识库
阶段2:系统建设(3-4个月)
-
规则数字化:将人工规则转化为可执行代码
-
模型训练:使用DeepSeek完成BERT+CRF模型训练
-
系统对接:与HIS/EMR系统集成(HL7标准接口)
-
沙盒测试:在测试环境完成千份病历验证
阶段3:部署优化(2-3个月)
-
试点运行:选择3个重点科室上线
-
人机对比:与人工质控结果进行一致性检验
-
流程再造:建立AI质控-医生修正-闭环管理机制
-
持续迭代:每月更新知识库和模型
五、关键成功要素
-
数据治理:建立标准化病历数据字典(覆盖300+字段)
-
医工协同:临床专家与AI工程师联合工作组
-
渐进策略:从基础规则到复杂逻辑分阶段实施
-
安全合规:通过等保三级认证+区块链存证
六、持续优化机制
-
月度迭代:```
- 新增10-15条临床路径规则
- 优化NER模型准确率(目标>98%)
- 更新医学知识图谱(新增500+节点)
-
年度升级:```
- 扩展质控范围(护理记录/知情同意书等)
- 对接DRG/DIP医保审核
- 构建区域质控联盟链
七、实施建议
该方案通过DeepSeek的NLP和知识推理能力,使电子病历质控实现:
-
从抽样到全量:100%病历实时质控
-
从人工到智能:缺陷发现准确率>95%
-
从事后到事前:医生书写时即时提醒
-
从孤立到协同:区域质控标准统一
建议医院优先实施基础规则质控(完整性/规范性),6个月后再拓展复杂逻辑校验,最终构建覆盖"书写-归档-应用"全流程的智能质控体系。
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 2449
2449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









