






阿里巴巴Qwen2.5大语言模型以颠覆性姿态强势登场,再次刷新多模态AI的行业标杆。作为国内AI领域的旗舰级产品,Qwen系列不仅实现了语言与多模态能力的深度融合,核心突破开启智能交互新纪元。

模型架构全面进化
▸ 参数规模覆盖0.5B到72B七级梯度("B"代表十亿参数),同时提供基础版与指令微调版
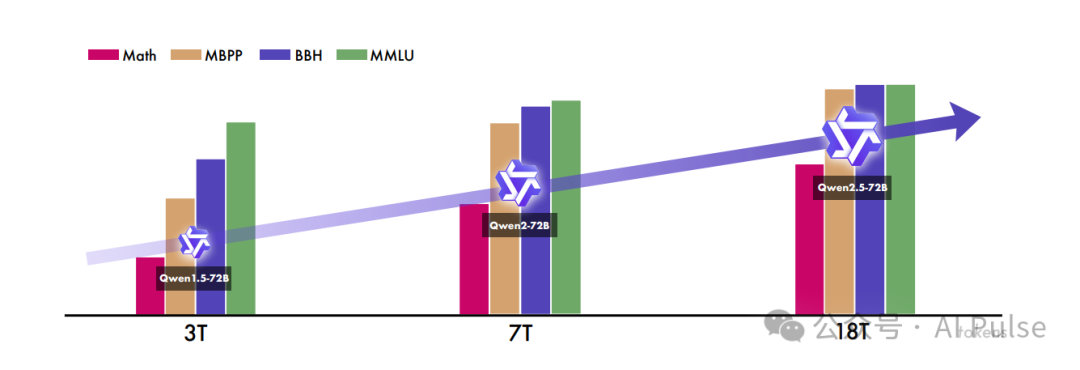
▸ 采用18万亿tokens超大规模预训练("T"代表万亿量级)
▸ 上下文窗口扩展至128K tokens,长文本生成能力突破8K tokens
核心能力飞跃提升
▸ 结构化数据处理专家:表格解析与JSON格式生成准确率提升40%
▸ 多语言大师:支持中/英/法/西等29种语言的无缝切换
▸ 角色扮演大师:系统提示适配性增强300%,打造更自然的对话体验
技术突破三大维度
1️⃣ 语义理解革命:通过多模态数据预训练,实现文本、图像、音频的联合表征
2️⃣ 人机协作进化:工具调用响应速度提升60%,AI Agent交互更智能
3️⃣ 行业适配升级:金融文本生成、代码解释等专业场景准确率达SOTA水平
论文:2025.01.03V2_Qwen2.5 Technical Report
论文地址:https://arxiv.org/pdf/2412.15115
代码:https://github.com/QwenLM/Qwen2.5
01
—
背景和贡献
随着AGI(人工通用智能)的快速发展,大型语言模型(LLM)在语言理解、生成和推理方面展现出“涌现能力”。模型规模扩大、数据质量提升及训练方法优化(如预训练+微调+RLHF)是主要驱动力。
开放权重模型的崛起:Llama、Mistral等开源模型降低了LLM的使用门槛,促进了社区协作与创新。Qwen系列作为中文社区的代表模型,持续迭代以满足多样化需求。
贡献:
-
模型规模扩展:Qwen2.5覆盖0.5B到72B参数,并引入MoE(混合专家)变体(Turbo和Plus),在资源受限场景下提供高性价比选择。
