







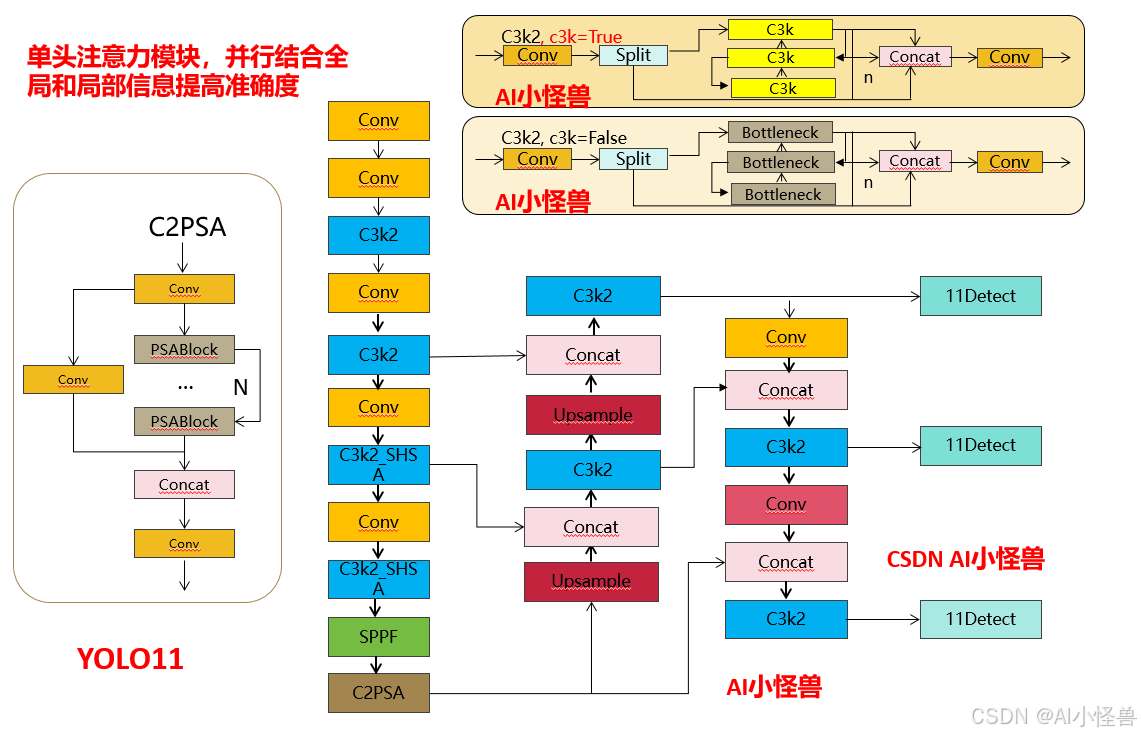
💡💡💡引入了一个单头注意力模块,它固有地防止了头部冗余,同时通过并行结合全局和局部信息来提高准确性
💡💡💡如何使用:1)结合C3k2二次创新使用
SHSA结合 C3k2 | 亲测在遥感小目标车辆检测涨点,原始mAP50为0.879提升至0.884,对比实验yolov10n 0.824
改进结构图如下:
1.小目标检测介绍
1.1 小目标定义
1)以物体检测领域的通用数据集COCO物体定义为例,小目标是指小于32×32个像素点(中物体是指32*32-96*96,大物体是指大于96*96);
2)在实际应用场景中,通常更倾向于使用相对于原图的比例来定义:物体标注框的长宽乘积,除以整个图像的长宽乘积,再开根号,如果结果小于3%,就称之为小目标;

1.2 难点
1)包含小目标的样本数量较少,这样潜在的让目标检测模型更关注中大目标的检测;
2)由小目标覆盖的区域更小,这样小目标的位置会缺少多样性。我们推测这使得小目标检测的在验证时的通用性变得很难;

3)anchor难匹配问题。这主要针对anchor-based方法,由于小目标的gt box和anchor都很小,anchor和gt box稍微产生偏移,IoU就变得很低,导致很容易被网络判断为negative sample;
4)它们不仅仅是小,而且是难,存在不同程度的遮挡、模糊、不完整现象;
等等难点
参考论文:http://sjcj.nuaa.edu.cn/sjcjycl/article/html/202103001
2.遥感小目标车辆检测数据集
数据集大小:训练集2100张,验证集900
细节图



3.YOLO11介绍
Ultralytics YOLO11是一款尖端的、最先进的模型,它在之前YOLO版本成功的基础上进行了构建,并引入了新功能和改进,以进一步提升性能和灵活性。YOLO11设计快速、准确且易于使用,使其成为各种物体检测和跟踪、实例分割、图像分类以及姿态估计任务的绝佳选择。


结构图如下:

3.1 C3k2
C3k2,结构图如下

C3k2,继承自类C2f,其中通过c3k设置False或者Ture来决定选择使用C3k还是Bottleneck

实现代码ultralytics/nn/modules/block.py
3.2 C2PSA介绍
借鉴V10 PSA结构,实现了C2PSA和C2fPSA,最终选择了基于C2的C2PSA(可能涨点更好?)

