








💡💡💡本文原创自研创新改进:
优点:为了利用不同的池化核尺寸提取特征的方式可以获得更多的特征信息,提高网络的识别精度。
如何优化:在此基础上加入注意力机制,能够在不同尺度上更好的、更多的获取特征信息,从而获取全局视角信息并减轻不同尺度大小所带来的影响
强烈推荐,适合直接使用,paper创新级别
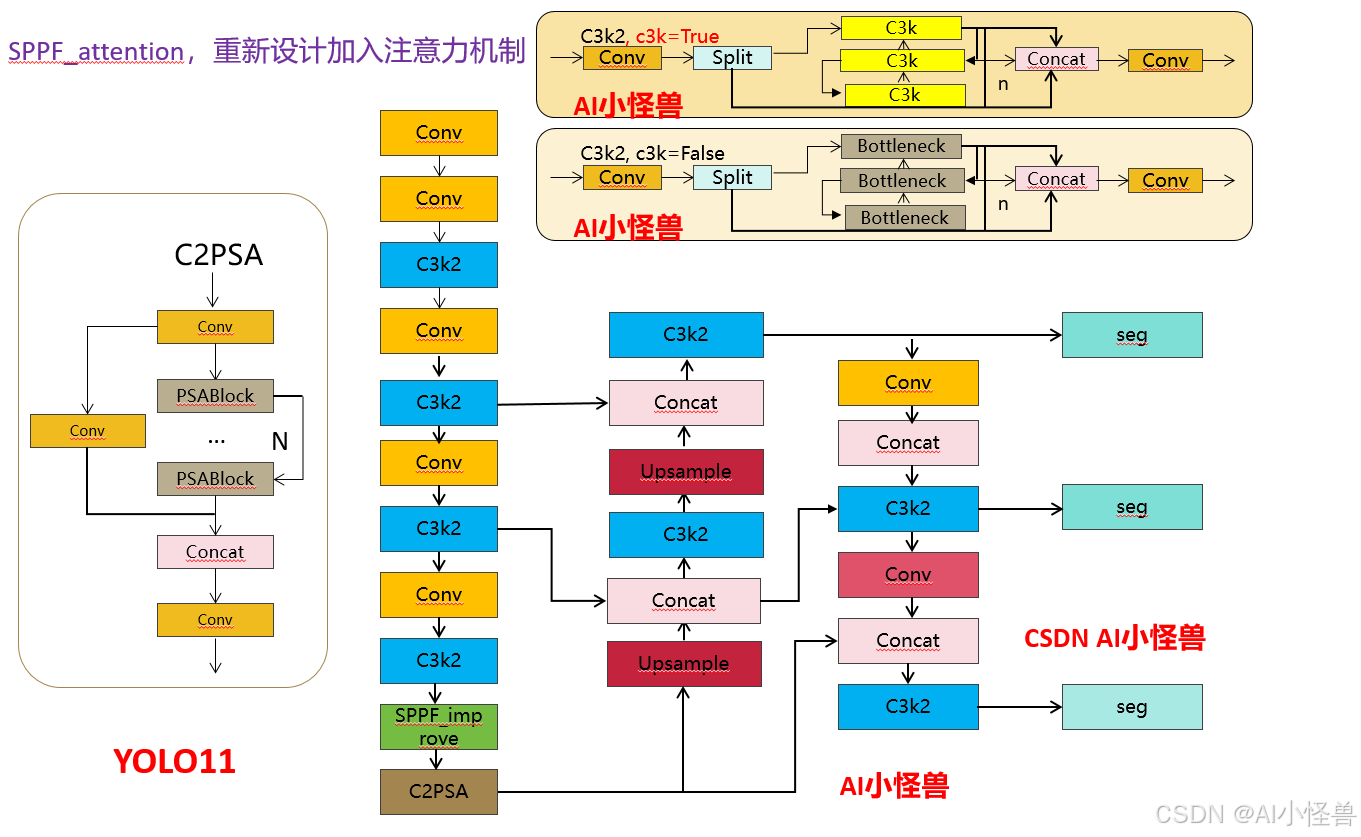
💡💡💡本文内容:通过 SPPF_attention,重新设计加入注意力机制提升YOLO11-seg的分割能力
💡💡💡Mask mAP50 从原始的0.673 提升至0.693,实现暴力涨点
《YOLOv11魔术师专栏》将从以下各个方向进行创新:
【原创自研模块】【多组合点优化】【注意力机制】【卷积魔改】【block&多尺度融合结合】【损失&IOU优化】【上下采样优化 】【小目标性能提升】【前沿论文分享】【训练实战篇】
【pose关键点检测】【yolo11-seg分割】
定期向订阅者提供源码工程,配合博客使用。
订阅者可以申请发票,便于报销
💡💡💡为本专栏订阅者提供创新点改进代码,改进网络结构图,方便paper写作!!!