-
数据质量提升:预训练数据从7万亿token增至18万亿,重点优化数学、代码和知识领域的数据混合与过滤。后训练阶段引入百万级有监督微调(SFT)样本,结合离线RL(DPO)和在线RL(GRPO)增强人类偏好对齐能力。
-
功能改进:支持更长文本生成(8K→1M token)、结构化数据解析(JSON/表格)、工具调用等,提升实际应用能力。
02
—
主要方法
2.1.架构与分词器
-
基础架构:基于Transformer解码器,采用GQA(分组查询注意力)、SwiGLU激活函数、RoPE(旋转位置编码)等技术优化计算效率与长上下文处理。
-
MoE架构:将标准FFN层替换为多专家层,结合细粒度专家分割和共享路由机制,提升模型性能。
-
分词器:基于BBPE(字节级BPE),词汇量151,643,新增工具调用专用控制token,统一各模型分词策略。
2.2.预训练
数据优化:
-
高质量数据过滤与多维度评分。
-
引入数学(Qwen2.5-Math)和代码(Qwen2.5-Coder)领域专用数据。
-
合成数据生成与严格过滤。
长上下文训练:
-
分阶段扩展上下文长度(4K→128K token),采用YARN和DCA(双块注意力)技术提升长序列建模能力。
-
Qwen2.5-Turbo支持百万token上下文,通过渐进式训练策略平衡效率与性能。
2.3.后训练
-
有监督微调(SFT):针对长文本生成、数学推理、代码生成等任务构建专用数据集,结合反向翻译、代码验证、多语言对齐等技术提升模型能力。
-
两阶段强化学习:离线RL(DPO):基于执行反馈和答案匹配优化数学、代码等确定性任务。在线RL(GRPO):利用奖励模型(RM)优化生成结果的真理性、无害性、简洁性等人类偏好指标。
03
—
实验与结果
3.1.基准测试表现
-
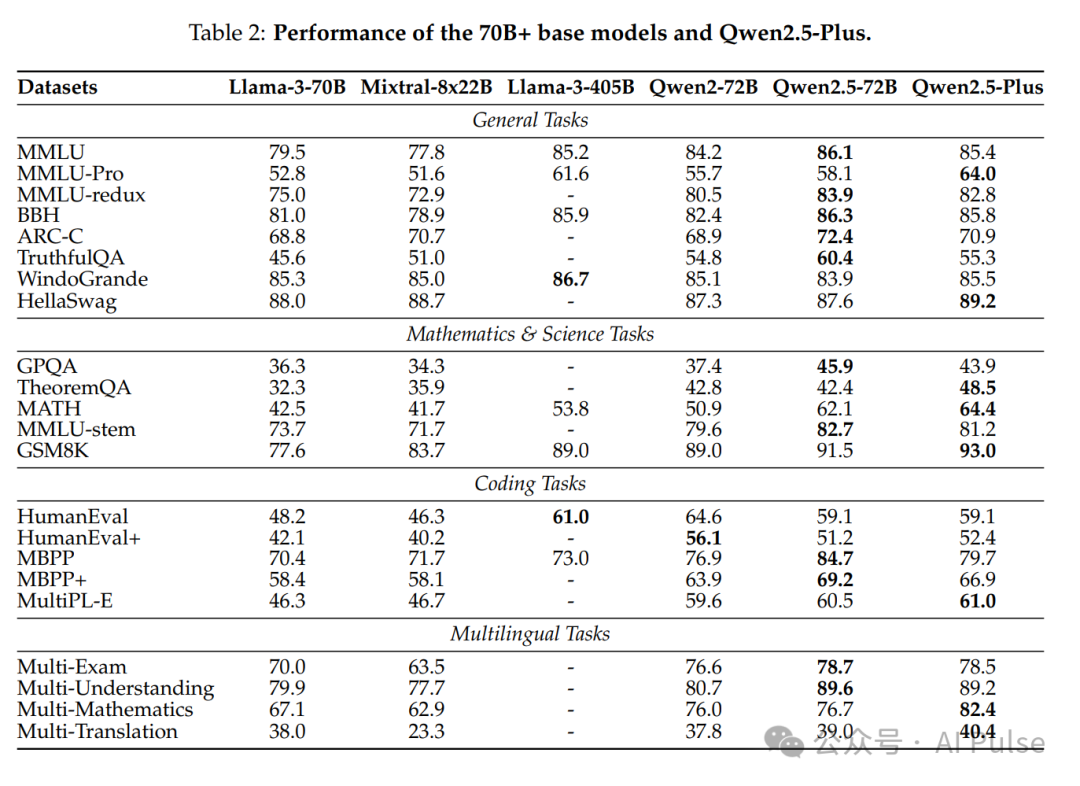