实现代码ultralytics/nn/modules/block.py
3.3 11 Detect介绍
分类检测头引入了DWConv(更加轻量级,为后续二次创新提供了改进点),结构图如下(和V8的区别):

实现代码ultralytics/nn/modules/head.py
4.SHSA结合C3k2原理介绍
原文链接:
YOLO11小目标检测 | 单头注意力模块,并行结合全局和局部信息提高准确度 | SHViT CVPR2024-CSDN博客

论文:https://arxiv.org/pdf/2401.16456
摘要:近年来,高效的视觉变压器在资源受限的设备上表现出了良好的性能和低延迟。通常,他们在宏观层面上使用4×4贴片嵌入和4级结构,而在微观层面上使用复杂的多头配置。本文旨在以内存高效的方式解决所有设计级别的计算冗余。我们发现,使用更大跨距的补丁化系统不仅降低了内存访问成本,而且通过利用标记表示从早期阶段就减少了空间冗余,实现了具有竞争力的性能。此外,我们的初步分析表明,早期阶段的注意层可以用卷积代替,而后期阶段的几个注意头在计算上是冗余的。为了解决这个问题,我们引入了一个单头注意力模块,它固有地防止了头部冗余,同时通过并行结合全局和局部信息来提高准确性。在我们的解决方案的基础上,我们推出了SHViT,一种单头视觉变压器,可获得最先进的速度和精度权衡。