💡💡💡适用场景:红外、小目标检测、工业缺陷检测、医学影像、遥感目标检测、低对比度场景
💡💡💡适用任务:所有改进点适用【检测】、【分割】、【pose】、【分类】等
💡💡💡全网独家首发创新,【自研多个自研模块】,【多创新点组合适合paper 】!!!
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
包含注意力机制魔改、卷积魔改、检测头创新、损失&IOU优化、block优化&多层特征融合、 轻量级网络设计、24年最新顶会改进思路、原创自研paper级创新等
🚀🚀🚀 本项目持续更新 | 更新完结保底≥80+ ,冲刺100+ 🚀🚀🚀
🍉🍉🍉 联系WX: AI_CV_0624 欢迎交流!🍉🍉🍉
⭐⭐⭐专栏涨价趋势 159 ->199->259->299,越早订阅越划算⭐⭐⭐
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8、Yolov9等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
1.YOLO11介绍
Ultralytics YOLO11是一款尖端的、最先进的模型,它在之前YOLO版本成功的基础上进行了构建,并引入了新功能和改进,以进一步提升性能和灵活性。YOLO11设计快速、准确且易于使用,使其成为各种物体检测和跟踪、实例分割、图像分类以及姿态估计任务的绝佳选择。


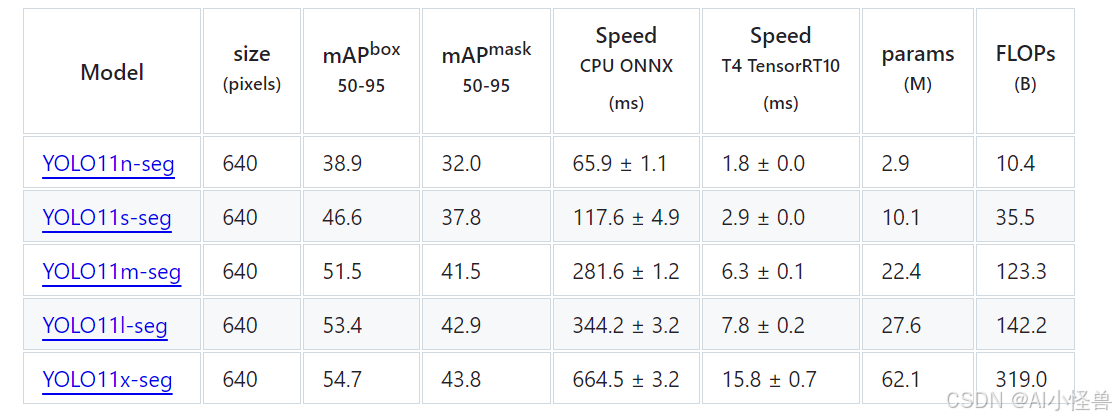
Segmentation 官方在COCO数据集上做了更多测试:
2.数据集介绍
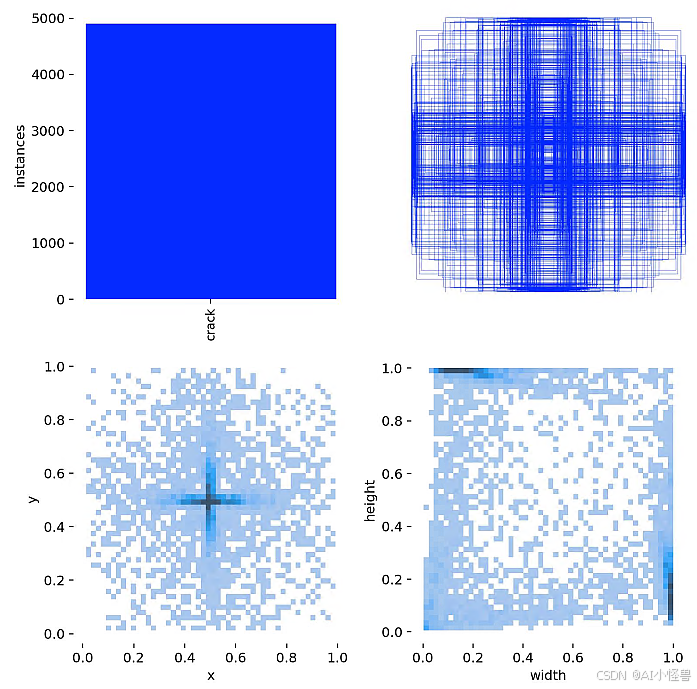
道路裂纹分割数据集是一个全面的4029张静态图像集合,专门为交通和公共安全研究而设计。它非常适合自动驾驶汽车模型开发和基础设施维护等任务。该数据集包括训练、测试和验证集,有助于精确的裂缝检测和分割。
训练集3712张,验证集200张,测试集112张

标签可视化:
3.如何训练YOLO11-seg模型
3.1 修改 crack-seg.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# Crack-seg dataset by Ultralytics
# Documentation: https://docs.ultralytics.com/datasets/segment/crack-seg/
# Example usage: yolo train data=crack-seg.yaml
# parent
# ├── ultralytics
# └── datasets
# └── crack-seg ← downloads here (91.2 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: D:/ultralytics-seg/data/crack-seg # dataset root dir
train: train/images # train images (relative to 'path') 3717 images
