







💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
专栏目录: 《YOLOv5入门 + 改进涨点》专栏介绍 & 专栏目录 |目前已有40+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进
CARAFE(内容感知特征重组)是一种新型的特征上采样算子,它具有大视野范围,能够聚合较大感受野内的上下文信息;能够实现特定实例的内容感知处理;同时,它是一种轻量级且计算快速的算子,可以轻松集成到现代网络架构中。在目标检测、实例/语义分割和修复的标准基准上进行全面评估,CARAFE显示出一致且实质性的增益,而计算开销可以忽略不计。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
目录
1. 原理

论文地址: CARAFE: Content-Aware ReAssembly of FEatures——点击即可跳转_
官方代码:官方代码仓库——点击即可跳转
CARAFE(内容感知特征重组)是一种特征上采样算子,旨在提高对象检测、实例分割和语义分割等密集预测任务的性能。下面是其主要原理的详细解释:
CARAFE 的关键原理
内容感知上采样:
-
与使用固定内核的传统方法(如双线性插值或反卷积)不同,CARAFE 根据输入内容生成自适应内核。这使 CARAFE 能够更有效地处理特征图中的局部变化。
-
自适应内核是使用轻量级全卷积模块即时生成的,这使得该过程更加高效。
大接受场:
-
CARAFE 可以从大接受场聚合信息。这与通常只考虑小子像素邻域的传统方法形成对比。
-
这种更大的上下文使 CARAFE 能够捕获更多语义信息,这对于实例分割等任务至关重要。
轻量级且高效:
-
尽管 CARAFE 对内容的处理非常复杂,但其计算开销却很小。例如,使用 256 个通道对特征图进行两倍上采样仅增加约 199k FLOP(浮点运算),而反卷积层则增加 1180k FLOP。
-
这种效率使 CARAFE 适合集成到现代网络架构中,而不会显著增加计算成本。
工作机制
CARAFE 的过程可以分为两个主要步骤:
内核预测模块:
-
通道压缩器:降低输入特征图的通道维度以减少计算负荷。
-
内容编码器:对压缩特征图的内容进行编码以生成重组内核。此模块使用具有指定内核大小的卷积层。
-
内核归一化器:应用 softmax 函数对内核进行归一化,确保其值总和为 1。此归一化步骤对于在重组过程中保持特征图的平均值至关重要。
内容感知重组模块:
-
使用预测的重组内核对预定义局部区域内的输入特征进行加权组合。
-
此重组过程允许以内容感知的方式对特征图进行上采样,从而增强上采样特征中的语义信息。
优于传统方法
-
最近邻和双线性插值:这些方法仅考虑空间距离,并且仅限于小邻域,无法捕获丰富的语义信息。
-
反卷积:尽管反卷积具有自适应性,但它会在整个图像上应用相同的内核,这限制了其响应局部内容变化的能力。此外,使用大内核时计算成本很高。
