







项目数据集+源码+部署:python机器学习 波士顿房价预测 详细教程 源码+结果图+远程部署
目录
数据集
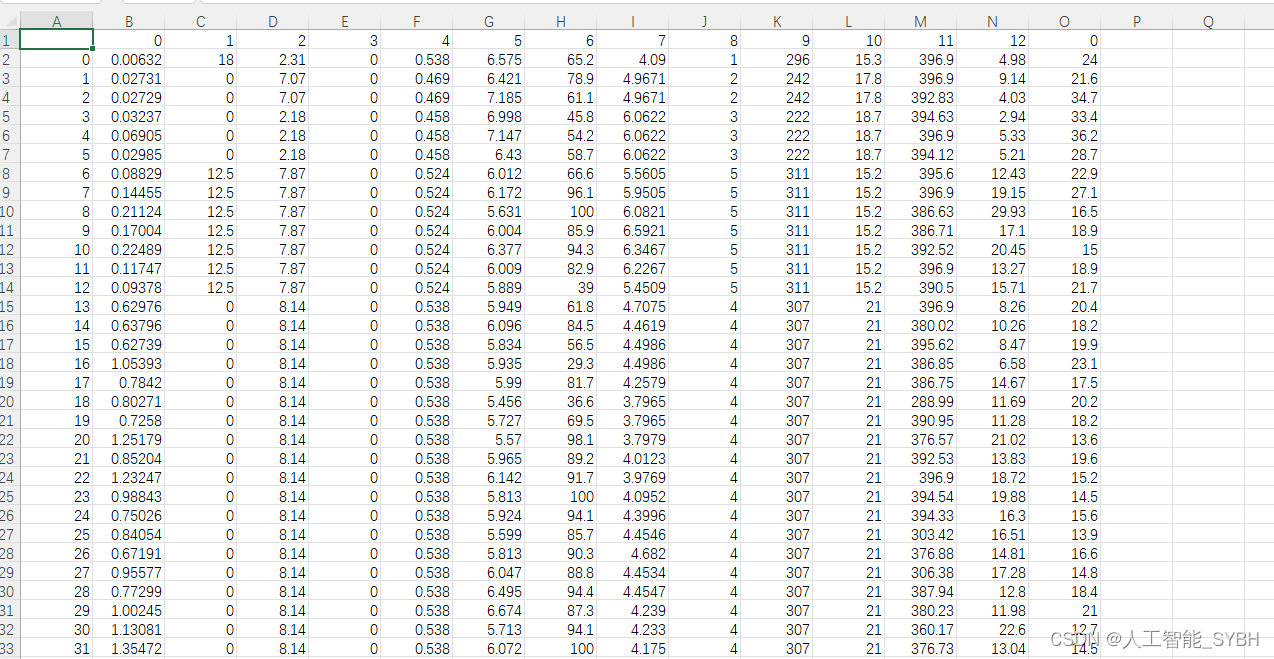
波士顿房价数据集(Boston Housing Dataset)是一个非常著名的数据集,广泛用于回归分析和机器学习的入门研究。它最初由哈里森和鲁宾菲尔德(Harrison, D. and Rubinfeld, D.L.)在1978年发布,包含了波士顿地区房价的中位数与各种影响房价的因素。
这个数据集包含506个数据点,每个数据点有14个属性。具体属性如下:
- CRIM:城镇人均犯罪率。
- ZN:住宅用地超过25000 sq.ft. 的比例。
- INDUS:城镇非零售商用土地的比例。
- CHAS:查尔斯河虚拟变量(如果边界是河流,则为1;否则为0)。
- NOX:一氧化氮浓度(每千万份)。
- RM:住宅平均房间数。
- AGE:1940年之前建成的自用房屋比例。
- DIS:到五个波士顿就业中心的加权距离。
- RAD:辐射性公路的接近指数。
- TAX:每10000美元的全值财产税率。
- PTRATIO:城镇师生比例。
- B:1000(Bk - 0.63)^2 其中Bk为城镇中黑人的比例。
- LSTAT:人口中地位较低人群的百分比。
- MEDV:自有住房的中位数价值(单位:千美元)。
导包
我们首先导入需要的所有数据库、模型库、评价函数等。
# 导入包
import warnings
import lightgbm as lgb
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import shap
import sklearn
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
warnings.filterwarnings('ignore')
导入数据集
注意:
过去大多数情况下会直接用这种方式加载数据集,目前因为1.2版本以后就删除
了数据集,有两种解决方案(1.直接下载数据集.2.降低版本)

报错:
ImportError: `load_boston` has been removed from scikit-learn since version 1.2.
