






文章内容来自b站up主忠厚老实的老王,视频链接如下:
自动驾驶决策规划算法第二章第二节(中) 参考线算法_哔哩哔哩_bilibili
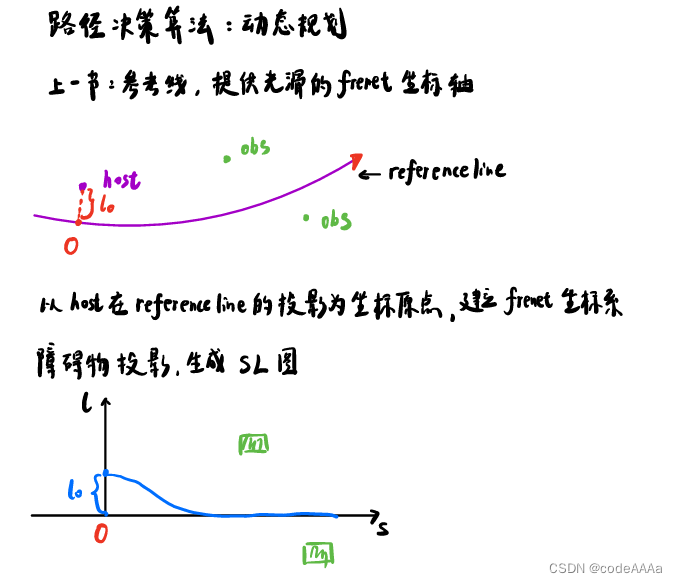
其中host是自车位置,以host在参考线的投影为坐标原点,建立frenet坐标,此时host的坐标是(0,L0),将障碍物的也投影到该坐标系下。
规划的第一步就是确定规划的起点:

蓝色的线是第一次规划的结果,按照当前的规划来说100ms以后应该是绿点位置,但是由于控制本身不完美,100ms后车辆实际位置是红色点,此时同时开始第二次规划,按照规划100ms后应该是紫点位置,但是由于控制不完美,车辆实际位置是橙点。这样在控制看了规划的轨迹是割裂的。
正确的做法是比较规划100ms之后比较车辆实际位置和规划它应该达到的位置,看两者之间是否相差过大,具体如下:

如果相差太大就以当前车辆的实际位置(在French坐标系上的坐标位置是(0,L0))作为规划的起点规划下一个周期的轨迹。

相差不大除了上面的那种方法,还有另一种方法就是直接使用上一个周期规划100ms车辆应该到达的位置(也就是绿点)投影到referenceline上进行下一个周期的规划。下面使用第一种方法进行规划:

如上,第一次规划的轨迹是蓝色,100ms后规划位置是绿色,车辆实际位置是红色,有一个差距,此时将车辆实际位置(红点)投影到上一次规划的轨迹(蓝线)上,得到紫点,再将紫点投影到referenceline上进行下一阶段的规划也就是紫线。

如上,使用上面的方法从控制的角度来说得到的规划的轨迹是连续的,并每次规划都从定位开始规划要好很多。
静态障碍物避障
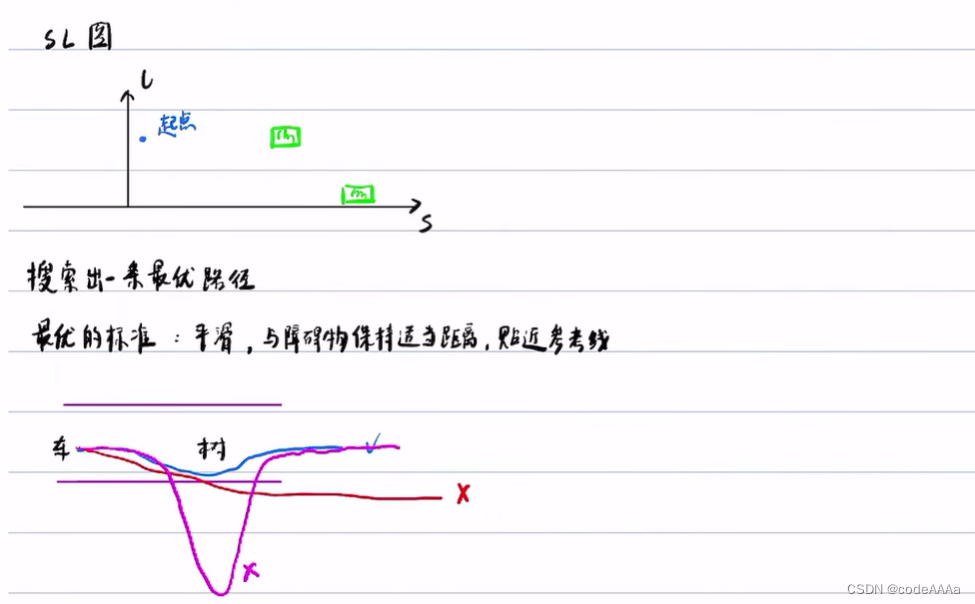

