







 该文介绍了基于yolov8的道路缺陷识别系统,通过数据增强方法如medianBlur和GaussianBlur扩充了数据集,使用split_train_val.py和voc_label.py处理数据。文中提到加入WIOU、DCNV2、PConv以及MobileViTAttention等技术分别提升了模型的map值,显著提高了小目标检测性能。
该文介绍了基于yolov8的道路缺陷识别系统,通过数据增强方法如medianBlur和GaussianBlur扩充了数据集,使用split_train_val.py和voc_label.py处理数据。文中提到加入WIOU、DCNV2、PConv以及MobileViTAttention等技术分别提升了模型的map值,显著提高了小目标检测性能。
目录
1.1.1 通过split_train_val.py得到trainval.txt、val.txt、test.txt
1.1.2 通过voc_label.py得到适合yolov5训练需要的
🏆 🏆🏆🏆🏆🏆🏆Yolov8成长师🏆🏆🏆🏆🏆🏆🏆
🍉🍉进阶专栏Yolov8魔术师:http://t.csdn.cn/fUzZ7🍉🍉
✨✨✨魔改网络、复现前沿论文,组合优化创新
🚀🚀🚀小目标、遮挡物、难样本性能提升
🌰 🌰 🌰在不同数据集验证能够涨点,对小目标涨点明显
🍉🍉🍉🍉🍉🍉🍉🍉🍉🍉🍉🍉🍉🍉🍉🍉🍉🍉🍉🍉🍉🍉
1.数据集介绍
缺陷类型:crack
数据集数量:195张