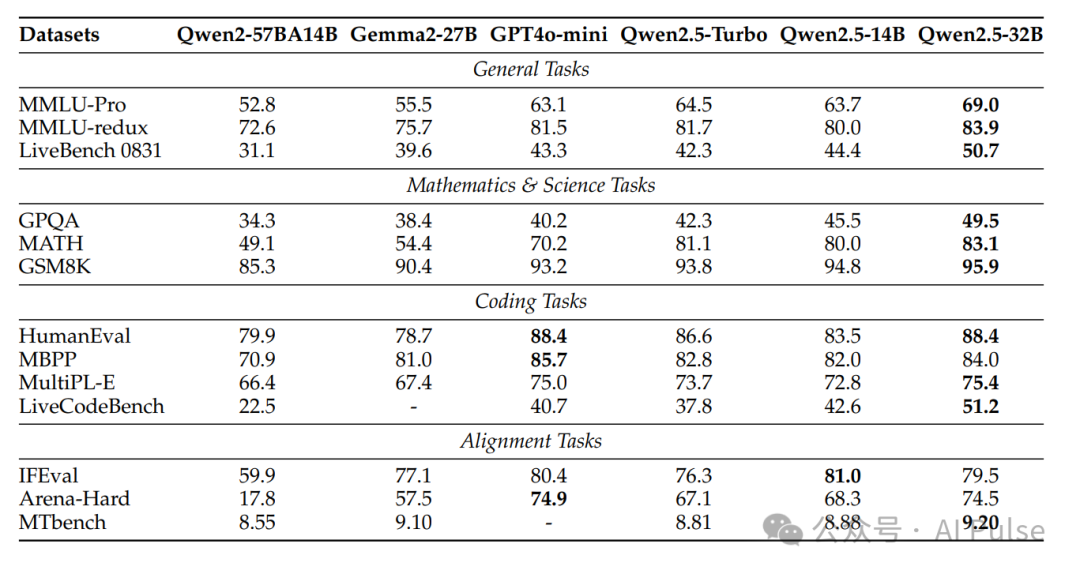
通用任务:Qwen2.5-72B-Instruct在MMLU、BBH等基准上超越Llama-3-405B,部分任务领先(如MMLU-Pro)。
-
数学与代码:MATH数据集上,Qwen2.5-72B得分62.1(对比Llama-3-405B的53.8)。HumanEval代码生成任务中,Qwen2.5-72B达到86.6分,接近GPT-4o-mini(88.4)。
-
多语言能力:在阿拉伯语、日语等多语言MMLU变体上表现优异,跨语言迁移能力显著。
3.2.长上下文能力
-
RULER基准:Qwen2.5-72B-Instruct在128K token长度下准确率达88.4%,优于GPT-4(81.2%)。
-
Passkey检索:Qwen2.5-Turbo在1M token长度下实现100%准确率,推理速度提升3.2-4.3倍。
3.3.成本
Qwen2.5-Turbo(MoE)在多项任务中性能接近GPT-4o-mini,但训练和推理成本显著更低。
04
—
结论
Qwen2.5通过数据扩展、架构优化和强化学习,在性能、成本、多任务支持上达到当前开源模型的领先水平,尤其在数学、代码和长上下文任务中表现突出。Qwen2.5提供从0.5B到72B的全系列模型,满足边缘计算到云端服务的多样化需求,并作为基础模型支持领域专用模型(如Qwen2.5-Math)。
未来方向将持续优化基础模型,提升数据多样性与质量。开发多模态统一框架,融合文本、视觉、听觉等多模态信息。增强模型推理能力,探索科学探索与复杂问题解决的新范式。
Qwen2.5的发布进一步推动了开源LLM的边界,为学术研究与工业应用提供了高效、灵活的解决方案。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 939
939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











