






pytorch的DataLoader和Dataset可方便处理数据集和实现Mini-batch
Epoch
Batch-Size
Iteration:1个iteration等于使用batchsize个样本训练一次
shuffle
构造Dataset的时候2种方法
1.所有数据加载进来
2. 读入标签/文件名(数据集大)
torchvision提供了一些数据集可方便调用
使用Mini-batch实现分类,并测试每个epoch的准确度
import torch
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.data import Dataset,DataLoader
from sklearn.model_selection import train_test_split
'''
Dataset是一个抽象函数,不能直接实例化,所以我们要创建一个自己类,继承Dataset
继承Dataset后我们必须实现三个函数:
__init__()是初始化函数,之后我们可以提供数据集路径进行数据的加载
__getitem__()帮助我们通过索引找到某个样本
__len__()帮助我们返回数据集大小
'''
xy = np.loadtxt('./diabetes.csv', delimiter=',', dtype=np.float32)
x=xy[:, :-1] # 最后一列不要 ,向量形式
y=xy[:, [-1]] # 只要最后一列,且为矩阵形式
Xtrain, Xtest, Ytrain, Ytest = train_test_split(x,y,test_size=0.3)
Xtest = torch.from_numpy(Xtest)
Ytest = torch.from_numpy(Ytest)
class Multiple_DimensionModel_Dataset(Dataset):
def __init__(self,data,label):
self.len=data.shape[0] #数据有几行
self.x_data = torch.from_numpy(data)
self.y_data = torch.from_numpy(label)
def __getitem__(self, index):
return self.x_data[index],self.y_data[index]
def __len__(self):
return self.len
class Multiple_DimensionModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear1=torch.nn.Linear(8,64)
self.linear2=torch.nn.Linear(64,32)
self.linear3=torch.nn.Linear(32,1)
self.sigmoid=torch.nn.Sigmoid() # 将其看作是网络的一层,而不是简单的函数使用
def forward(self,x):
x=self.sigmoid(self.linear1(x))
x=self.sigmoid(self.linear2(x))
x=self.sigmoid(self.linear3(x))
return x
def test():
with torch.no_grad():
y_pred=model(Xtest)
y_pred_label = torch.where(y_pred >= 0.5, torch.tensor([1.0]), torch.tensor([0.0]))
acc = torch.eq(y_pred_label, Ytest).sum().item() / Ytest.size(0)
#print("test acc:", acc)
acc_list.append(acc)
dataset = Multiple_DimensionModel_Dataset(Xtrain,Ytrain)
train_loader=DataLoader(dataset=dataset,batch_size=64,shuffle=True,num_workers=0)
model=Multiple_DimensionModel()
criterion=torch.nn.BCELoss(size_average=True)
optimizer=torch.optim.SGD(model.parameters(),lr=0.1)
epoch_list=[]
cost_list=[]
acc_list=[]
count=0
if __name__ == "__main__":
for epoch in range(10000):
train_loss =0.0
for i,data in enumerate(train_loader,0):
inputs,labels=data
y_pred=model(inputs)
loss=criterion(y_pred,labels)
print(epoch,i,loss.item())
train_loss+=loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
count=i
epoch_list.append(epoch)
cost_list.append(train_loss/count) # 使用batchsize平均loss
test()
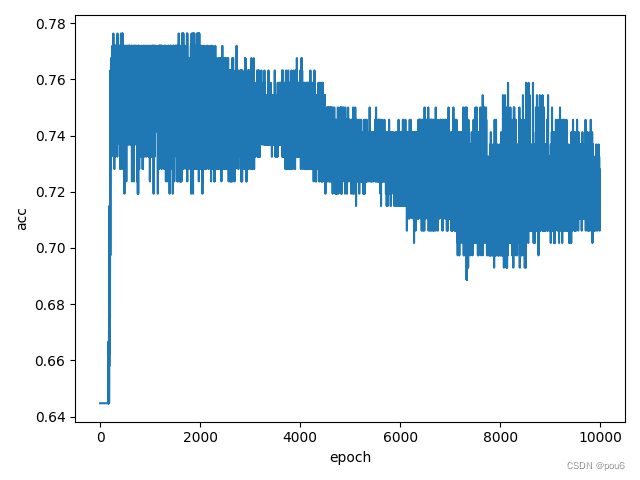
plt.plot(epoch_list, acc_list)
plt.ylabel('acc')
plt.xlabel('epoch')
plt.show()
plt.plot(epoch_list,cost_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
















 2701
2701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









