







秋招面试专栏推荐 :深度学习算法工程师面试问题总结【百面算法工程师】——点击即可跳转
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
专栏目录: 《YOLOv5入门 + 改进涨点》专栏介绍 & 专栏目录 |目前已有50+篇内容,内含各种Head检测头、损失函数Loss、Backbone、Neck、NMS等创新点改进
在视觉理解问题中,上下文信息对于语义分割和目标检测等任务是至关重要的。本文介绍一种名为交错的网络(CCNet),以非常高效和有效的方式获取全图像的上下文信息。具体来说,对于每个像素,一个新颖的交错注意力模块在其交错路径上收集所有像素的上下文信息。通过进一步采用递归操作,每个像素最终能够捕获整个图像的依赖关系。总的来说,CCNet具有以下优点:1)对GPU内存友好。与非局部块相比,所提出的递归交错注意力模块所需的GPU内存使用量减少了11倍。2)高计算效率。递归的交错注意力模块显著减少了大约85%的非局部块的计算量。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
专栏地址:YOLOv5改进+入门——持续更新各种有效涨点方法——点击即可跳转 订阅专栏学习不迷路
目录
2. 将CrissCrossAttention添加到YOLOv5中
1.原理

论文地址:CCNet: Criss-Cross Attention for Semantic Segmentation——点击即可跳转
官方代码: 官方代码仓库——点击即可跳转
CCNet,即交叉网络,旨在高效收集全图上下文信息,用于语义分割任务。下面是其主要原理的简单解释,无需使用公式:
交叉注意力模块:
-
CCNet 的核心创新是交叉注意力模块。该模块沿着特征图中每个像素的水平和垂直路径收集上下文信息。
-
与使用密集连接的传统方法不同,交叉注意力模块使用稀疏连接,大大降低了计算复杂度和内存使用量。
-
对于每个像素,模块仅沿着包含相同行和列的交叉路径创建注意力图。与全连接方法相比,这减少了连接数。
循环操作:
-
为了捕获全图依赖关系,CCNet 采用循环操作。这意味着连续多次应用交叉注意力模块。
-
第一遍收集水平和垂直线上的信息。后续的传递继续聚合更多的上下文,最终使每个像素都能从整个图像中收集信息。
-
循环机制确保注意力信息逐渐丰富,从而实现更有效的上下文聚合。
效率:
-
通过使用交叉方法,与非局部块相比,CCNet 在计算需求和内存使用方面均实现了大幅降低。
-
具体而言,它显著减少了浮点运算 (FLOP) 的数量和内存使用量,使其更适用于高分辨率图像和大规模数据集。
类别一致性损失:
-
为了进一步增强交叉注意力模块学习到的特征的判别能力,CCNet 引入了类别一致性损失。
-
该损失函数确保属于同一类别的像素的特征在特征空间中靠得更近,而来自不同类别的像素的特征相距较远。
性能:
-
CCNet 已被证明在各种语义分割基准测试中实现了最先进的性能,包括 Cityscapes、ADE20K 等。这证明了其在利用全图像上下文信息方面的有效性。
总体而言,CCNet 脱颖而出,提供了一种高效且有效地聚合每个像素的全图像上下文的方法,从而提高了语义分割任务的性能,同时提高了计算和内存效率。
2. 将CrissCrossAttention添加到YOLOv5中
2.1 CrissCrossAttention的代码实现
关键步骤一: 将下面代码添加到 yolov5/models/common.py中
from torch.nn import Softmax
def INF(B,H,W):
return -torch.diag(torch.tensor(float("inf")).repeat(H),0).unsqueeze(0).repeat(B*W,1,1)
class CrissCrossAttention(nn.Module):
""" Criss-Cross Attention Module"""
def __init__(self, in_dim):
super(CrissCrossAttention,self).__init__()
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.softmax = Softmax(dim=3)
self.INF = INF
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self, x):
m_batchsize, _, height, width = x.size()
proj_query = self.query_conv(x)# AIEAGNY
proj_query_H = proj_query.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height).permute(0, 2, 1)
proj_query_W = proj_query.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width).permute(0, 2, 1)