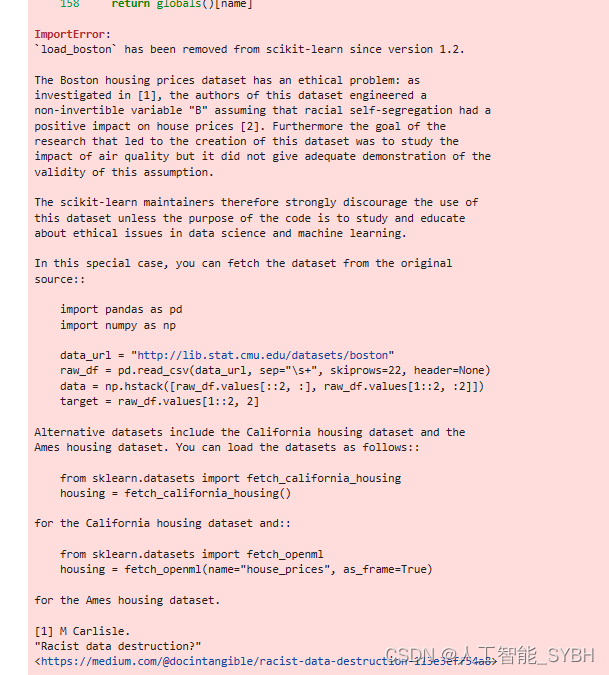
我们才采用直接下载数据集到本地的方法来加载数据集
boston = pd.read_csv('data.csv')
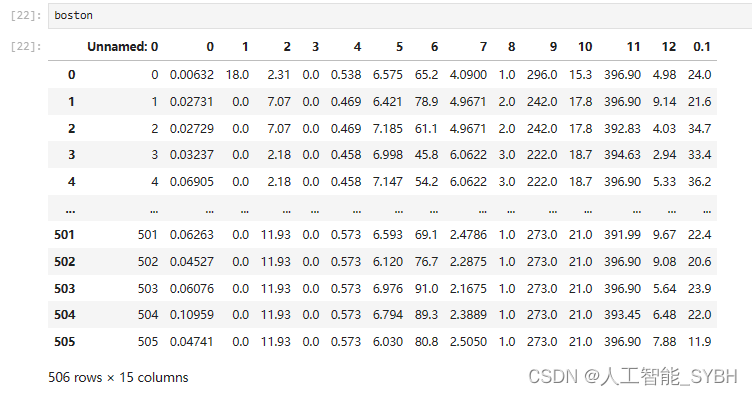
将数据集换分为X,Y.
