






文章内容来自b站up主忠厚老实的老王,视频链接如下:
自动驾驶决策规划算法第二章第二节(中) 参考线算法_哔哩哔哩_bilibili

参考线的作用:
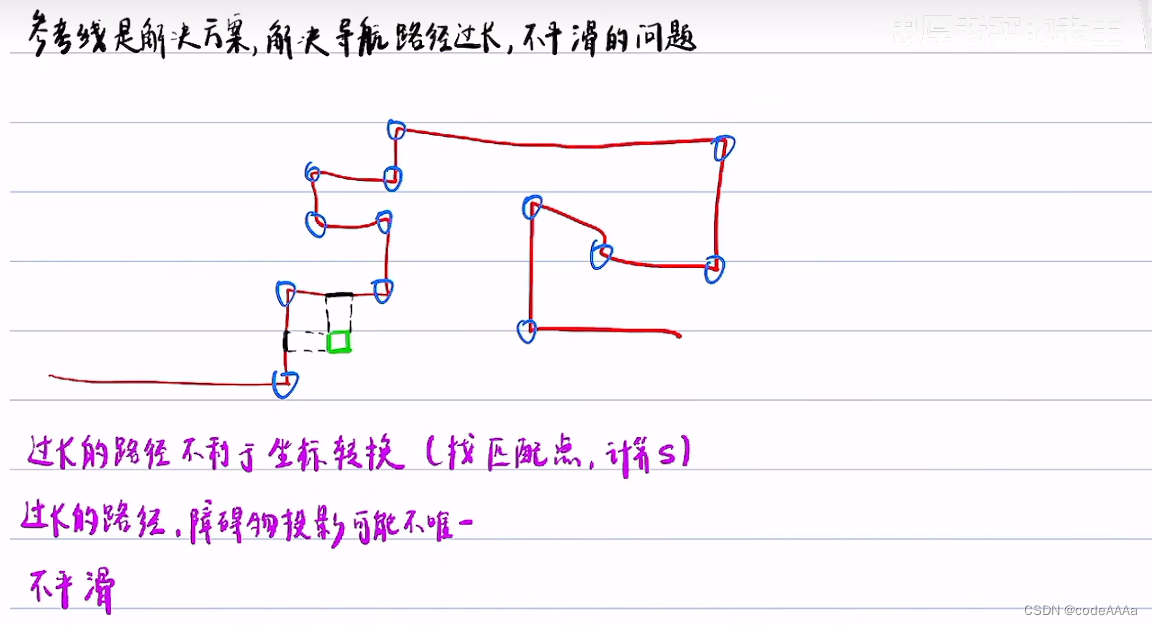
其中第二点,例如绿色的方形障碍物距离上侧和左侧障碍物距离相等,可能会导致投影点不唯一;蓝色点是路径中不平滑的点。
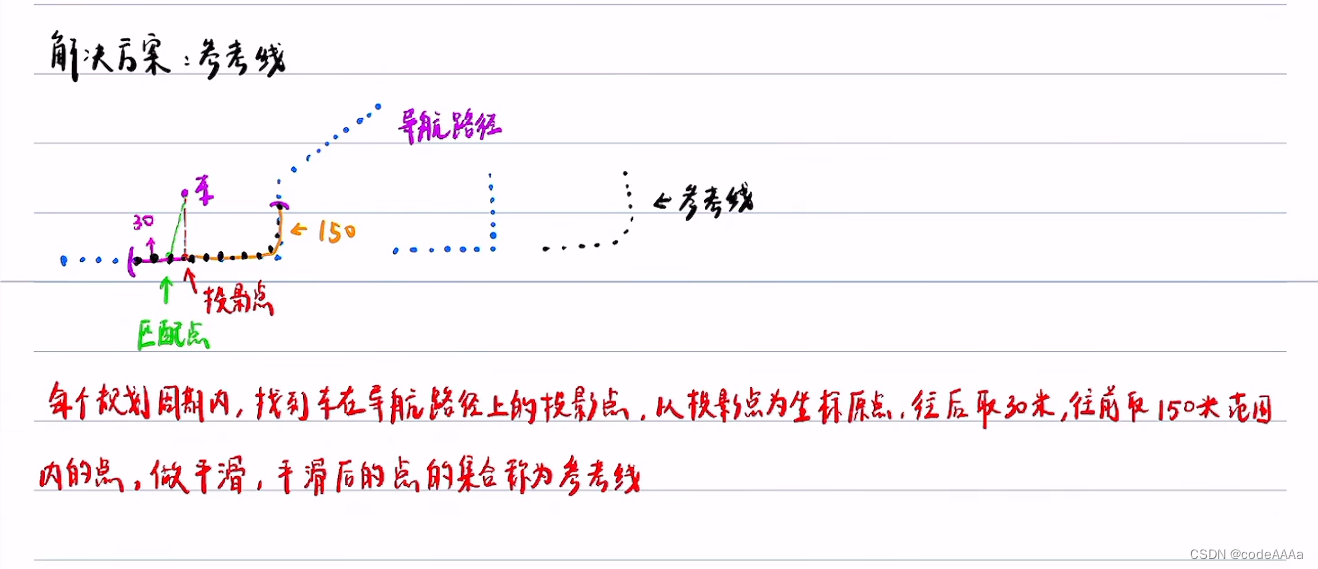
参考线就是在全局路径中截取一小段路径,然后把它做平滑,平滑后的点的集合做为参考线,将障碍物投影到以参考线为坐标轴的frenet坐标系上。如下:
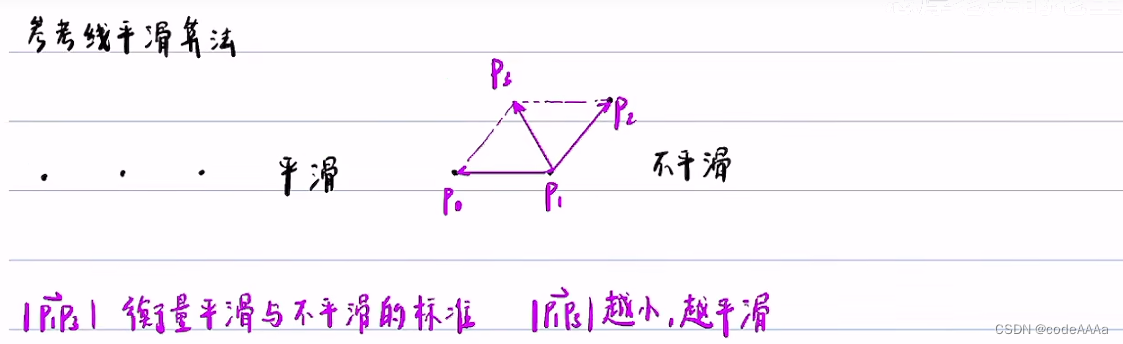
参考线平滑算法
上面的算法认为参考线越接近直线,路径越平滑,但是参考线不是越平滑越好,如下,黑色是原来的,紫色是平滑后的,虽然是一条直线了,但是严重偏移原来的点。