proj_key = self.key_conv(x)
proj_key_H = proj_key.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height)
proj_key_W = proj_key.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width)
proj_value = self.value_conv(x)
proj_value_H = proj_value.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height)
proj_value_W = proj_value.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width)
energy_H = (torch.bmm(proj_query_H, proj_key_H)+self.INF(m_batchsize, height, width)).view(m_batchsize,width,height,height).permute(0,2,1,3)
energy_W = torch.bmm(proj_query_W, proj_key_W).view(m_batchsize,height,width,width)
concate = self.softmax(torch.cat([energy_H, energy_W], 3))
att_H = concate[:,:,:,0:height].permute(0,2,1,3).contiguous().view(m_batchsize*width,height,height)
#print(concate # AIEAGNY)
#print(att_H)
att_W = concate[:,:,:,height:height+width].contiguous().view(m_batchsize*height,width,width)
out_H = torch.bmm(proj_value_H, att_H.permute(0, 2, 1)).view(m_batchsize,width,-1,height).permute(0,2,3,1)
out_W = torch.bmm(proj_value_W, att_W.permute(0, 2, 1)).view(m_batchsize,height,-1,width).permute(0,2,1,3)
#print(out_H.size(),out_W.size())
return self.gamma*(out_H + out_W) + xCCNet处理图像的主要流程如下:
1. 输入图像
-
首先,将输入图像传入一个标准的卷积神经网络(CNN)以提取初始的特征图。这些特征图包含了图像的低级和高级特征。
2. Criss-Cross Attention Module
-
初始特征图:将从CNN提取的特征图传入Criss-Cross Attention模块。
-
水平和垂直路径:Criss-Cross Attention模块沿每个像素的水平和垂直路径聚合上下文信息。具体来说,它为每个像素生成一个注意力图,注意力图仅包括同一行和同一列的像素连接,这样可以显著减少计算量和内存使用。
-
加权和操作:根据注意力图,将其他位置的上下文信息加权和,结合到当前像素的位置特征中。
3. 递归操作
-
第一次递归:初次通过Criss-Cross Attention模块收集水平和垂直方向的上下文信息。
-
重复应用:将第一次递归操作的结果传入第二次Criss-Cross Attention模块,通过重复应用这个模块,逐步收集更多的上下文信息,最终使得每个像素都能从整个图像中收集到上下文信息。
-
共享参数:多次递归过程中,Criss-Cross Attention模块的参数是共享的,这样可以保持模型的紧凑性。
4. 融合特征
-
组合信息:经过递归操作后,整合所有位置的上下文信息,将增强的特征图传递给后续的网络层。
5. 类别一致损失(Category Consistent Loss)
-
损失函数:引入类别一致损失,进一步增强特征的判别能力。该损失函数使得同类别像素的特征向量在特征空间中更接近,不同类别的特征向量更远。
-
训练目标:通过这个损失函数,网络可以更准确地区分不同类别的像素,提高分割的准确性。
6. 输出预测
-
最终分割图:将处理后的特征图通过一系列卷积层和上采样层,生成最终的语义分割图。每个像素被分配一个类别标签,表示它属于哪个语义类别。
7. 结果评估
-
评价指标:通过标准的评价指标在测试数据集上评估模型性能,验证模型在实际应用中的效果。
总结
CCNet通过引入Criss-Cross Attention模块和递归操作,有效地聚合了全图像的上下文信息,大大提升了语义分割的性能,同时显著减少了计算资源的消耗。这使得CCNet在多种大规模语义分割基准测试中取得了领先的性能。