# 假设最后一列是目标变量
X = boston.iloc[:, 1:-1] # 所有行,除了最后一列的所有列
y = boston.iloc[:, -1] # 所有行,只有最后一列
# 把 X 和 y 转换为 DataFrame
X = pd.DataFrame(X)
y = pd.DataFrame(y)
# 打印信息查看
print(X)
print(y)
对特征进行重新命名
X.columns = list(map(lambda x: 'feature' + str(x), X.columns))
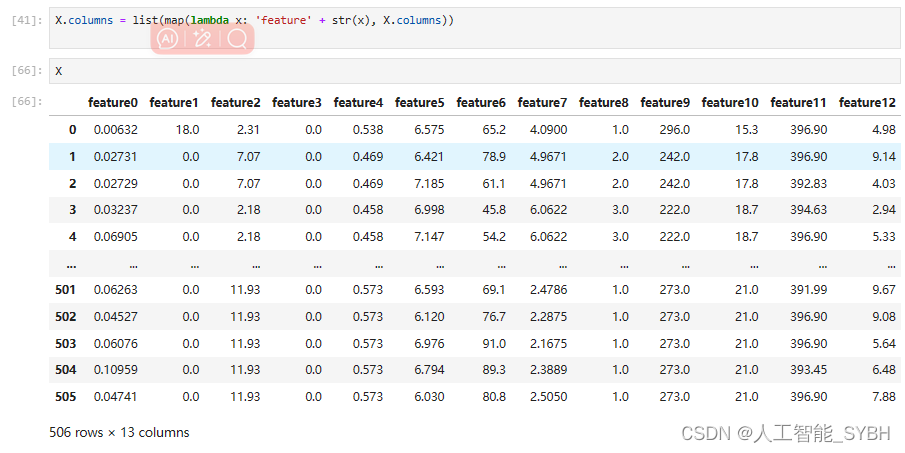
数据处理
cate_cols = [] # 离散特征
num_cols = [] # 数值型特征
# 获取各个特征的数据类型
dtypes = X.dtypes
for col, dtype in dtypes.items():
if dtype == 'object':
cate_cols.append(col)
else:
num_cols.append(col)
数值型特征
class Num_Encoder(BaseEstimator, TransformerMixin):
def __init__(self, cols=[], fillna=False, addna=False):
self.fillna = fillna
self.cols = cols
self.addna = addna
self.na_cols = []
self.imputers = {}
def fit(self, X, y=None):
for col in self.cols:
if self.fillna:
self.imputers[col] = X[col].median()
if self.addna and X[col].isnull().sum():
self.na_cols.append(col)
print(self.na_cols, self.imputers)
return self
def transform(self, X, y=None):
df = X.loc[:, self.cols]
for col in self.imputers:
df[col].fillna(self.imputers[col], inplace=True)
for col in self.na_cols:
df[col + '_na'] = pd.isnull(df[col])
return df
离散型特征
class Cat_Encoder(BaseEstimator, TransformerMixin):
def __init__(self, cols, max_n_cat=7, onehot_cols=[], orders={}):
self.cols = cols
self.onehot_cols = onehot_cols
self.cats = {}
self.max_n_cat = max_n_cat
self.orders = orders
def fit(self, X, y=None):
df_cat = X.loc[:, self.cols]
for n, c in df_cat.items():
df_cat[n].fillna('NAN', inplace=True)
df_cat[n] = c.astype('category').cat.as_ordered()
if n in self.orders:
df_cat[n].cat.set_categories(self.orders[n], ordered=True, inplace=True)
cats_count = len(df_cat[n].cat.categories)
if cats_count <= 2 or cats_count > self.max_n_cat:
self.cats[n] = df_cat[n].cat.categories
if n in self.onehot_cols:
self.onehot_cols.remove(n)
elif n not in self.onehot_cols:
self.onehot_cols.append(n)
print(self.onehot_cols)
return self
def transform(self, df, y=None):
X = df.loc[:, self.cols]
for col in self.cats:
X[col].fillna('NAN', inplace=True)
X.loc[:, col] = pd.Categorical(X[col], categories=self.cats[col], ordered=True)
X.loc[:, col] = X[col].cat.codes
if len(self.onehot_cols):
df_1h = pd.get_dummies(X[self.onehot_cols], dummy_na=True)
df_drop = X.drop(self.onehot_cols, axis=1)
return pd.concat([df_drop, df_1h], axis=1)
return X
配置流水线
num_pipeline = Pipeline([
('num_encoder', Num_Encoder(cols=num_cols, fillna='median', addna=True)),
])
X_num = num_pipeline.fit_transform(X)
cat_pipeline = Pipeline([
('cat_encoder', Cat_Encoder(cols=cate_cols))
])
X_cate = cat_pipeline.fit_transform(X)
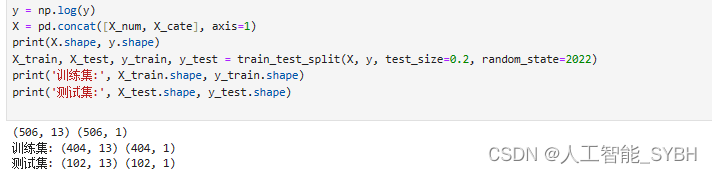
分割训练集和测试集
我们将数据集分割为8:2, 80%作为训练集,20%作为测试集.