val: valid/images # val images (relative to 'path') 112 images
test: test/images # test images (relative to 'path') 200 images
# Classes
names:
0: crack
3.2 如何开启训练
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/11/yolo11-seg.yaml')
#model.load('yolov8n.pt') # loading pretrain weights
model.train(data='data/crack-seg.yaml',
cache=False,
imgsz=640,
epochs=200,
batch=16,
close_mosaic=10,
device='0',
optimizer='SGD', # using SGD
project='runs/train',
name='exp',
)
3.3 训练结果可视化
YOLO11-seg summary (fused): 265 layers, 2,834,763 parameters, 0 gradients, 10.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100%|██████████| 7/7 [00:07<00:00, 1.06s/it]
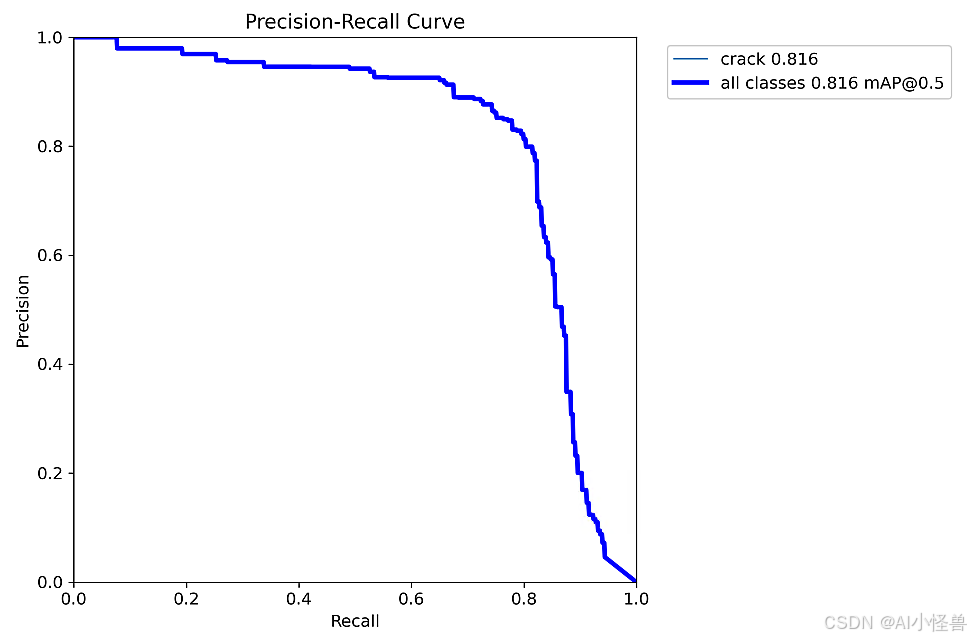