改进上面的缺陷后,如下:

除了平滑性和道路集合的因素,还有一点是长度要均匀紧凑,如下:


上面的问题是一个典型的二次规划问题,二次规划问题的形式如下:

 可以将上述问题写成二次规划的标准形式:
可以将上述问题写成二次规划的标准形式:
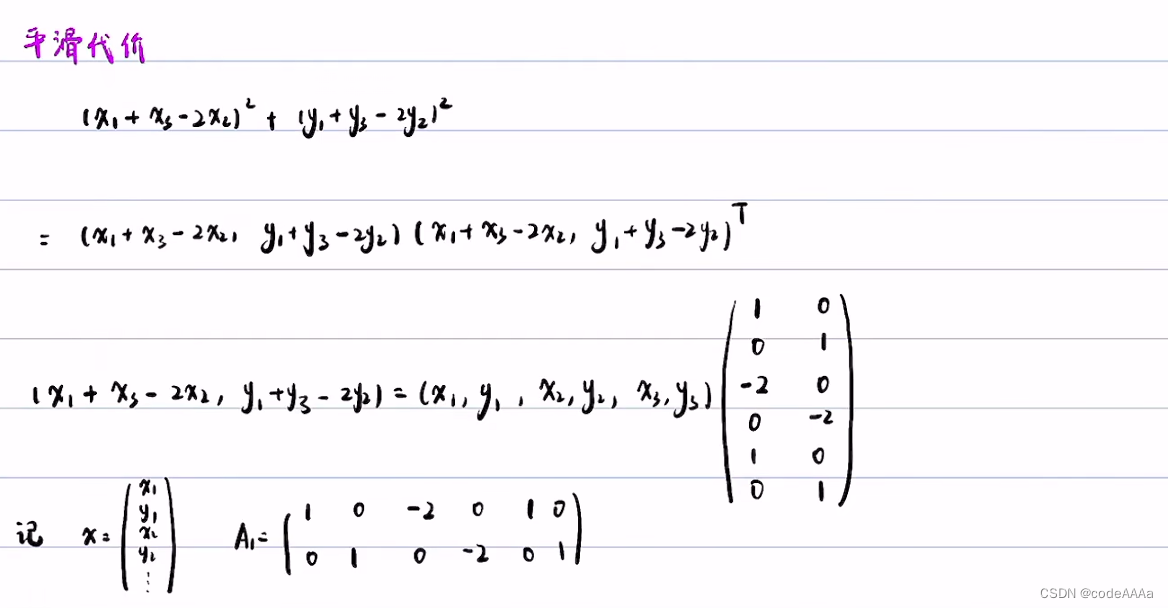