y = np.log(y)
X = pd.concat([X_num, X_cate], axis=1)
print(X.shape, y.shape)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=2022)
print('训练集:', X_train.shape, y_train.shape)
print('测试集:', X_test.shape, y_test.shape)
自定义模型
我们采用了LGB模型作为实例,之后我们会对其使用网格搜索找到最优的参数.
lgbmodel = lgb.LGBMRegressor(boosting_type='gbdt',
metric='mse',
n_estimators=50,
max_depth=3,
lambda_l1=1e-5,
lambda_l2=1e-3)
模型训练
lgbmodel.fit(X_train, y_train)
验证
y_train_pred = lgbmodel.predict(X_train)
y_test_pred = lgbmodel.predict(X_test)
mse_train = mean_squared_error(y_train, y_train_pred)
mse_test = mean_squared_error(y_test, y_test_pred)
r2_score_train = r2_score(y_train, y_train_pred)
r2_score_test = r2_score(y_test, y_test_pred)
print('训练集的MSE: ', mse_train)
print('测试集的MSE: ', mse_test)
print('训练集的R2: ', r2_score_train)
print('测试集的R2: ', r2_score_test)

测试集明显差于训练集,模型的泛化性比较低,在训练集上过拟合了, 需要对其进行参数调参.
特征重要性
可以根据每个特征的重要性进行特征选择
feature_importance = pd.DataFrame(lgbmodel.feature_importances_.reshape(X.shape[1], 1), index=list(X.columns),
columns=['特征重要性'])
print(feature_importance)

特征选择
def feature_importance(lgbmodel, df):
return pd.DataFrame({'cols': df.columns, 'importance': lgbmodel.feature_importances_}).sort_values('importance',