all 200 249 0.83 0.784 0.816 0.632 0.746 0.707 0.673 0.228
Mask mAP50 为 0.673
MaskPR_curve.png
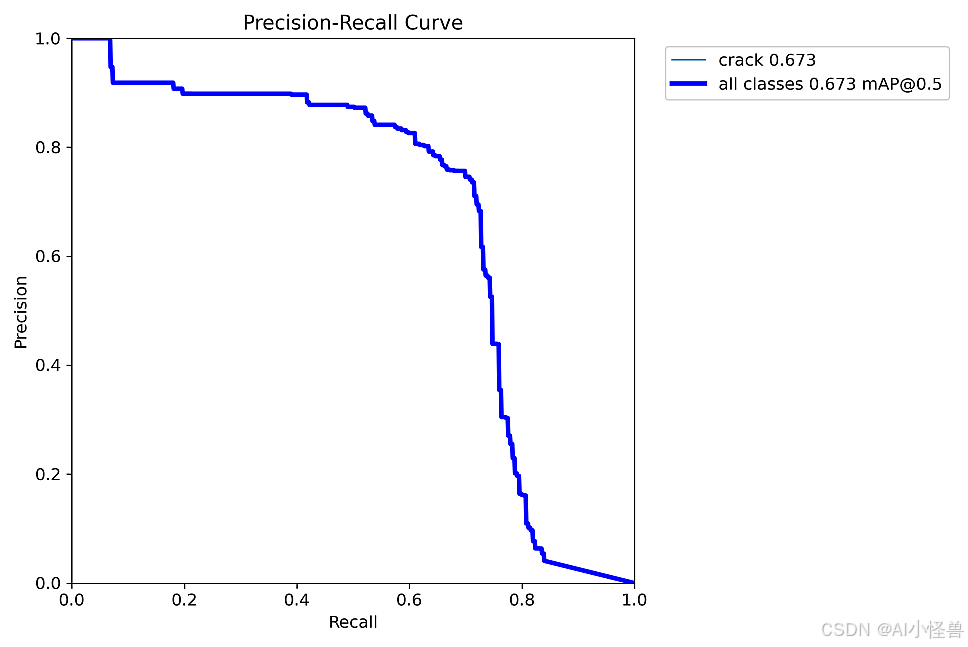
BoxPR_curve.png
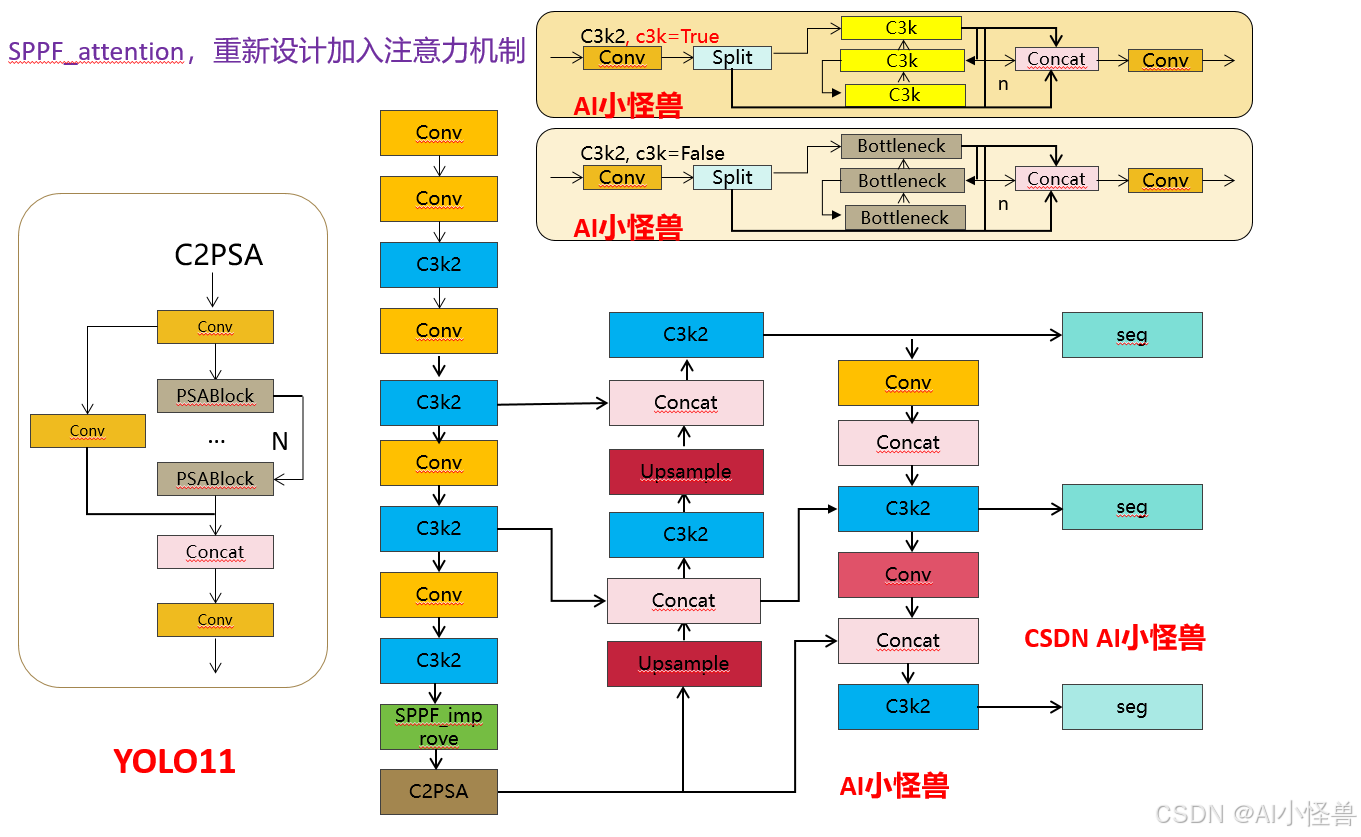
3.4 SPPF_attention,重新设计加入注意力机制
YOLOv5最初采用SPP结构在v6.0版本(repo)后开始使用SPPF,主要目的是融合更大尺度(全局)信息,对每个特征图,使用三种不同尺寸(5×5、9×9、13×13)的池化核进行最大池化,分别得到预设的特征图尺寸,最后将所有特征图展开为特征向量并融合,过程如下图所示。
YOLOV8使用SPPF
SPPF顾名思义,就是为了保证准确率相似的条件下,减少计算量,以提高速度,使用3个5×5的最大池化,代替原来v5之前的5×5、9×9、13×13最大池化。使用SPPF的目的是为了利用不同的池化核尺寸提取特征的方式可以获得更多的特征信息,提高网络的识别精度。
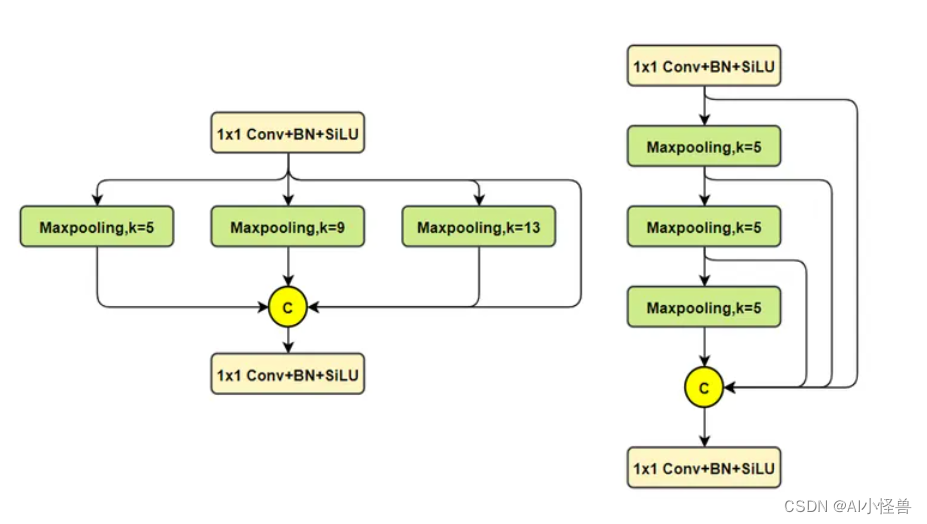 左边是SPP,右边是SPPF。
左边是SPP,右边是SPPF。
SPPF源代码
class SPPF(nn.Module):
"""Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher."""