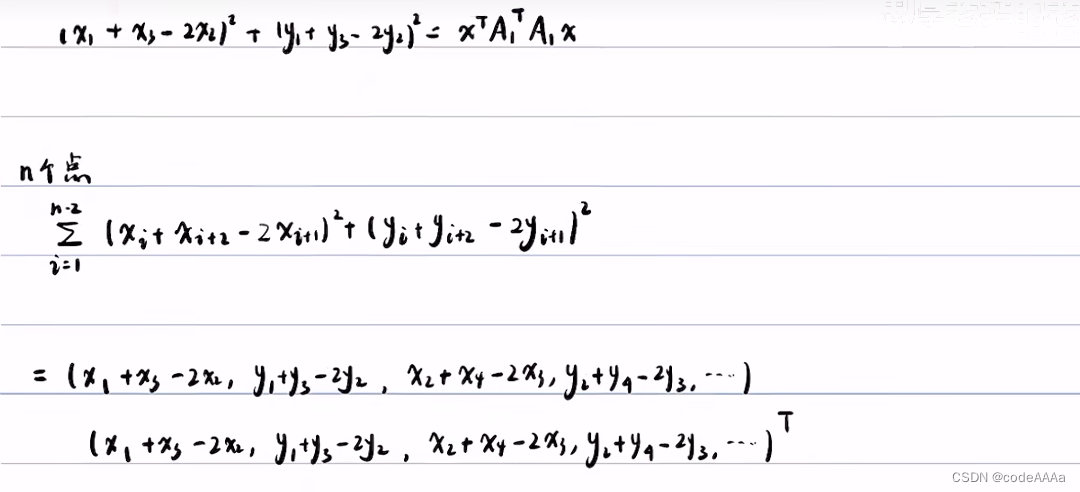
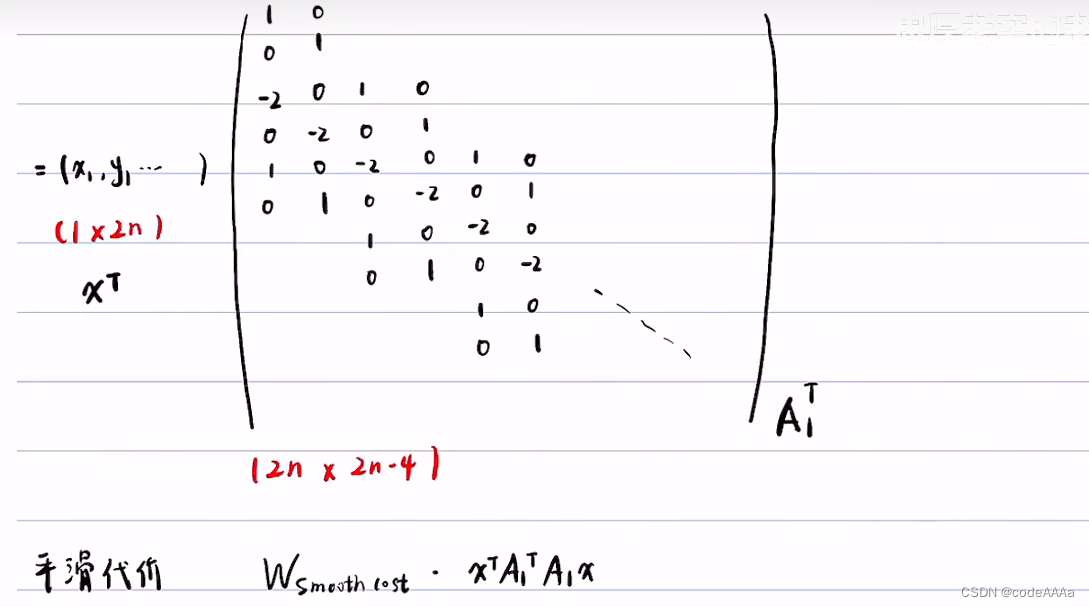
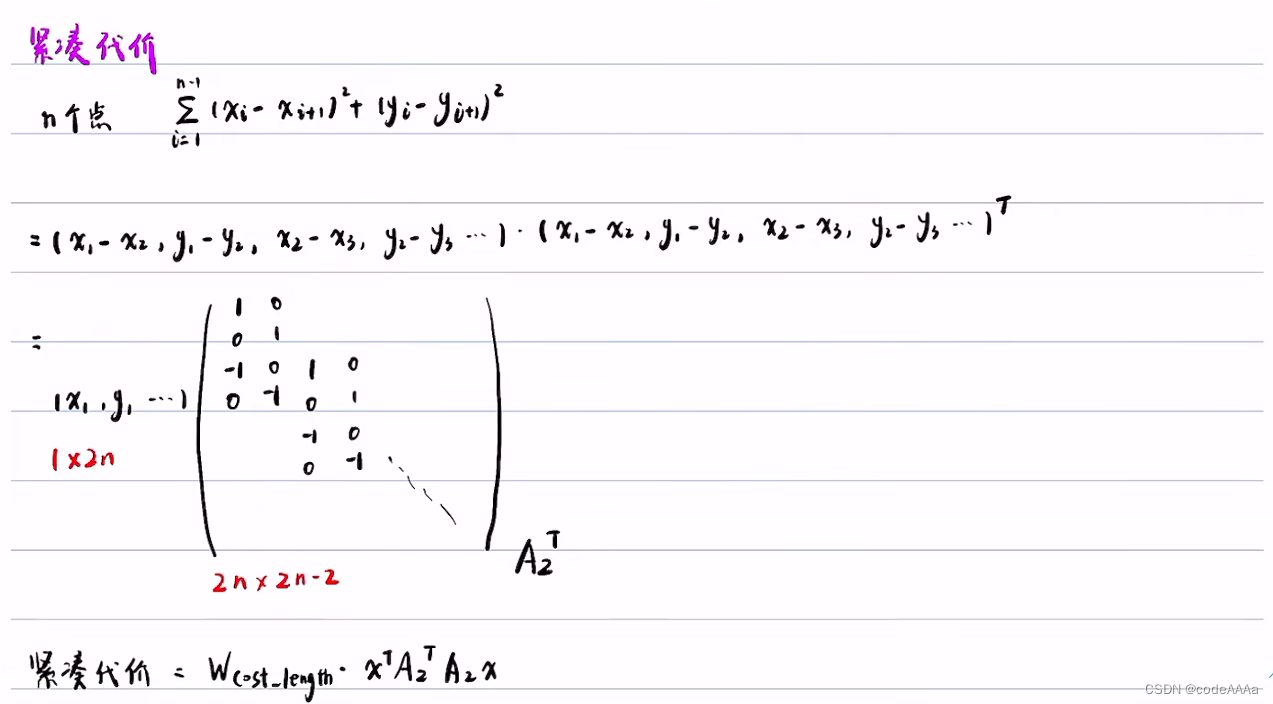