例如,在ImageNet-1k上,我们的shvitt - s4在GPU、CPU和iPhone12移动设备上分别比MobileViTv2 ×1.0快3.3倍、8.1倍和2.4倍,准确率提高1.3%。对于使用MaskRCNN头的MS COCO对象检测和实例分割,我们的模型达到了与fastviti - sa12相当的性能,但分别比fastviti - sa12低3.8倍和2.0倍 GPU和移动设备的骨干网时延。
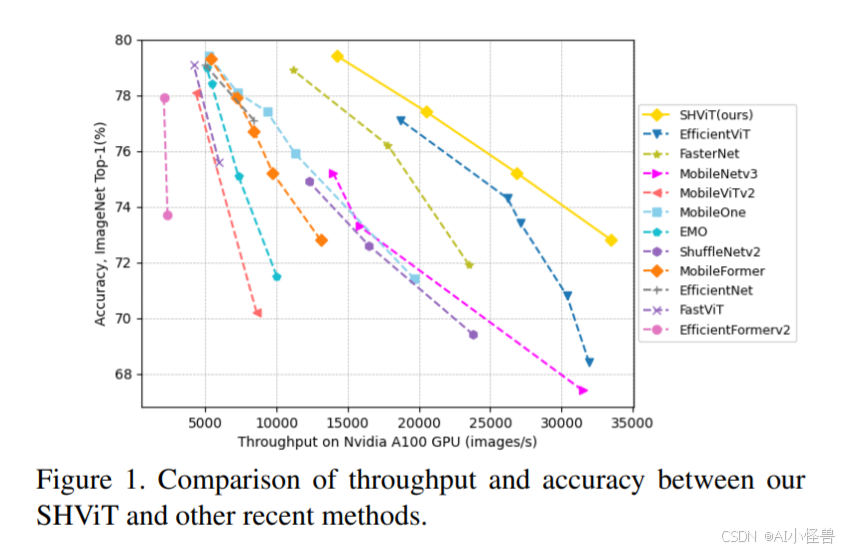
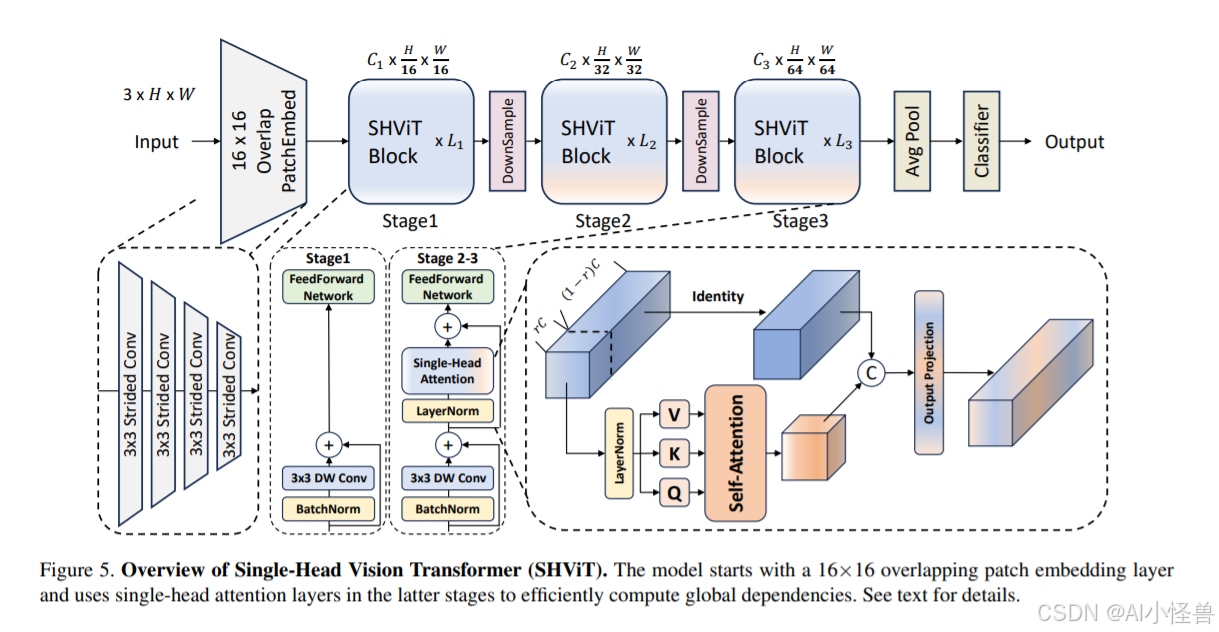
5.如何魔改提升遥感小目标检测精度
5.1 原始网络性能
实验结果如下:
原始mAP50为0.879
YOLO11 summary (fused): 238 layers, 2,582,347 parameters, 0 gradients, 6.3 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 29/29 [00:24<00:00, 1.20it/s]
all 900 6917 0.888 0.829 0.879 0.333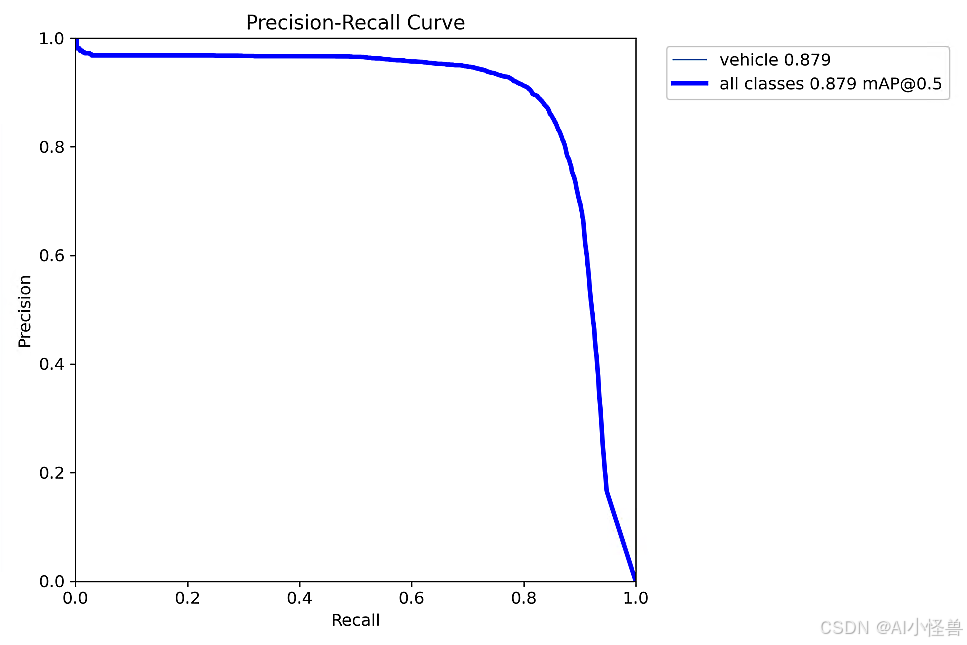
5.2 YOLOv10对比实验
原始YOLOv10n结果如下:
原始mAP50为 0.824
