









💡💡💡提供两种经典注意力改进方法,涨点小能手:1)通道注意力和空间注意力CBAM;2)全新注意力GAM:超越CBAM,不计成本提高精度;
💡💡💡本文改进:分别加入到YOLO11的backbone、neck、detect,助力涨点
改进1结构图:

改进2结构图:

改进3结构图:

《YOLOv11魔术师专栏》将从以下各个方向进行创新:
链接:
【原创自研模块】【多组合点优化】【注意力机制】【卷积魔改】【block&多尺度融合结合】【损失&IOU优化】【上下采样优化 】【小目标性能提升】【前沿论文分享】【训练实战篇】
订阅者通过添加WX: AI_CV_0624,入群沟通,提供改进结构图等一系列定制化服务。
定期向订阅者提供源码工程,配合博客使用。
订阅者可以申请发票,便于报销
💡💡💡为本专栏订阅者提供创新点改进代码,改进网络结构图,方便paper写作!!!
💡💡💡适用场景:红外、小目标检测、工业缺陷检测、医学影像、遥感目标检测、低对比度场景
💡💡💡适用任务:所有改进点适用【检测】、【分割】、【pose】、【分类】等
💡💡💡全网独家首发创新,【自研多个自研模块】,【多创新点组合适合paper 】!!!
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
包含注意力机制魔改、卷积魔改、检测头创新、损失&IOU优化、block优化&多层特征融合、 轻量级网络设计、24年最新顶会改进思路、原创自研paper级创新等
🚀🚀🚀 本项目持续更新 | 更新完结保底≥80+ ,冲刺100+ 🚀🚀🚀
🍉🍉🍉 联系WX: AI_CV_0624 欢迎交流!🍉🍉🍉
⭐⭐⭐专栏涨价趋势 159 ->199->259->299,越早订阅越划算⭐⭐⭐
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8、Yolov9等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
1.YOLO11介绍
Ultralytics YOLO11是一款尖端的、最先进的模型,它在之前YOLO版本成功的基础上进行了构建,并引入了新功能和改进,以进一步提升性能和灵活性。YOLO11设计快速、准确且易于使用,使其成为各种物体检测和跟踪、实例分割、图像分类以及姿态估计任务的绝佳选择。


结构图如下:

1.1 C3k2
C3k2,结构图如下

C3k2,继承自类C2f,其中通过c3k设置False或者Ture来决定选择使用C3k还是Bottleneck

实现代码ultralytics/nn/modules/block.py
1.2 C2PSA介绍
借鉴V10 PSA结构,实现了C2PSA和C2fPSA,最终选择了基于C2的C2PSA(可能涨点更好?)

实现代码ultralytics/nn/modules/block.py
1.3 11 Detect介绍
分类检测头引入了DWConv(更加轻量级,为后续二次创新提供了改进点),结构图如下(和V8的区别):

实现代码ultralytics/nn/modules/head.py
2.计算机视觉中的注意力机制
一般来说,注意力机制通常被分为以下基本四大类:
通道注意力 Channel Attention
空间注意力机制 Spatial Attention
时间注意力机制 Temporal Attention
分支注意力机制 Branch Attention
2.1.CBAM:通道注意力和空间注意力的集成者
轻量级的卷积注意力模块,它结合了通道和空间的注意力机制模块
论文题目:《CBAM: Convolutional Block Attention Module》
论文地址: https://arxiv.org/pdf/1807.06521.pdf

