







 本文介绍了Shift-ConvNets如何通过移位操作使小卷积核达到大卷积核的效果,提升YOLOv8模型的性能。Shift-ConvNets解决了大卷积核带来的计算成本和兼容性问题,实现在稀疏机制下捕获远程依赖关系,同时保持硬件友好。手把手教程涵盖了将Shift-Conv整合到YOLOv8-pose的步骤。
本文介绍了Shift-ConvNets如何通过移位操作使小卷积核达到大卷积核的效果,提升YOLOv8模型的性能。Shift-ConvNets解决了大卷积核带来的计算成本和兼容性问题,实现在稀疏机制下捕获远程依赖关系,同时保持硬件友好。手把手教程涵盖了将Shift-Conv整合到YOLOv8-pose的步骤。
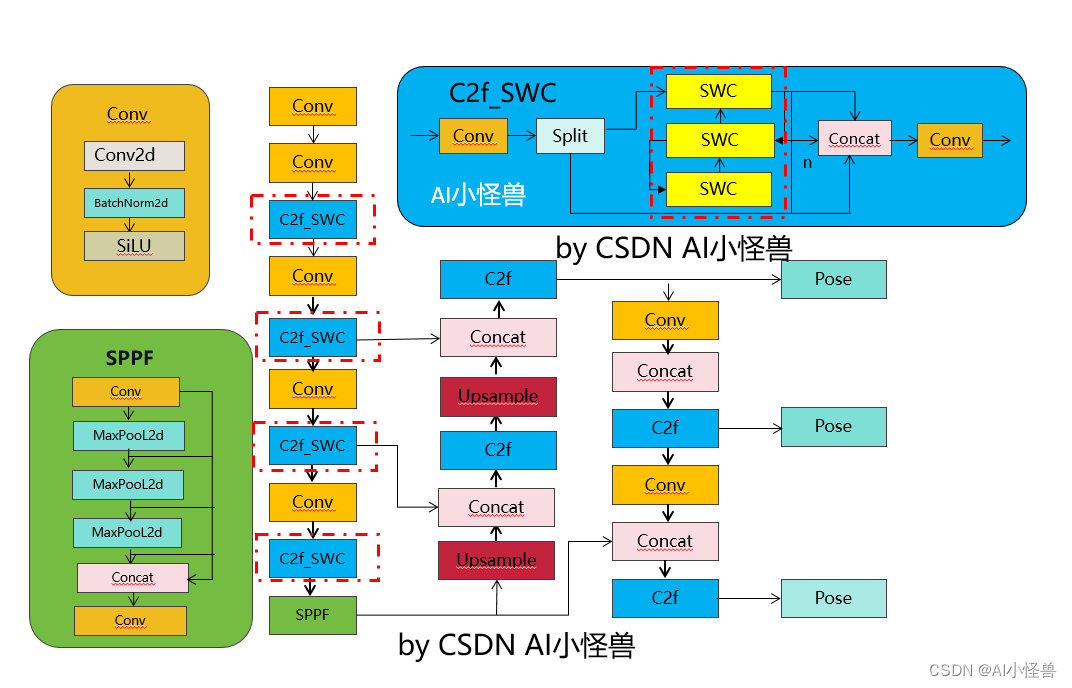
💡💡💡本文独家改进:大的卷积核设计成为使卷积神经网络(CNNs)再次强大的理想解决方案,Shift-ConvNets稀疏/移位操作让小卷积核也能达到大卷积核效果,创新十足实现涨点,助力YOLOv8
YOLOv8-Pose关键点检测专栏介绍:http://t.csdnimg.cn/gRW1b
✨✨✨手把手教你从数据标记到生成适合Yolov8-pose的yolo数据集;
🚀🚀🚀模型性能提升、pose模式部署能力;
🍉🍉🍉应用范围:工业工件定位、人脸、摔倒检测等支持各个关键点检测;
💡💡💡本文独家改进:大的卷积核设计成为使卷积神经网络(CNNs)再次强大的理想解决方案,Shift-ConvNets稀疏/移位操作让小卷积核也能达到大卷积核效果,创新十足实现涨点,助力YOLOv8
YOLOv8-Pose关键点检测专栏介绍:http://t.csdnimg.cn/gRW1b
✨✨✨手把手教你从数据标记到生成适合Yolov8-pose的yolo数据集;
🚀🚀🚀模型性能提升、pose模式部署能力;
🍉🍉🍉应用范围:工业工件定位、人脸、摔倒检测等支持各个关键点检测;
 2045
2045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文

























