







目录
本文将着重讲述标注数据向Yolo数据格式的转化,并重新梳理了 labelme/labelimg 打标签、转换Yolo训练格式、一键划分数据集、模型训练的全过程。
一、代码功能
-
自动文件匹配:智能匹配图片和标签文件,支持多种图片格式(jpg/png/webp)
-
数据验证:自动跳过无效标注(非矩形标注、无效坐标等)
-
类别自动映射:根据标注文件自动生成
classes.txt -
灵活划分比例:支持自定义训练集/验证集/测试集比例
-
完整日志输出:显示处理进度和最终统计信息
-
随机种子支持:保证可重复的实验结果
-
高效处理:使用 Pathlib 和 shutil 进行高效文件操作
-
动态选择解析方法:根据标注文件的后缀(
.json或.xml)动态选择对应的解析方法。
二、数据准备
1)labelme/labelimg 矩形标注准备
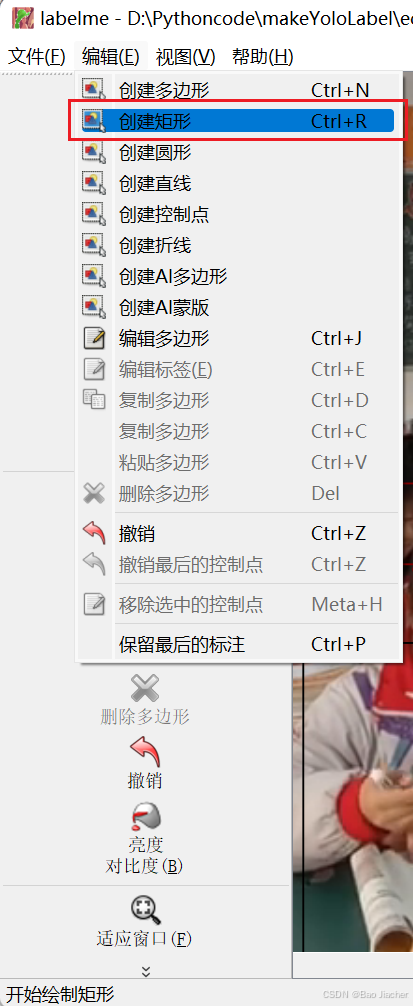
先用 labelme/labelimg 的矩形工具框选分类对象,注意是下图中所示的“创建矩形”。
2)符合程序识别的文件结构准备
标注完成数据之后的文件结构如下,要求文件夹A下必须有两个子文件夹,其名称严格为 images、labels:
文件夹A/
├── images/
│ ├── 001.jpg
│ ├── 002.png
│ └── 003.webp
└── labels/
├── 001.json
├── 002.json
└── 003.json其中,images 文件夹存放各种类型的图片,labels 文件夹存放 json/xml 格式的标注文件。
三、代码运行
下述代码只需要在 if __name__ == "__main__" : 中进行修改即可:
import json
import random
import shutil
from pathlib import Path
from sklearn.model_selection import train_test_split
import xml.etree.ElementTree as ET
class LabelmeToYOLOConverter:
def __init__(self, class_map=None):
self.class_map = class_map or {}
self.reverse_class_map = {v: k for k, v in self.class_map.items()}
def process_dataset(self,
input_dir: str,
output_dir: str,
test_ratio: float = 0.15,
val_ratio: float = 0.15,
seed: int = 42):
"""主处理函数
参数:
input_dir: 原始数据集路径(文件夹A)
output_dir: 输出路径(文件夹B)
test_ratio: 测试集比例 (0-1)
val_ratio: 验证集比例 (0-1)
seed: 随机种子
"""
# 初始化路径
input_path = Path(input_dir)
outpu 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5084
5084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