1.1数据增强,扩充数据集
通过medianBlur、GaussianBlur、Blur3倍扩充得到780张图片
按照train、val、test进行8:1:1进行划分
1.1.1 通过split_train_val.py得到trainval.txt、val.txt、test.txt
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.9
train_percent = 0.8
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()1.1.2 通过voc_label.py得到适合yolov5训练需要的
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val']
classes = ["crack"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
#difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('labels/'):
os.makedirs('labels/')
image_ids = open('ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()2.基于yolov8的道路缺陷识别
2.1 实验结果
原始map为0.739
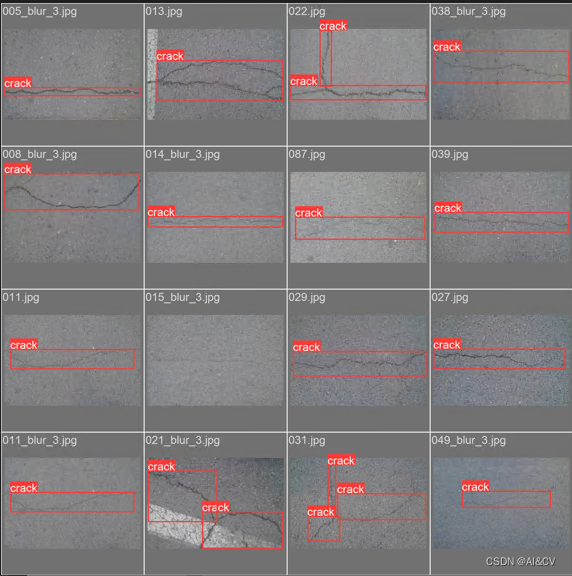
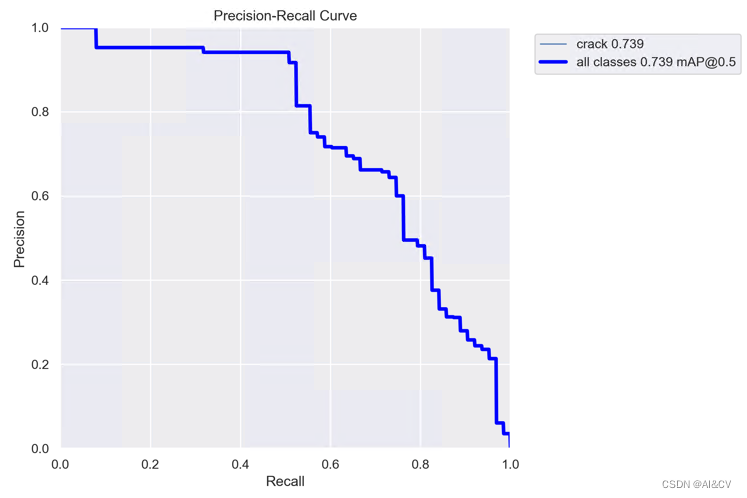 检测结果
检测结果
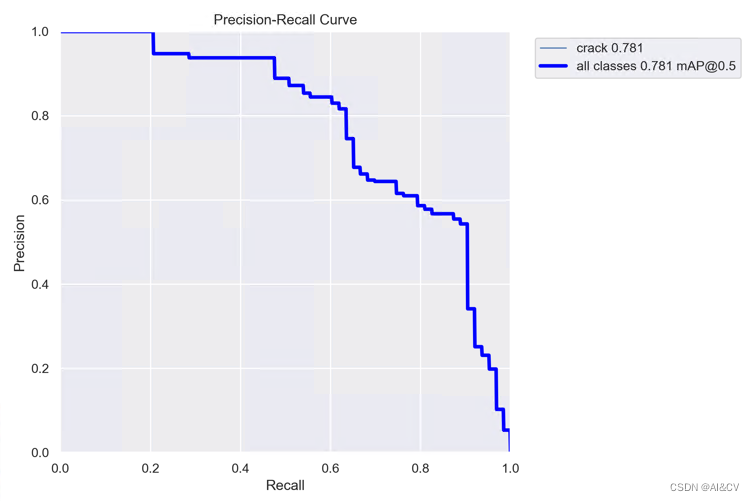
2.2 加入WIOU
https://cv2023.blog.csdn.net/article/details/130200951
map从0.739提升至0.781
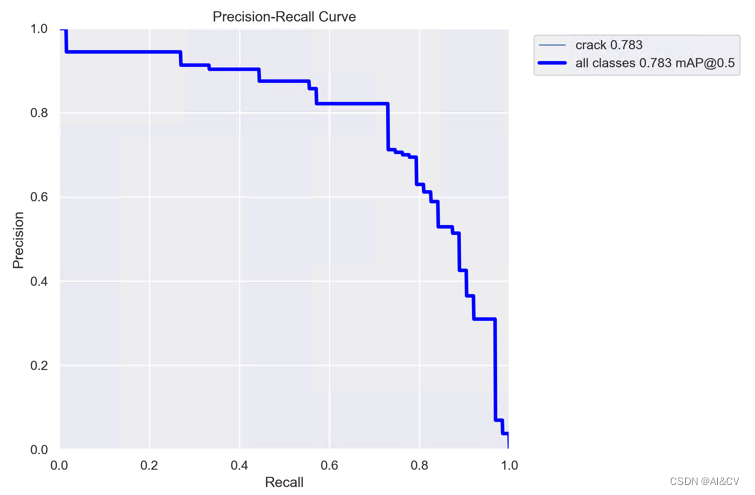
2.3 加入DCNV2
https://cv2023.blog.csdn.net/article/details/130215147
map从0.739提升至0.783
2.4 加入PConv
https://cv2023.blog.csdn.net/article/details/130225022
map从0.739提升至0.774
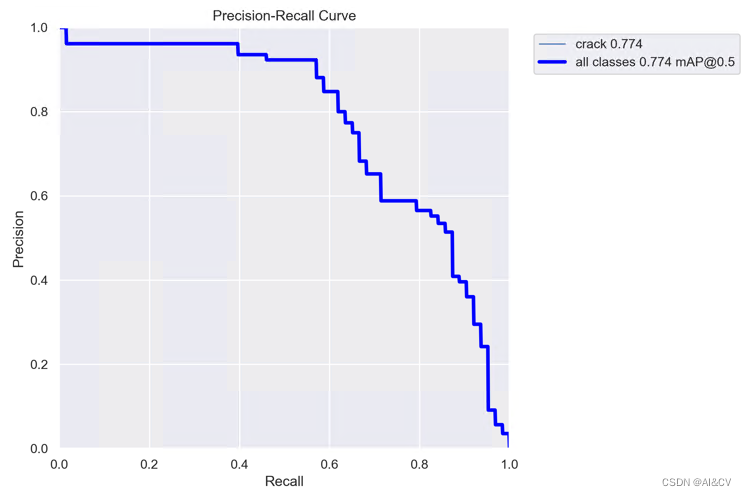
2.5 MobileViTAttention
Yolov8涨点技巧:MobileViTAttention助力小目标检测,涨点显著,MobileViT移动端轻量通用视觉transformer_AI小怪兽的博客-CSDN博客
原始0.739提升至 0.772 ,涨点明显
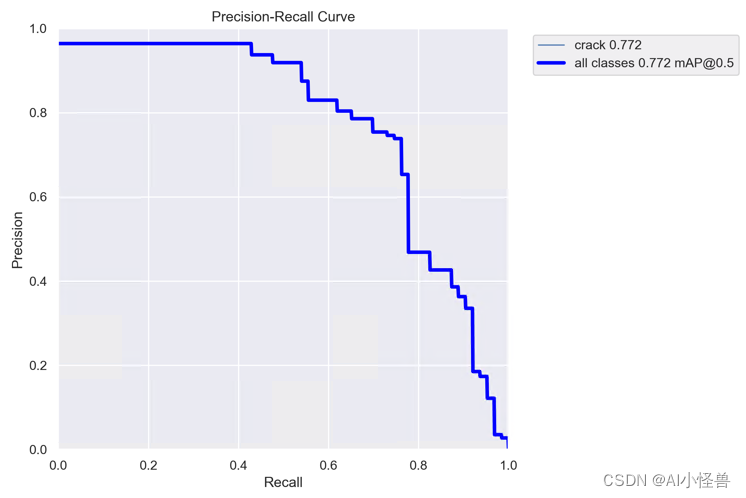



















 154
154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











