






目录
1.概念
1.特征维度约减的概念
- 特征约减的目的是将高维特征向量映射到低维子空间中.
-
给定 n 个样本(每个样本维度为 p 维){x1,x2……xn} 通过特征变换/ 投影矩阵实现特征空间的压缩:
-
典型高维数据:基因数据,人脸图像等
2.维度约减的原因
-
大多数机器学习算法在高维空间中表现不够鲁棒:查询精度和速度随着维度增加而降低
-
有价值的维度往往很少
-
可视化 : 高位数据在 2D 或 3D 空间中的可视化维度约减 : 高效的存储与检索噪声消除 : 提升分类或识别精度
-
维度约减的应用:人脸识别、基因分类、图像检索、文本挖掘
3.常规维度约减方法
- 无监督方法:用无标签的数据训练,如k-means
- 监督方法:用有标签的数据训练,如SVM
- 半监督方法:利用少量有标签的数据和大量无标签的数据来训练网络
2.主成分分析 (PCA)基本思路
-
– 通过协方差分析,建立 高维空间到低维空间的线性映射 / 矩阵– 保留尽可能多的样本信息– 压缩后的数据对分类、聚类尽量不产生影响,甚至有所提升
- 将原始高维向量通过投影矩阵,投射到低维空间
– 这些向量称为 主成分 , 具有 无关性、正交 的特点。重要的是这些向量的数量要 远小于 高维空间的维度。
-
主成分:


主成分:与第一主成分正交

3.主成分的代数定义及推导
1.代数定义
- 给定n个样本(每个样本维度为p维)
- 定义
为样本
在第一主成分
上的投影:

2.代数推导
- 首先根据z1的方差定义,推导得出:

- 在实际计算中,可以先将样本减去均值使得样本均值为0,这样可以更加方便计算
- 所以假设均值为0,那么
,可证明S半正定
- 半正定:给定一个大小为n×n的实对称矩阵 A ,若对于任意长度为 n 的非零向量 x ,有
恒成立,则矩阵 A是一个半正定矩阵。
目标是找到主方向a1 , 使z1的方差最大,且满足
,引入一个 Lagrange 乘子λ,则有:
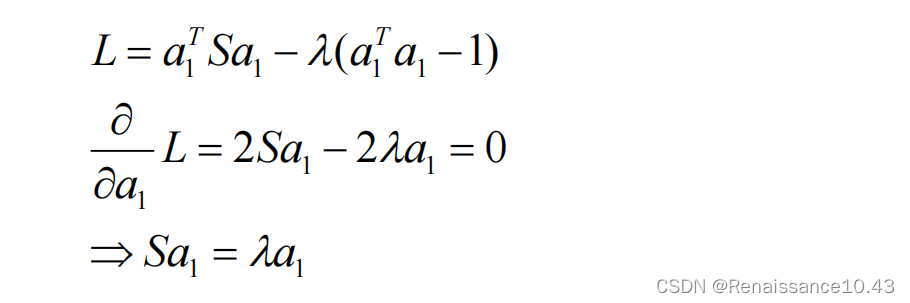
- 在a1的基础上,要计算下一个主成分a2,使得z2方差最大化,则有cov[z2 ,z1] = 0,且
,根据协方差定义,