具体如下:
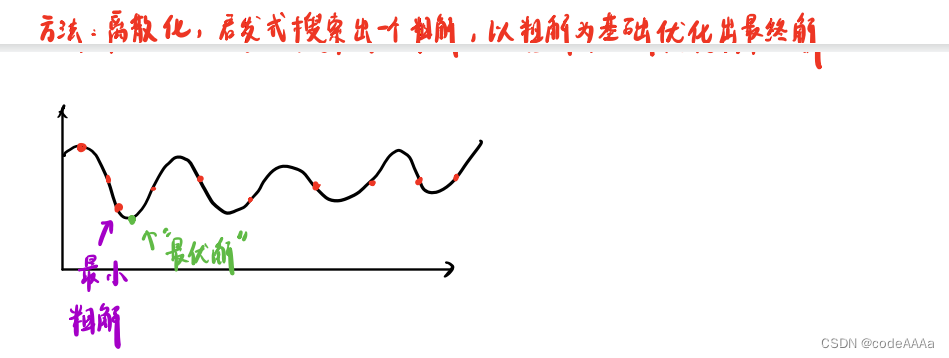
在障碍物附近离散化的撒点,再计算cost function,计算出最优路径;
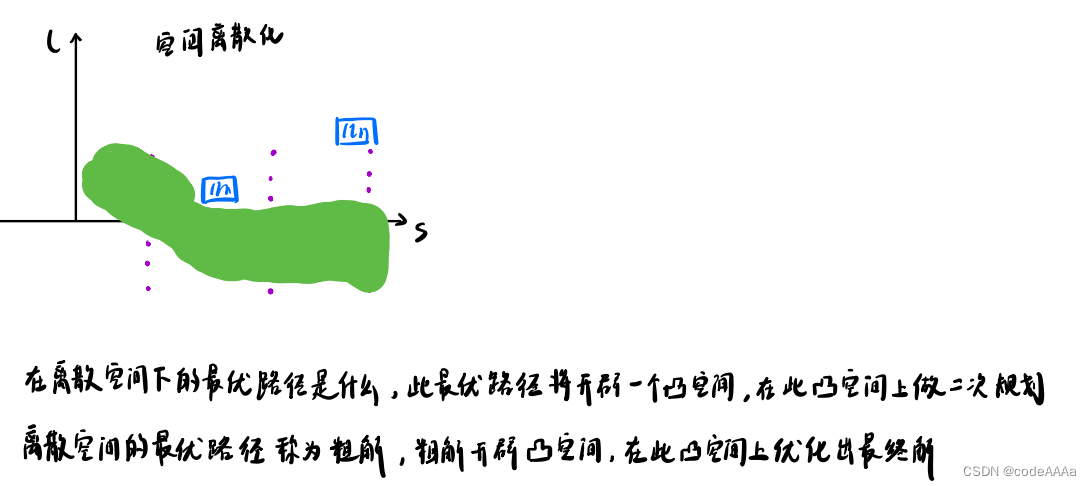
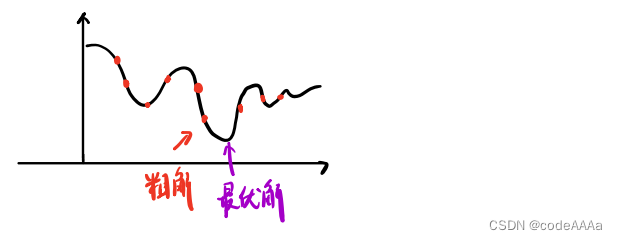
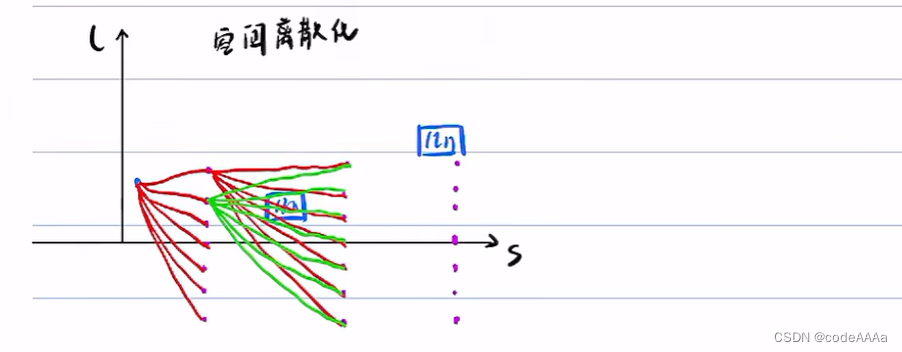
在离散空间上使用动态规划得到粗解,开辟凸空间;在此凸空间上使用二次规划的到最优解。

