







李升伟 整理
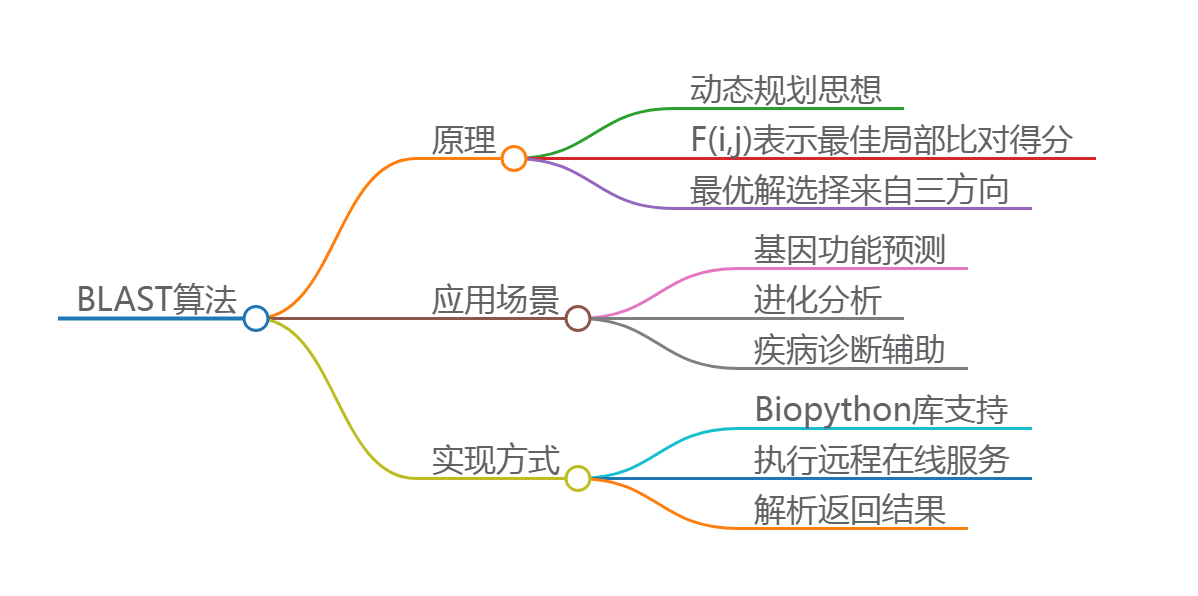
BLAST算法的原理
BLAST(Basic Local Alignment Search Tool)是一种广泛应用于生物信息学领域中的序列比对工具。其核心目标是比较查询序列与数据库中的已知序列,寻找相似区域并评估它们之间的关系。该算法基于动态规划的思想,但在实际操作中进行了优化以提高效率。
具体来说,在BLAST算法中,F(i, j) 表示两个序列在位置i和j处的最佳局部比对得分。此分数由三个可能的方向决定:水平方向、垂直方向以及对角线方向。通过对这三个来源取最大值的方式,能够确保每一步的选择都是最优解,从而使得整体结果尽可能接近全局最佳匹配。
BLAST的应用场景
1. 基因功能预测
当科学家发现一个新的未知DNA片段时,他们通常会利用BLAST将其与现有的基因组数据库相比较。如果找到了高度同源的已知基因,则可以根据这些已知基因的功能推测新基因的作用。
2. 进化分析
通过对比不同物种间的蛋白质或核酸序列差异程度,研究者可以构建系统发育树来揭示各物种间亲缘关系远近情况。这种类型的分析有助于理解生命起源及其演化过程。
3. 疾病诊断辅助
某些遗传性疾病是由特定突变引起的;因此,医生可能会使用BLAST查找患者样本中存在的异常变异位点,并进一步确认是否存在致病风险较高的改变。
Python实现BLAST算法简介
为了便于科研人员快速上手并灵活运用这一强大技术手段,社区开发出了专门针对生物学数据分析需求设计而成的强大软件包——Biopython。借助于这个开源项目所提供的接口函数模块,我们可以轻松完成从读入FASTA格式文件到执行远程在线服务直至解析返回结果等一系列复杂任务链路的操作流程。
下面展示了一段简单的代码示例,演示如何调用 Biopython 中的相关方法来进行本地或者网络模式下的基本搜索工作:
Python
from Bio.Blast import NCBIWWW
from Bio.Seq import Seq
sequence_data = "ATGGCCATTGTAATGGGCCGCTGAAAGGGTGCCCGATAG"
query_sequence = Seq(sequence_data)
result_handle = NCBIWWW.qblast("blastn", "nt", query_sequence)
with open("my_blast.xml", "w") as save_file:
save_file.write(result_handle.read())
以上脚本首先创建了一个代表待测核苷酸串的对象实例 query_sequence ,接着向NCBI服务器提交请求发起一次标准型 nucleotide-nucleotide blast作业并将所得XML文档保存至磁盘指定路径下以便后续深入挖掘解读其中蕴含的信息价值所在。
(来自CSDN C知道)

















 6366
6366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