2.2 新增yaml文件
关键步骤二:在下/yolov5-6.1/models下新建文件 yolov5_CCA.yaml并将下面代码复制进去
- 目标检测yaml文件 ,可尝试将CrissCrossAttention放在不同的位置
# YOLOv5 🚀 by YOLOAir, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, CrissCrossAttention, [1024]],
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
- 语义分割yaml文件
# YOLOv5 🚀 by YOLOAir, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, CrissCrossAttention, [1024]],
[[17, 20, 24], 1, Segment, [nc, anchors, 32, 256]], # Detect(P3, P4, P5)
]
温馨提示:本文只是对yolov5基础上添加模块,如果要对yolov5n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple。
# YOLOv5n
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
# YOLOv5s
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# YOLOv5l
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# YOLOv5m
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
# YOLOv5x
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple2.3 注册模块
关键步骤三:在yolo.py的parse_model函数中注册 添加“CrissCrossAttention",
elif m is CrissCrossAttention:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, *args[1:]]
2.4 执行程序
在train.py中,将cfg的参数路径设置为yolov5_CCA.yaml的路径
建议大家写绝对路径,确保一定能找到

🚀运行程序,如果出现下面的内容则说明添加成功🚀
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 229245 Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
YOLOv5s summary: 214 layers, 7235389 parameters, 7235389 gradients, 16.6 GFLOPs3. 完整代码分享
https://pan.baidu.com/s/1kq7z3KDkj1Zc5Z-YowVC9A?pwd=zrbg提取码: zrbg
4. GFLOPs
关于GFLOPs的计算方式可以查看:百面算法工程师 | 卷积基础知识——Convolution
未改进的GFLOPs
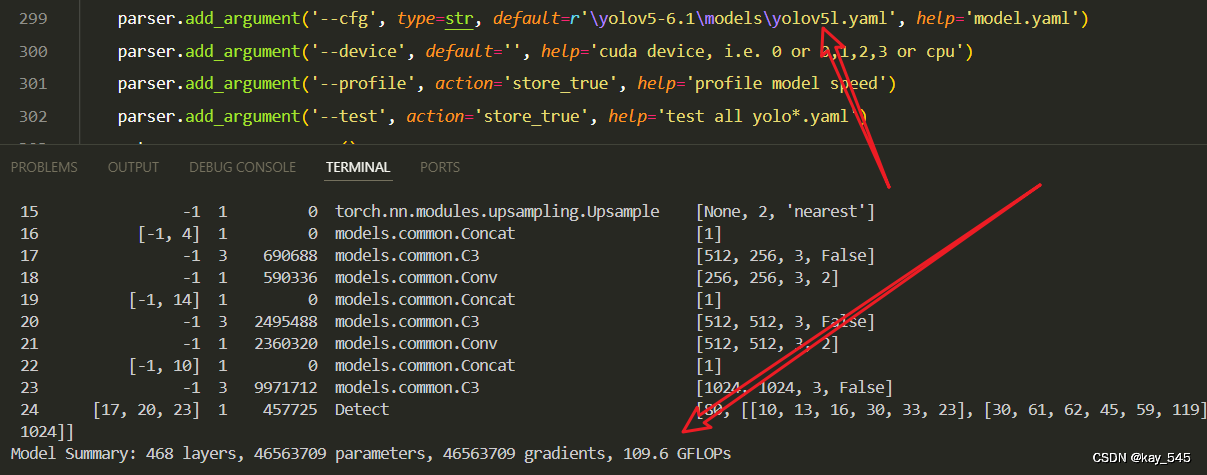
改进后的GFLOPs
现在手上没有卡了,等过段时候有卡了把这补上,需要的同学自己测一下

5. 进阶
可以结合损失函数或者卷积模块进行多重改进
YOLOv5改进 | 损失函数 | EIoU、SIoU、WIoU、DIoU、FocuSIoU等多种损失函数——点击即可跳转
6. 总结
CCNet的主要原理是通过引入Criss-Cross Attention模块,沿着每个像素的水平和垂直路径高效地聚合全图像的上下文信息,并通过递归操作进一步整合全局特征,同时结合类别一致损失增强特征的判别能力,从而在语义分割任务中以较低的计算和内存消耗实现高性能分割。

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