规划起点的约束和第一层离散点的约束,其中第一层离散点约束中的第一阶和第二节导数都为0,原因是动态规划得到的解是粗解,目的是开辟凸空间,最后的最优路劲是二次规划得到的。同理第一层到第二层的约束也是这样,一阶和二阶导数值都为0:
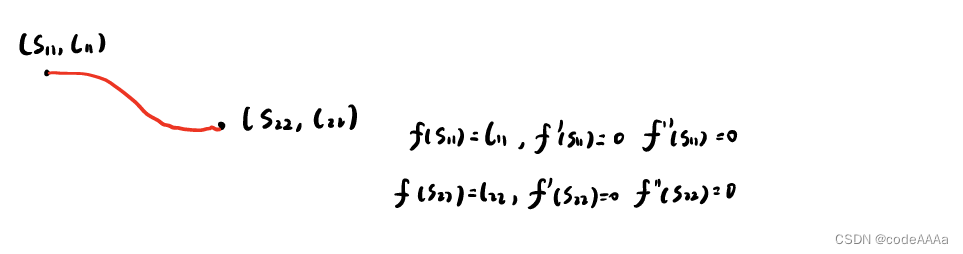
这样通过五次多项式来计算出一条条路径出来,接下来就是设计cost function来评价路径的优劣:

这个cost function的解释如下:
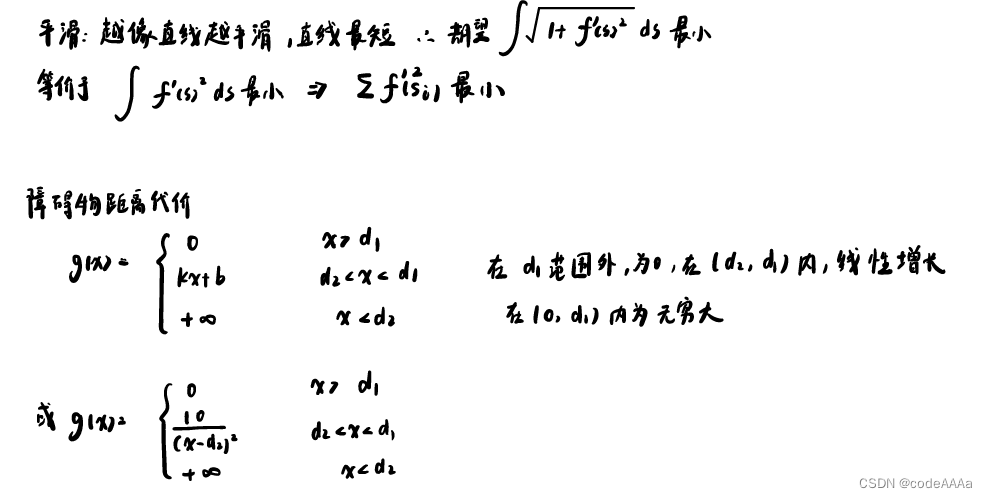
设计好cost function后就可以使用cost function来计算出每条路径的代价,问题就变成怎么找图的最短路径问题,比较常用的方法有:Dijkstra算法、Bellman-Ford算法、Floyd-Warshall算法以及A*算法。这里使用比较简单的方法介绍图的最短路径问题:
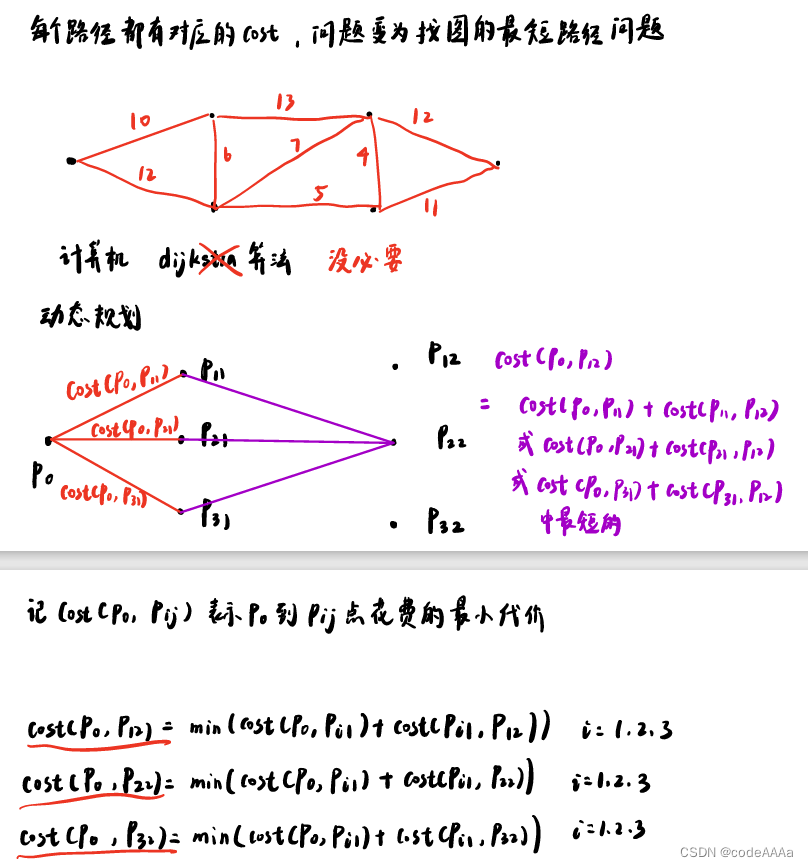
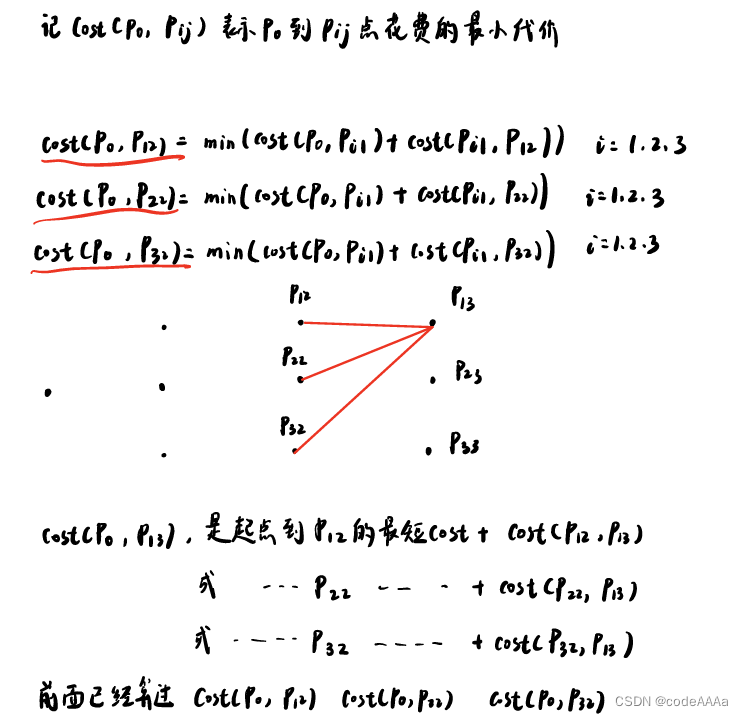