上图可以看到,CBAM包含CAM(Channel Attention Module)和SAM(Spartial Attention Module)两个子模块,分别进行通道和空间上的Attention。这样不只能够节约参数和计算力,并且保证了其能够做为即插即用的模块集成到现有的网络架构中去。
2.2 GAM:Global Attention Mechanism
超越CBAM,全新注意力GAM:不计成本提高精度!
论文题目:Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions
论文地址:https://paperswithcode.com/paper/global-attention-mechanism-retain-information
从整体上可以看出,GAM和CBAM注意力机制还是比较相似的,同样是使用了通道注意力机制和空间注意力机制。但是不同的是对通道注意力和空间注意力的处理。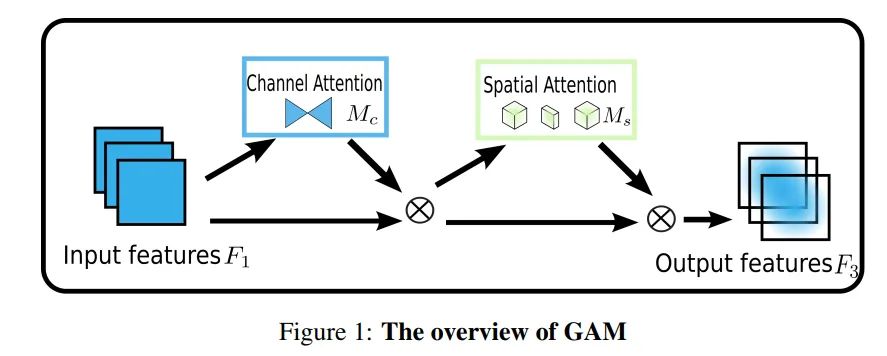
3.CBAM、GAM如何加入到YOLO11
3.1新建ultralytics/nn/attention/attention.py
###################### CBAM GAM #### START by AI&CV ###############################
import torch
from torch import nn
from torch.nn import init
import torch.nn.functional as F
from ultralytics.nn.modules.conv import Conv
class ChannelAttention(nn.Module):
# Channel-attention module https://github.com/open-mmlab/mmdetection/tree/v3.0.0rc1/configs/rtmdet
def __init__(self, channels: int) -> None:
super().__init__()
self.pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True)
self.act = nn.Sigmoid()
def forward(self, x: torch.Tensor) -> torch.Tensor:
return x * self.act(self.fc(self.pool(x)))
class SpatialAttention(nn.Module):
# Spatial-attention module
def __init__(self, kernel_size=7):
super().__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.act = nn.Sigmoid()
def forward(self, x):
return x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1)))
class CBAM(nn.Module):
# Convolutional Block Attention Module
def __init__(self, c1, c2, kernel_size=7): # ch_in, kernels
super().__init__()
self.channel_attention = ChannelAttention(c2)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
return self.spatial_attention(self.channel_attention(x))
def channel_shuffle(x, groups=2): ##shuffle channel
# RESHAPE----->transpose------->Flatten
B, C, H, W = x.size()
out = x.view(B, groups, C // groups, H, W).permute(0, 2, 1, 3, 4).contiguous()
out = out.view(B, C, H, W)
return out
class GAM_Attention(nn.Module):
# https://paperswithcode.com/paper/global-attention-mechanism-retain-information
def __init__(self, c1, c2, group=True, rate=4):
super(GAM_Attention, self).__init__()
self.channel_attention = nn.Sequential(
nn.Linear(c1, int(c1 / rate)),
nn.ReLU(inplace=True),
nn.Linear(int(c1 / rate), c1)
)
self.spatial_attention = nn.Sequential(
nn.Conv2d(c1, c1 // rate, kernel_size=7, padding=3, groups=rate) if group else nn.Conv2d(c1, int(c1 / rate),
kernel_size=7,
padding=3),
nn.BatchNorm2d(int(c1 / rate)),
nn.ReLU(inplace=True),
nn.Conv2d(c1 // rate, c2, kernel_size=7, padding=3, groups=rate) if group else nn.Conv2d(int(c1 / rate), c2,
kernel_size=7,
padding=3),
nn.BatchNorm2d(c2)
)
def forward(self, x):
b, c, h, w = x.shape
x_permute = x.permute(0, 2, 3, 1).view(b, -1, c)
x_att_permute = self.channel_attention(x_permute).view(b, h, w, c)
x_channel_att = x_att_permute.permute(0, 3, 1, 2)
# x_channel_att=channel_shuffle(x_channel_att,4) #last shuffle
x = x * x_channel_att
x_spatial_att = self.spatial_attention(x).sigmoid()
x_spatial_att = channel_shuffle(x_spatial_att, 4) # last shuffle
out = x * x_spatial_att
# out=channel_shuffle(out,4) #last shuffle
return out
###################### CBAM GAM #### end by AI&CV ###############################3.2 修改tasks.py
1)首先进行引用定义