ascending=False)
features = feature_importance(lgbmodel, X_train)
print(features)
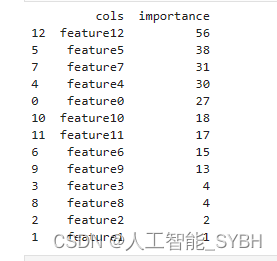
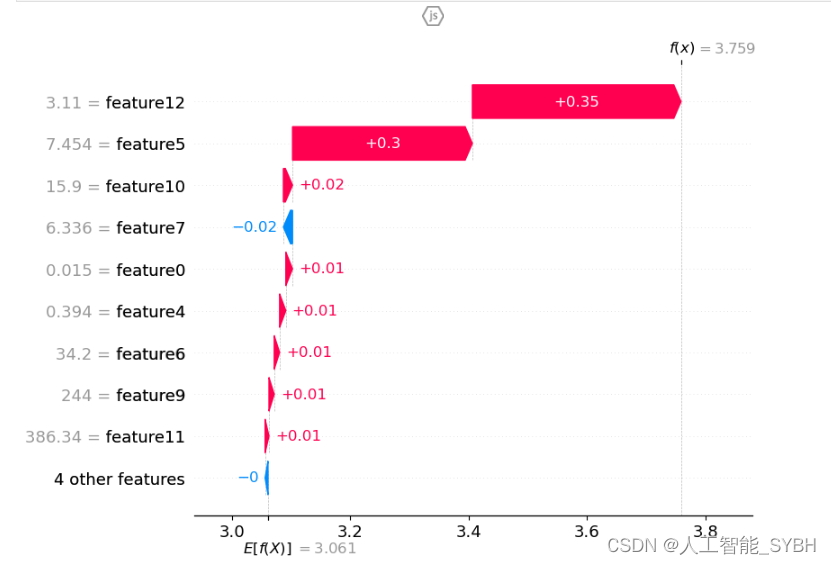
特征选择的工具我们选用SHAP,SHAP 在波士顿房价预测中的特征选择中提供了一种强大且直观的方式来评估和理解各特征对模型预测的贡献,从而辅助我们做出更为明智的决策。通过使用 SHAP,我们可以在保持模型性能的同时,尽量简化模型,避免不必要的复杂性。
shap.initjs()
explainer = shap.TreeExplainer(lgbmodel)
shap_values = explainer(X_train)
shap.plots.waterfall(shap_values[0])
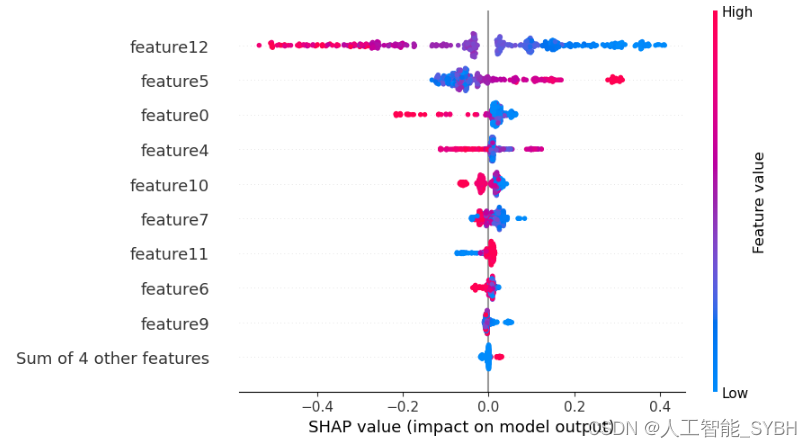
shap.plots.beeswarm(shap_values, max_display=10)
shap.plots.bar(shap_values, max_display=11)
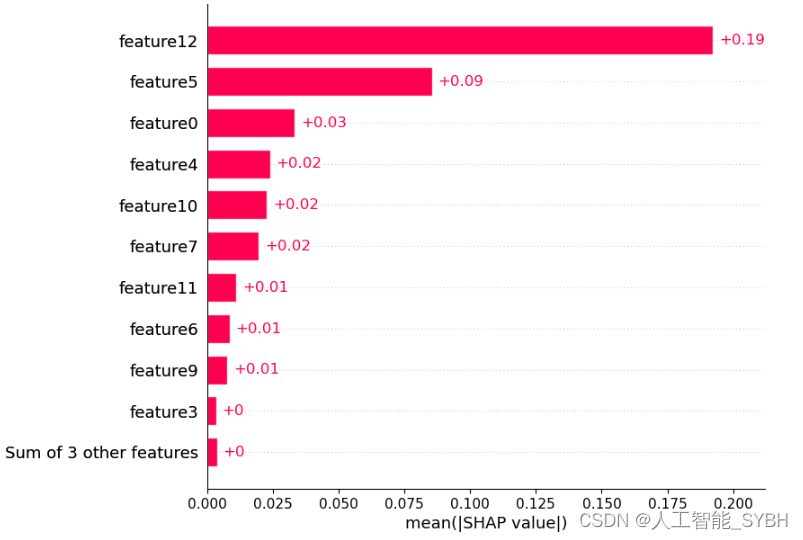
最终我们选择了十个最重要的特征作为最终的数据集
# 最好提交的特征,10个
to_keep_final = ['feature12',
'feature5',
'feature0',
'feature4',
'feature10',
'feature7',
'feature11',
'feature6',
'feature9',
'feature3', ]
X_train_final = X_train[to_keep_final].copy()
网格搜索
lgbmodel = lgb.LGBMRegressor()
rfrmodel = RandomForestRegressor()
param_grid_lgb = {
"n_estimators": np.arange(50, 300, 50),
"learning_rate": [0.01, 0.05, 0.1, 0.3],
'lambda_l1': [1e-5, 1e-3, 1e-1],
'lambda_l2': [1e-5, 1e-3, 1e-1],
'max_bin': np.arange(5, 30, 10),
'num_leaves': np.arange(5, 20, 5),
}
param_grid_rfr = {
"n_estimators": np.arange(50, 300, 50),
"min_samples_leaf": np.arange(1, 101, 30),