以此类推,从起到到第n层的最小cost问题可以简化成从起点到n-1层最小cost问题,再往前推就可以把复杂的问题简单化。这样就可以写出状态转移方程(递推方程):
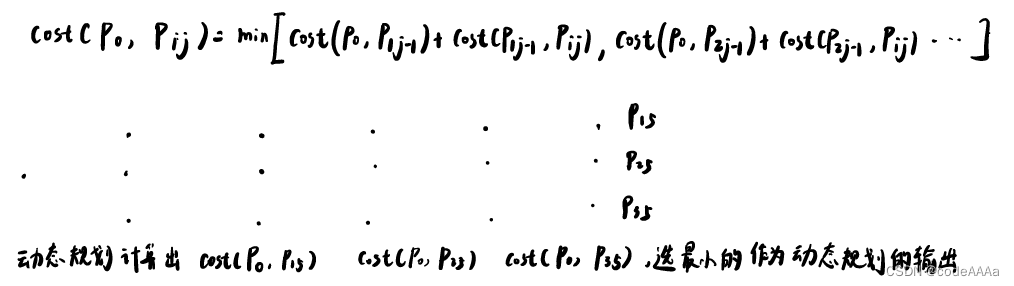
控制接口与轨迹拼接
现实中由于规划是100ms更新一次,控制是10ms更新一次,在100ms和10ms之间意味控制九个周期跟踪的都是同一个点,控制效果不好。解决办法如下:

规划会规划出来一系列的点,但是原来的做法是找到100ms时对应的点将其发给控制接口,但是这种方法在控制与规划周期同步时没有问题,当控制与规划周期不同步时就会出现问题,所以控制的接口得改变,在前期规划时其实已经规划出10ms、20ms以及30ms等一系列到100ms的点,但是直将100ms时对应的规划点发给控制接口就会使得控制效果变差,改造方法如下:

原理基本如上图,细节很多,如下:
问题1:轨迹的时间是绝对时间

拼接例子如下:

去查上一个周期100ms也就是绝对时间16:00:10对应的规划点(紫色点),和当前车的位置(红点)进行比较,如果相差大就不拼接,误差不大就拼接。
对于控制也用绝对时间比较好,如下:
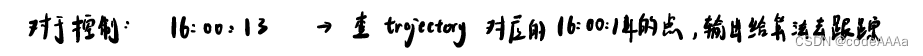 这里是由于控制也有延迟。
这里是由于控制也有延迟。
问题2:规划起点
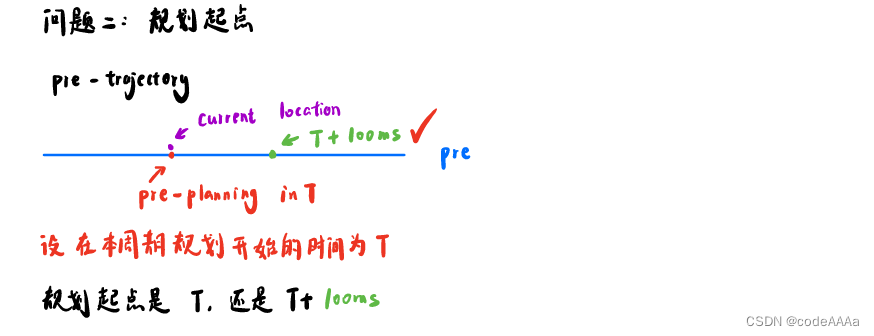
上个规划周期规划出来的轨迹是蓝色线条,本周期规划开始的时间是T,首先比较当前车辆的位置和上一个规划周期在T时刻规划出来的位置是否接近,比较接近,误差不大就是说明控制时按照规划路径走的,就可以进行轨迹拼接,规划的起点是T+100ms(绿点)。
原因如下:

控制频率比较快,在[T,T+100ms]的时间段内,规划未计算完成,控制跟踪的是上一个周期规划的轨迹。

如果本周期规划起点的绝对时间是T,计算完毕的时间是T+100ms,也就是直到T+100ms时,绿色的本周期轨迹才计算完毕,发送给控制接口,从控制看来规划的路径如下,是不连续的:
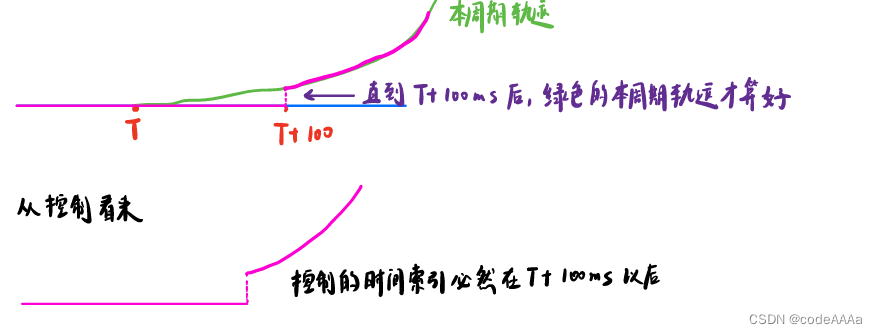
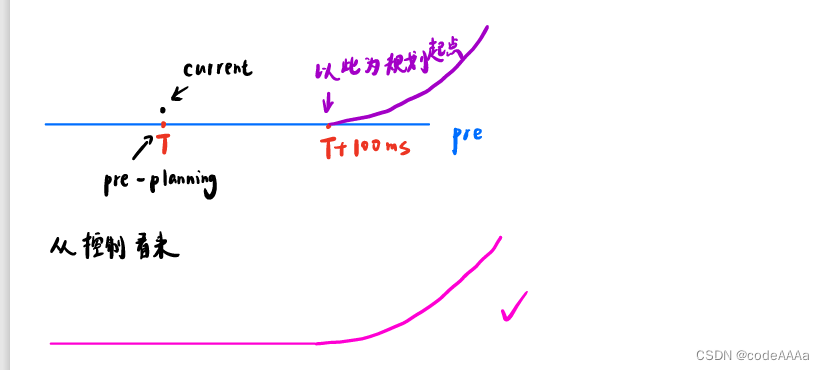
而如果规划起点的绝对时间是T+100ms,车在跟踪完上一个规划周期规划的轨迹后,在T+100ms时控制接口就可以接受到本规划周期规划到的路径信息,这样在控制看来规划的轨迹是连续的。
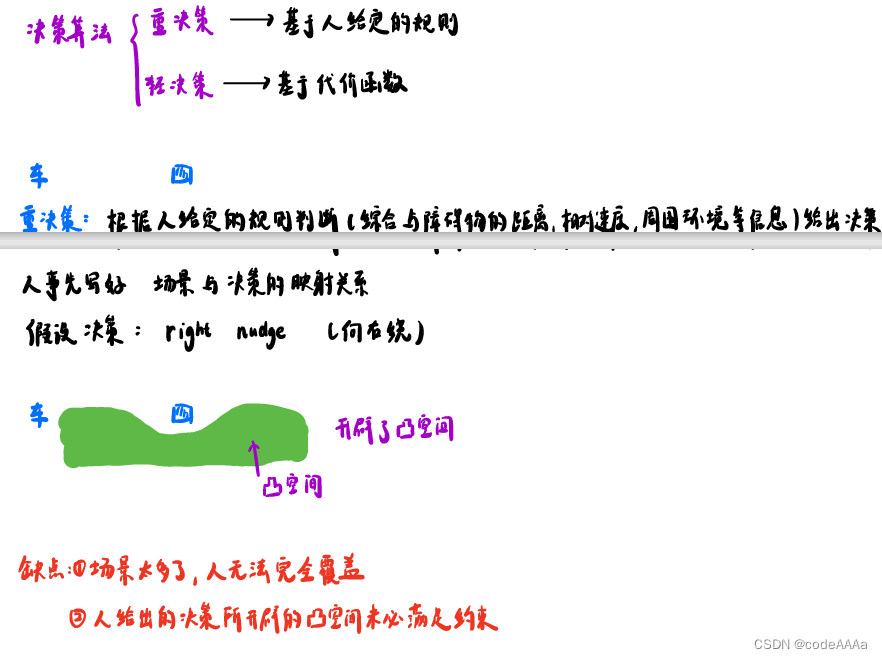
动态规划和决策之间的关系

动态规划开辟凸空间,所以动态规划应该是决策算法。



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