应用和性能
CARAFE 已在多个基准测试中进行了评估,并在各种任务中表现出持续的改进:
-
对象检测:在 MS COCO 上将 Faster R-CNN 的性能提高了 1.2% AP。
-
实例分割:在 MS COCO 上将 Mask R-CNN 的性能提高了 1.3% AP。
-
语义分割:在 ADE20k 上将 UperNet 的性能提高了 1.8% mIoU。
-
图像修复:在 Places 上将 Global&Local 的 PSNR 提高了 1.1 dB。
这些改进证明了 CARAFE 的有效性和作为未来密集预测任务研究基本构建块的潜力。
总之,CARAFE 是一个强大而高效的特征上采样运算符,它通过利用内容感知内核和大型感受野来解决传统方法的局限性,使其成为增强各种计算机视觉任务性能的宝贵工具。
2. CARAFE 的代码实现
2.1 将CARAFE 添加到YOLOv5中
关键步骤一: 将下面代码粘贴到/yolov5-6.1/models/common.py文件中
class CARAFE(nn.Module):
# CARAFE: Content-Aware ReAssembly of FEatures https://arxiv.org/pdf/1905.02188.pdf
def __init__(self, c1, c2, kernel_size=5, up_factor=2):
super(CARAFE, self).__init__()
self.kernel_size = 5
self.up_factor = 2
self.down = nn.Conv2d(c1, c1 // 4, 1)
self.encoder = nn.Conv2d(c1 // 4, self.up_factor ** 2 * self.kernel_size ** 2, self.kernel_size, 1,
self.kernel_size // 2)
self.out = nn.Conv2d(c1, c2, 1)
def forward(self, x):
N, C, H, W = x.size()
# N,C,H,W -> N,C,delta*H,delta*W
# kernel prediction module
kernel_tensor = self.down(x) # (N, Cm, H, W)
kernel_tensor = self.encoder(kernel_tensor) # (N, S^2 * Kup^2, H, W)
kernel_tensor = F.pixel_shuffle(kernel_tensor, self.up_factor) # (N, S^2 * Kup^2, H, W)->(N, Kup^2, S*H, S*W)
kernel_tensor = F.softmax(kernel_tensor, dim=1) # (N, Kup^2, S*H, S*W)