YOLOv10n summary (fused): 285 layers, 2694806 parameters, 0 gradients, 8.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 29/29 [00:24<00:00, 1.19it/s]
all 900 6917 0.833 0.754 0.824 0.302
5.3 SHSA结合C3k2二次创新
原始mAP50为0.879提升至0.881,对比实验yolov10n 0.824
YOLO11-C3k2_SHSA summary: 327 layers, 2,692,371 parameters, 0 gradients, 7.6 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 29/29 [00:24<00:00, 1.18it/s]
all 900 6917 0.89 0.829 0.881 0.335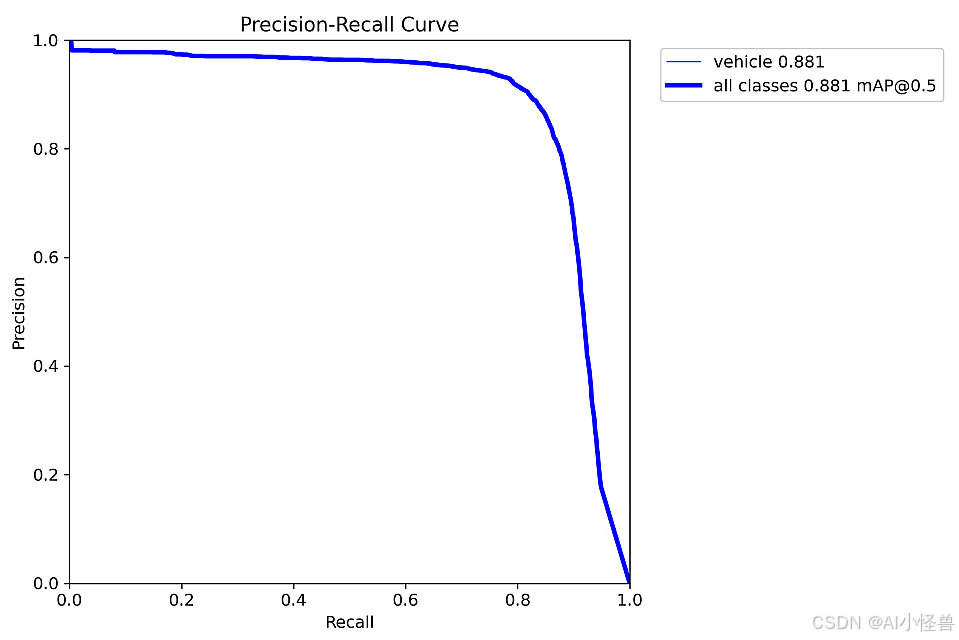
结构图:
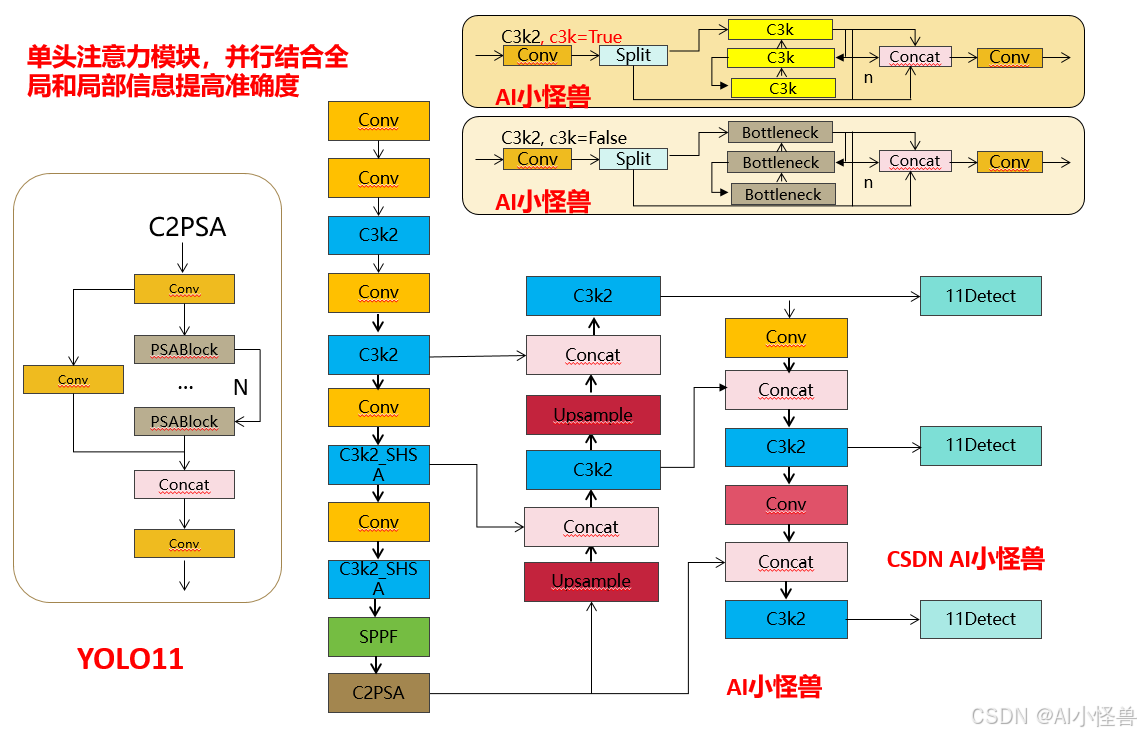
原文链接:
YOLO11小目标检测 | 单头注意力模块,并行结合全局和局部信息提高准确度 | SHViT CVPR2024-CSDN博客


















 2436
2436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