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
"""Forward pass through Ghost Convolution block."""
x = self.cv1(x)
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))3.5 如何创新优化SPPF
优点:为了利用不同的池化核尺寸提取特征的方式可以获得更多的特征信息,提高网络的识别精度。
如何优化:在此基础上加入注意力机制,能够在不同尺度上更好的、更多的获取特征信息,从而提高网络的识别精度。
原文链接:
YOLO11涨点优化:SPPF原创自研 | SPPF_attention,重新设计加入注意力机制,能够在不同尺度上更好的、更多的关注注意力特征信息-CSDN博客
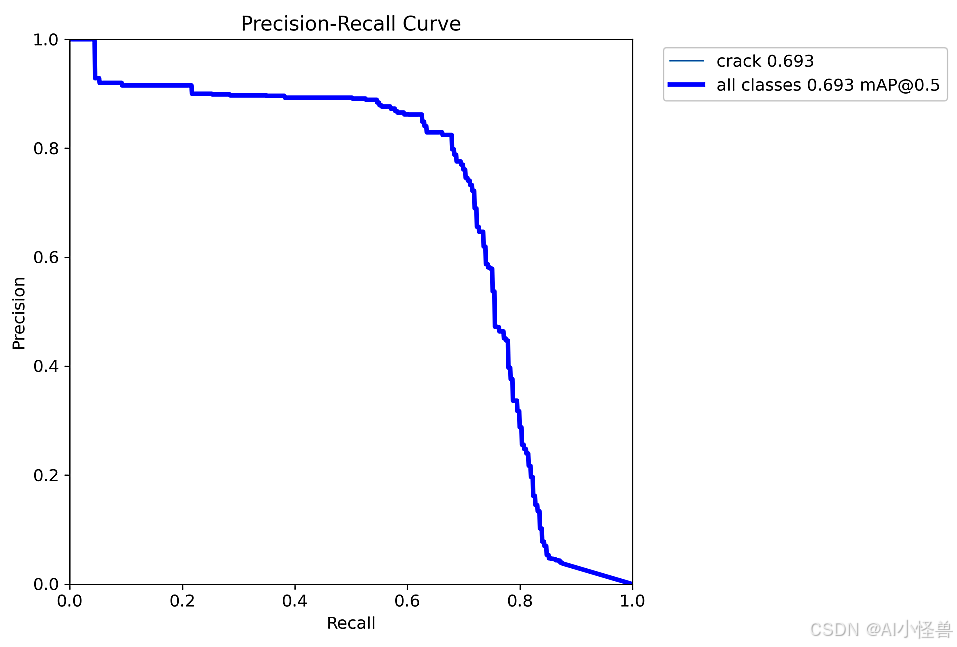
YOLO11-seg-SPPF_attention summary (fused): 274 layers, 3,361,101 parameters, 0 gradients, 10.6 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100%|██████████| 7/7 [00:08<00:00, 1.23s/it]
all 200 249 0.89 0.777 0.844 0.659 0.799 0.679 0.693 0.232
Mask mAP50 从原始的0.673 提升至0.693,实现暴力涨点


















 834
834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