kernel_tensor = kernel_tensor.unfold(2, self.up_factor, step=self.up_factor) # (N, Kup^2, H, W*S, S)
kernel_tensor = kernel_tensor.unfold(3, self.up_factor, step=self.up_factor) # (N, Kup^2, H, W, S, S)
kernel_tensor = kernel_tensor.reshape(N, self.kernel_size ** 2, H, W,
self.up_factor ** 2) # (N, Kup^2, H, W, S^2)
kernel_tensor = kernel_tensor.permute(0, 2, 3, 1, 4) # (N, H, W, Kup^2, S^2)
# content-aware reassembly module
# tensor.unfold: dim, size, step
x = F.pad(x, pad=(self.kernel_size // 2, self.kernel_size // 2, self.kernel_size // 2, self.kernel_size // 2),
mode='constant', value=0) # (N, C, H+Kup//2+Kup//2, W+Kup//2+Kup//2)
x = x.unfold(2, self.kernel_size, step=1) # (N, C, H, W+Kup//2+Kup//2, Kup)
x = x.unfold(3, self.kernel_size, step=1) # (N, C, H, W, Kup, Kup)
x = x.reshape(N, C, H, W, -1) # (N, C, H, W, Kup^2)
x = x.permute(0, 2, 3, 1, 4) # (N, H, W, C, Kup^2)
out_tensor = torch.matmul(x, kernel_tensor) # (N, H, W, C, S^2)
out_tensor = out_tensor.reshape(N, H, W, -1)
out_tensor = out_tensor.permute(0, 3, 1, 2)
out_tensor = F.pixel_shuffle(out_tensor, self.up_factor)
out_tensor = self.out(out_tensor)
# print("up shape:",out_tensor.shape)
return out_tensor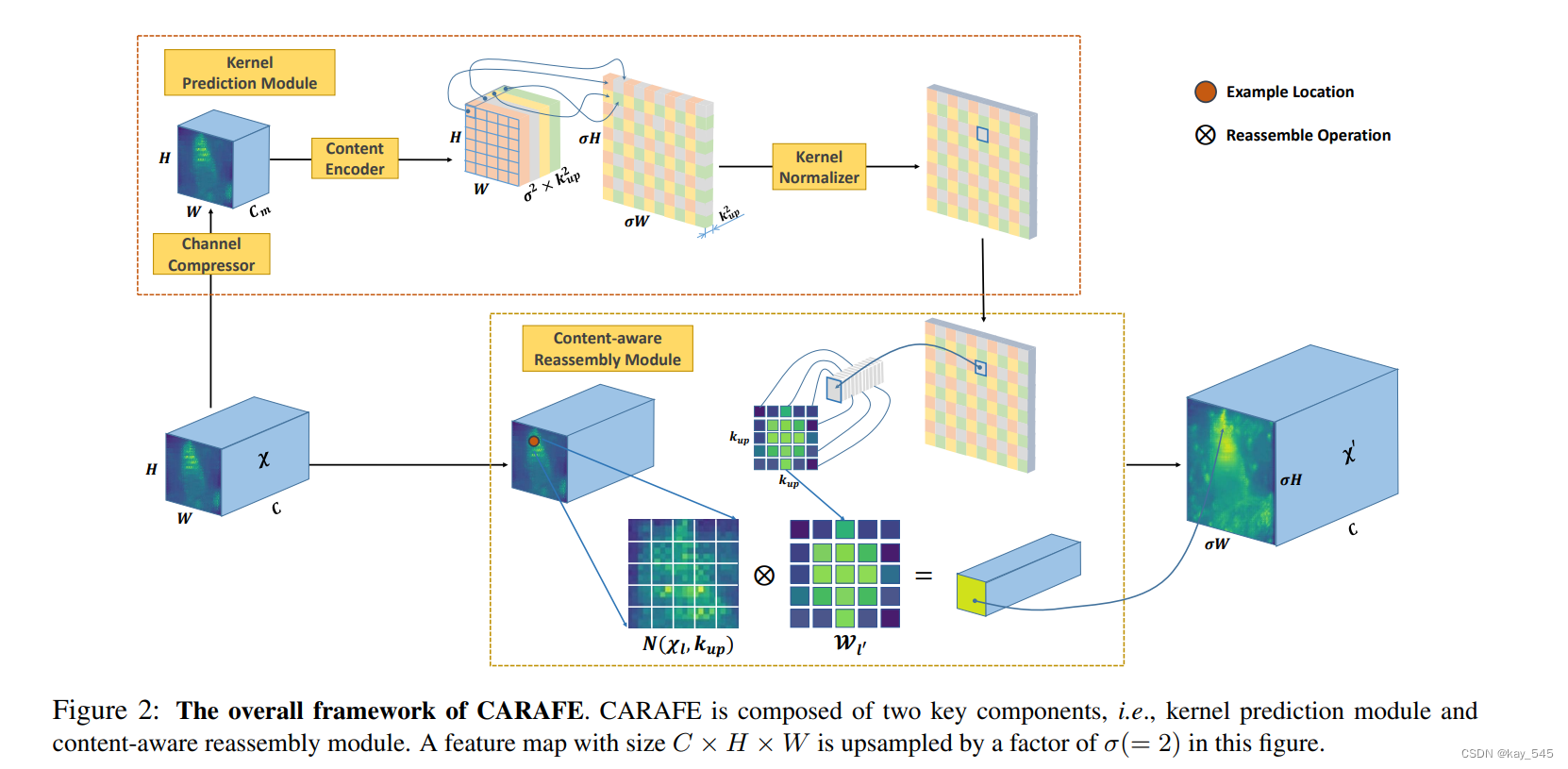
2.2 新增yaml文件
关键步骤二:在下/yolov5-6.1/models下新建文件 yolov5_CARAFE .yaml并将下面代码复制进去