分别令 λ 与 φ 为 Lagrange 乘子,问题变成最大化

- 实际上可以求证a2也是协方差矩阵 S 的特征向量,且a2是S的第二大的特征向量。

3.PCA算法流程
- 数据集{
}
- 计算数据集{
-
计算协方差矩阵
- 计算S特征向量
-
根据特定准则(如压缩到 d 维,或保留特定能量比例)选择d个特征向量
, 并组成变换矩阵
,
4.代码示例-使用PCA去实现人脸识别
from json import load
from operator import index
import cv2
import numpy as np
# 导入sklearn的pca模块
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
import pandas as pd
import matplotlib.pyplot as plt
def imgarray():
# 将所有图片读取为arrayList
path = "./Face_Dataset/Face/ORL_Faces/s"
ImgList = []
for i in range(1, 41):
for j in range(1, 11):
imgPath = path + str(i) + "/" + str(j) + ".pgm"
img = cv2.imread(imgPath) # 通过opencv读取图片
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 将图片转为灰度图
# img = np.resize(img,(img.shape[0]*img.shape[1],1))
# img = np.array(img).reshape(-1,1)
ImgList.append(img)
ImgList = np.array(ImgList)
return ImgList-
首先,导入所需的库,包括
json、operator、cv2、numpy、sklearn中的PCA和train_test_split,以及pandas和matplotlib.pyplot。 -
定义了一个名为
imgarray()的函数,该函数没有参数。 -
path = "./Face_Dataset/Face/ORL_Faces/s":在函数内部,定义了一个变量path,用于存储图像文件所在的路径。指定图像文件的路径为
./Face_Dataset/Face/ORL_Faces/,后面跟着以 "s" 开头的文件夹名字。(在ORL_Faces中有s1,s2文件,所以都是s开头)。这样,当代码处理图像时,可以通过拼接路径和文件名来访问每个图像文件,在下面代码中的imPath就用到这个方法。 -
创建一个空的列表
ImgList,用于存储所有的图像数据。 -
使用两个嵌套的循环,遍历所有的图像文件。外层循环遍历 1 到 40,内层循环遍历 1 到 10。这样可以遍历每个人的 10 张图像。
-
imgPath = path + str(i) + "/" + str(j) + ".pgm":在循环内部,构建每个图像文件的完整路径,例如
"./ORL_Faces/s1/1.pgm"。 -
使用
cv2.imread()函数读取图像文件,并将其存储在变量img中。 -
使用
cv2.cvtColor()函数将图像从 BGR 格式转换为灰度图像。 -
将转换后的图像添加到列表
ImgList中。 -
将
ImgList转换为 numpy 数组,并将其作为函数的返回值。
def loadlabel():
images = []
labels = []
faces = imgarray()
for index,face in enumerate(faces):
# enumerate函数可以同时获得索引和值
image = faces[index]
# image = cv2.imread(face,0) # cv.imread(filename[, flags]) flag = 0表示8位深度,1通道
images.append(image)
labels.append(int(index/10+1))
images = np.array(images)
labels = np.array(labels)
return labels,images #转化为元组输出
这个函数的作用是将每个图像的标签与图像数据关联起来。
1. imgarray(),将图像数据读取为一个 numpy 数组 faces
2.使用一个 for 循环遍历数组中的每个图像,并为每个图像添加标签。
3.enumerate():循环中使用了该函数,它可以同时获取数组中元素的索引和值。在每次循环中,使用索引 index 和对应的图像 face,将标签添加到 labels 列表中。标签的值通过计算 (index/10)+1 来获得,其中 index 是当前图像在数组中的索引。
4.最后,将 images 和 labels 分别转换为 numpy 数组并作为函数的返回值输出。
def perimg():
# 图像数据矩阵转换为一维
image_data = []
for image in imgarray():
data = image.flatten()
# a是个矩阵或者数组,a.flatten()就是把a降到一维,默认是按横的方向降
image_data.append(data)
# print(image_data[0].shape)
image_data = np.array(image_data)
return image_data将图像数据矩阵转换为一维数组的功能,用于在人脸识别中进行特征提取。
1.首先创建一个空列表 image_data 用于存储转换后的图像数据。
2.然后,通过调用 imgarray() 函数获取原始的图像数据矩阵,并使用 flatten() 方法将其降至一维数组形式。最后,将转换后的数据添加到 image_data 列表中。
3.最后,将 image_data 转换为 numpy 数组,并返回该数组。
if __name__ == "__main__":
img = perimg()
label = loadlabel()
X = img
#print(X)
y = label[0]
# 划分数据集
x_train,x_test,y_train,y_test = train_test_split(X, y, test_size=0.2) # train训练,test测试
# 训练PCA模型
pca=PCA(n_components=100) # 保留100个纬度
pca.fit(x_train) # 训练过程
# 返回训练集和测试集降维后的数据集
x_train_pca = pca.transform(x_train) # 转换过程
x_test_pca = pca.transform(x_test)
print(x_train_pca.shape) # 320个训练集,保留了100个特征
print(x_test_pca.shape) # 80个测试集,保留了100个特征
V = pca.components_
V.shape
# print(V.shape)
# 100个特征脸
# 创建画布和子图对象
fig, axes = plt.subplots(10,10
,figsize=(15,15)
,subplot_kw = {"xticks":[],"yticks":[]} #不要显示坐标轴
)
#填充图像
for i, ax in enumerate(axes.flat):
ax.imshow(V[i,:].reshape(112,92),cmap="gray") #reshape规定图片的大小,选择色彩的模式
plt.show()
# 模型创建与训练
model = cv2.face.EigenFaceRecognizer_create()
model.train(x_train,y_train)
# 预测
res = model.predict(x_test[2])
print(res)
# 测试数据集的准确率
ress = []
true = 0
false = 0
for i in range(len(y_test)):
res = model.predict(x_test[i])
if y_test[i] == res[0]:
true = true + 1
else:
false = false + 1
print('测试集识别准确率:%.2f%%'% ((true/len(y_test))*100))使用PCA算法进行降维,并训练一个人脸识别模型
1.首先,调用了前面的 perimg() 函数,将图像数据转换为一维数组,并保存在 img 变量中。然后,调用了 loadlabel() 函数,获取标签数据,并保存在 label 变量中。
2.将 img 赋值给 X,表示特征数据。将 label[0] 赋值给 y,表示标签数据。
3.使用 train_test_split() 函数将数据集划分为训练集和测试集,其中测试集占总数据集的 20%。
4.创建一个 PCA 对象 pca,设置保留的特征数为 100,并使用训练集数据进行训练。
5.分别对训练集和测试集进行降维操作,得到降维后的数据 x_train_pca 和 x_test_pca。
6. V = pca.components_:获取 PCA 的主成分向量矩阵, V.shape:并打印其形状。
7.使用 matplotlib 库绘制特征脸图像。
——fig 是一个 Figure 对象,表示整个图形窗口,包含了所有的子图和元素。可以通过它设置图形的尺寸、标题、背景色等属性。
——axes 是一个 Axes 对象的数组,表示在这个 Figure 对象中的所有子图。
——调用 subplots() 函数创建一个 10x10 的子图,设置图像尺寸为 15x15 inches,并将坐标轴的刻度隐藏。将返回的子图对象保存在变量 fig 和 axes 中。
——遍历 axes.flat 迭代器和 V 矩阵的每一行,将每个主成分向量 reshape 成 112x92 的图像,并显示在对应的子图中。其中,imshow() 函数用于显示图像,cmap="gray" 表示使用灰度色彩模式。最后,通过调用 plt.show() 函数显示子图。
8.使用 OpenCV 中的 EigenFaceRecognizer 类创建一个人脸识别模型,并使用训练集数据进行训练。
9.使用该模型对测试集中的一个样本进行人脸识别预测,并打印结果。
10.计算模型在整个测试集上的准确率。通过遍历测试集中的每个样本,使用模型进行人脸识别预测,并统计预测正确和错误的数量。根据统计结果,计算并打印测试集的识别准确率。
结果:

5.总结
目标:PCA 的主要目标是找到一个新的坐标系,使得在新的坐标系下,数据的方差最大化。(如:目标是找到a1 , 使z1的方差最大。)这样做的目的是减少数据的维度,并且保留尽可能多的信息。
-
步骤:
- 数据中心化:将每个特征的均值都减去,使得数据的均值为零。
- 计算协方差矩阵:计算去中心化后数据的协方差矩阵。
- 特征值分解:对协方差矩阵进行特征值分解,得到特征值和特征向量。
- 选择主成分:根据特征值的大小选择前 k 个特征向量作为主成分,其中 k 是希望降低到的维度。
- 投影数据:将原始数据投影到所选的主成分上,得到降维后的数据。
-
应用:
- 数据压缩:PCA 可以用于减少数据集的维度,从而减少存储空间和计算成本。
- 数据可视化:将高维数据降低到二维或三维空间,可以更好地理解和可视化数据。
- 噪音过滤:通过保留前几个主成分,可以过滤掉数据中的噪音。
-
限制和注意事项:
- PCA 假设数据是线性相关的,对于非线性关系可能不适用。
- PCA 并不保证得到具有实际含义的特征。
- 在选择主成分时,需要权衡降维后的维度和保留的信息量之间的平衡。














 401
401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