from ultralytics.nn.attention.attention import *2)修改def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
只需要在你源码基础上加入GAM_Attention,CBAM(切勿直接复制过去)
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
if m in {
Classify,
Conv,
ConvTranspose,
GhostConv,
Bottleneck,
GhostBottleneck,
SPP,
SPPF,
C2fPSA,
C2PSA,
DWConv,
Focus,
BottleneckCSP,
C1,
C2,
C2f,
C3k2,
RepNCSPELAN4,
ELAN1,
ADown,
AConv,
SPPELAN,
C2fAttn,
C3,
C3TR,
C3Ghost,
nn.ConvTranspose2d,
DWConvTranspose2d,
C3x,
RepC3,
PSA,
SCDown,
C2fCIB,
GAM_Attention,CBAM
}:
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
if m is C2fAttn:
args[1] = make_divisible(min(args[1], max_channels // 2) * width, 8) # embed channels
args[2] = int(
max(round(min(args[2], max_channels // 2 // 32)) * width, 1) if args[2] > 1 else args[2]
) # num heads
args = [c1, c2, *args[1:]]
if m in {
BottleneckCSP,
C1,
C2,
C2f,
C3k2,
C2fAttn,
C3,
C3TR,
C3Ghost,
C3x,
RepC3,
C2fPSA,
C2fCIB,
C2PSA,
}:
args.insert(2, n) # number of repeats
n = 1
if m is C3k2 and scale in "mlx": # for M/L/X sizes
args[3] = True
elif m is AIFI:
args = [ch[f], *args]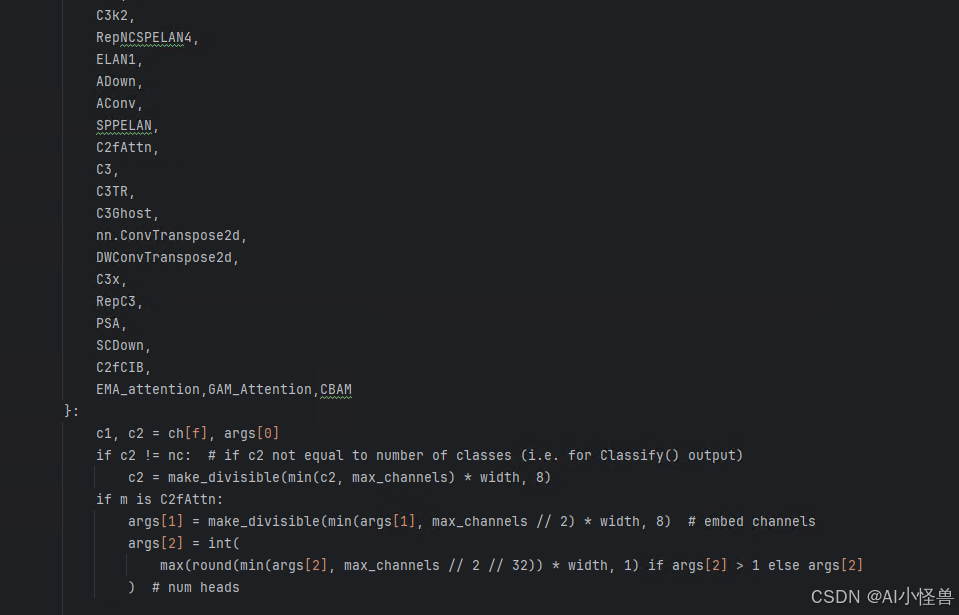
3.3 yaml修改
提供多种 GAM_Attention,CBAM修改方式,分别加在网络不同位置,总有一种适合你的数据集
3.3.1 yolo11-CBAM.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
- [-1, 1, CBAM, [1024]] # 11
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 14
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 17 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 20 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 23 (P5/32-large)
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
3.3.2 yolo11-CBAM1.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [16, 1, CBAM, [256]] # 23
- [19, 1, CBAM, [512]] # 24
- [22, 1, CBAM, [1024]] # 25
- [[23, 24, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
3.3.3 yolo11-CBAM2.yaml

# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, CBAM, [256]] # 17
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 20 (P4/16-medium)
- [-1, 1, CBAM, [512]] # 21
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 24 (P5/32-large)
- [-1, 1, CBAM, [1024]] # 25
- [[17, 21, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
3.3.4 yolo11-GAM_Attention.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
- [-1, 1, GAM_Attention, [1024]] # 11
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 14
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 17 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 20 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 23 (P5/32-large)
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
3.3.5 yolo11-GAM_Attention1.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [16, 1, GAM_Attention, [256]] # 23
- [19, 1, GAM_Attention, [512]] # 24
- [22, 1, GAM_Attention, [1024]] # 25
- [[23, 24, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
3.3.6 yolo11-GAM_Attention2.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, GAM_Attention, [256]] # 17
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 20 (P4/16-medium)
- [-1, 1, GAM_Attention, [512]] # 21
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 24 (P5/32-large)
- [-1, 1, GAM_Attention, [1024]] # 25
- [[17, 21, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)


















 6315
6315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