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, CARAFE, [512,3,2]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, CARAFE, [256,3,2]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]温馨提示:本文只是对yolov5l基础上添加模块,如果要对yolov5n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple。
# YOLOv5n
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
# YOLOv5s
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# YOLOv5l
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# YOLOv5m
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
# YOLOv5x
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple2.3 注册模块
关键步骤三:在yolo.py中注册 添加“CARAFE ",

2.4 执行程序
在train.py中,将cfg的参数路径设置为yolov5_CARAFE .yaml的路径

建议大家写绝对路径,确保一定能找到
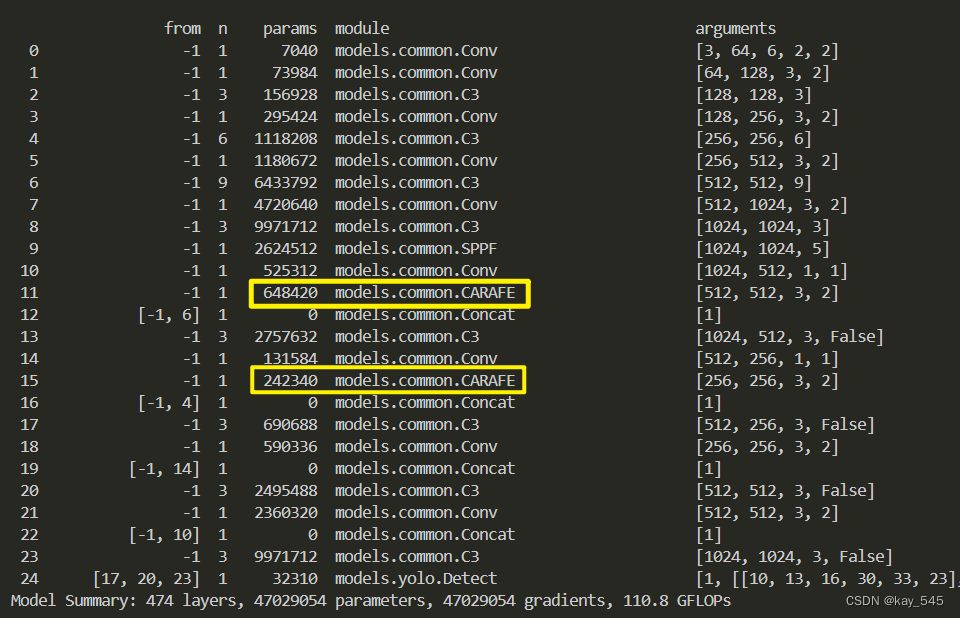
🚀运行程序,如果出现下面的内容则说明添加成功🚀
3. 完整代码分享
https://pan.baidu.com/s/1j-WgZ_rrWxCW5RCE_z0K6A?pwd=dtea提取码: dtea
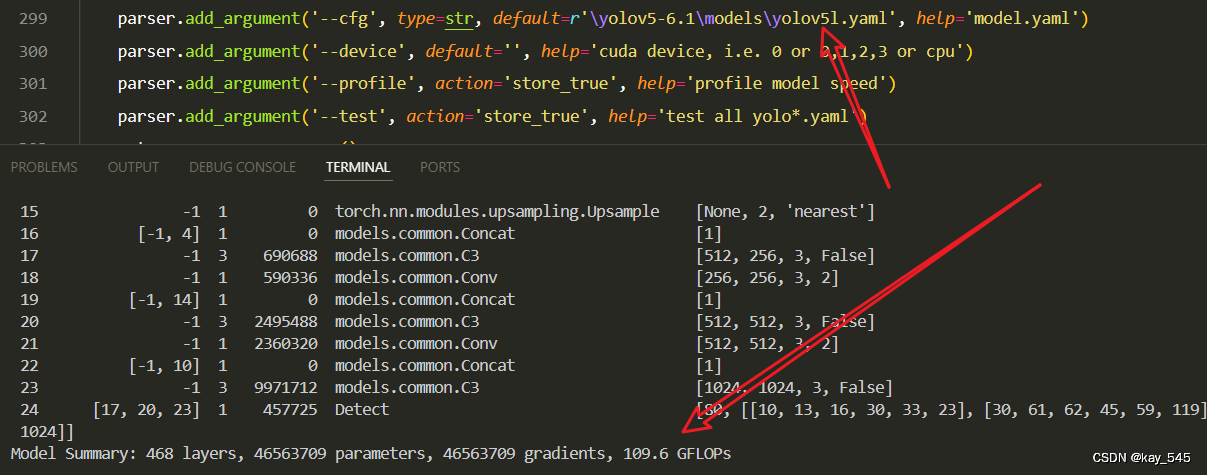
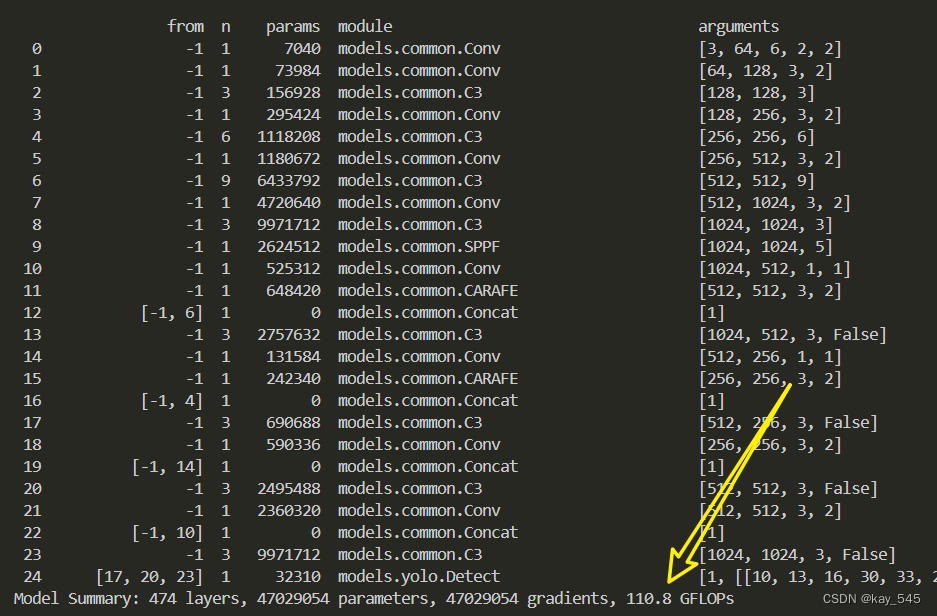
4. GFLOPs
关于GFLOPs的计算方式可以查看:百面算法工程师 | 卷积基础知识——Convolution
未改进的GFLOPs
改进后的GFLOPs
5. 进阶
可以和损失函数的修改相结合,效果可能会更好
YOLOv5改进 | 损失函数 | EIoU、SIoU、WIoU、DIoU、FocusIoU等多种损失函数
6. 总结
CARAFE(内容感知特征重组)是一种创新的特征上采样运算符,它通过生成自适应的内容感知内核来重组输入特征,从而增强密集预测任务。与传统的固定内核方法相比,此方法可从大型接受场中聚合信息,从而能够捕获更丰富的语义上下文。CARAFE 效率高,计算开销极小,并且可以无缝集成到现有的神经网络架构中,从而显著提高对象检测、实例分割和语义分割等任务的性能。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