"max_depth": np.arange(2, 8, 2),
"max_leaf_nodes": np.arange(5, 20, 5)
}
lgbmodel_grid = GridSearchCV(estimator=lgbmodel,
param_grid=param_grid_lgb,
verbose=1,
n_jobs=-1,
cv=2)
rfrmodel_grid = GridSearchCV(estimator=rfrmodel,
param_grid=param_grid_rfr,
verbose=1,
n_jobs=-1,
cv=2)
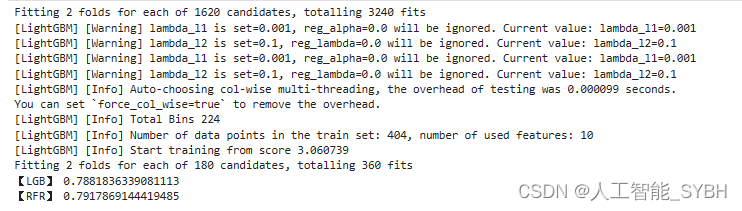
lgbmodel_grid.fit(X_train_final, y_train)
rfrmodel_grid.fit(X_train_final, y_train)
print('【LGB】', lgbmodel_grid.best_score_)
print('【RFR】', rfrmodel_grid.best_score_)
best_modellgb = lgb.LGBMRegressor(boosting_type='gbdt',
objective='regression',
colsample_bytree=1,
metrics='mse',
learning_rate=lgbmodel_grid.best_estimator_.get_params()['learning_rate'],
n_estimators=lgbmodel_grid.best_estimator_.get_params()['n_estimators'],
num_leaves=lgbmodel_grid.best_estimator_.get_params()['num_leaves'],
max_bin=lgbmodel_grid.best_estimator_.get_params()['max_bin'],
lambda_l1=lgbmodel_grid.best_estimator_.get_params()['lambda_l1'],
lambda_l2=lgbmodel_grid.best_estimator_.get_params()['lambda_l2'])
best_modelrfr = RandomForestRegressor(n_estimators=rfrmodel_grid.best_estimator_.get_params()['n_estimators'],
min_samples_leaf=rfrmodel_grid.best_estimator_.get_params()['min_samples_leaf'],
max_depth=rfrmodel_grid.best_estimator_.get_params()['max_depth'],
max_leaf_nodes=rfrmodel_grid.best_estimator_.get_params()['max_leaf_nodes'])
best_modellgb.fit(X_train, y_train)
y_train_pred = best_modellgb.predict(X_train)
y_test_pred = best_modellgb.predict(X_test)
mse_train = mean_squared_error(y_train, y_train_pred)
mse_test = mean_squared_error(y_test, y_test_pred)
r2_score_train = r2_score(y_train, y_train_pred)
r2_score_test = r2_score(y_test, y_test_pred)
print('训练集的MSE: ', mse_train)
print('测试集的MSE: ', mse_test)
print('训练集的R2: ', r2_score_train)
print('测试集的R2: ', r2_score_test)
结果可视化
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
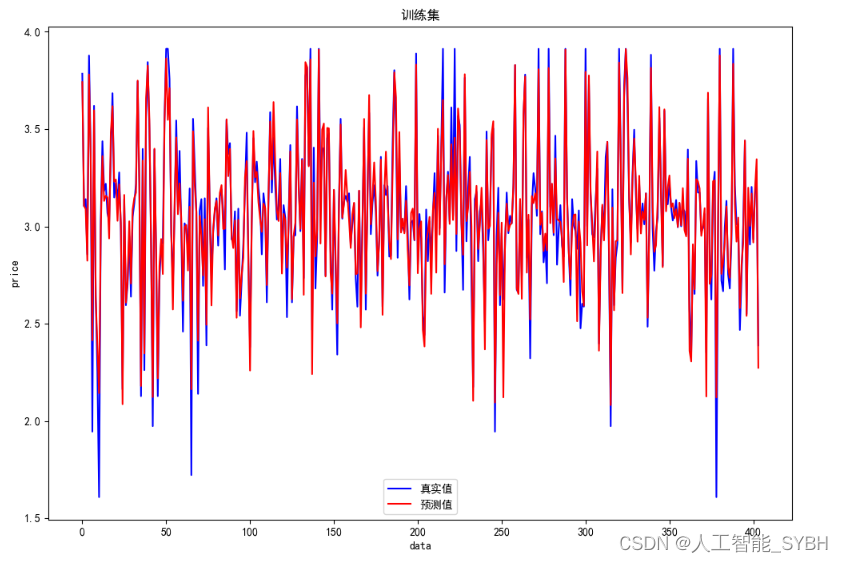
plt.figure(figsize=(12, 8))
plt.plot(y_train.values, color='blue', label='真实值')
plt.plot(y_train_pred, color='red', label='预测值')
plt.title('训练集')
plt.xlabel('data')
plt.ylabel('price')
plt.legend()
plt.show()
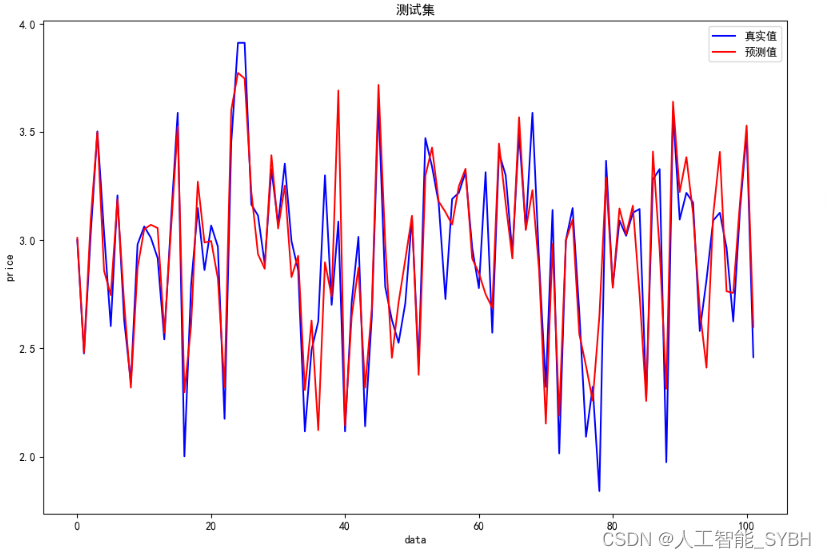
plt.figure(figsize=(12, 8))
plt.plot(y_test.values, color='blue', label='真实值')
plt.plot(y_test_pred, color='red', label='预测值')
plt.title('测试集')
plt.xlabel('data')
plt.ylabel('price')
plt.legend()
plt.show()



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