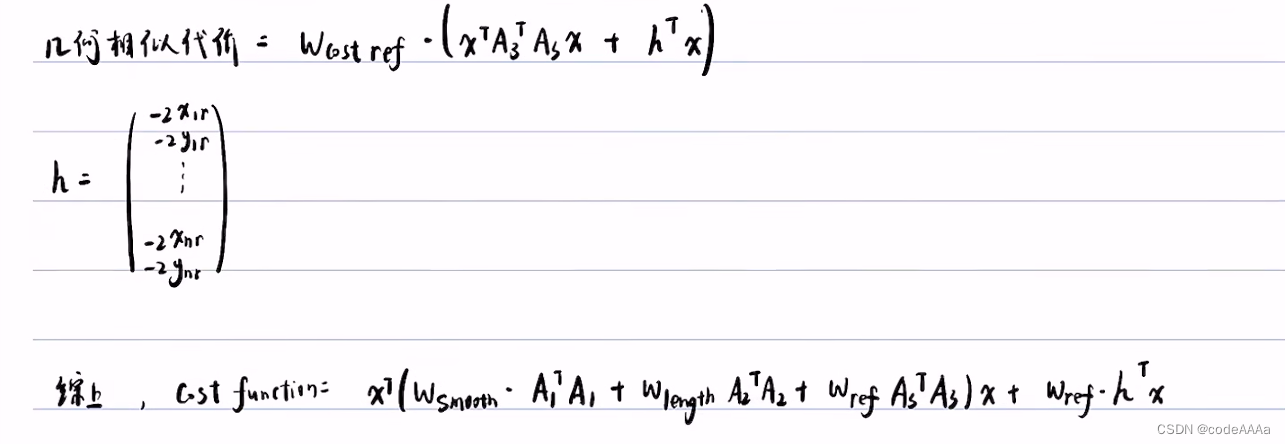 可以将costfunction化成二次规划的标准形式:
可以将costfunction化成二次规划的标准形式: 
这里的约束就是不希望x和xref不要距离太远,为了防止在设置权重时,偏向于平滑或者紧凑使得距离太远,如下:

有时会考虑曲率约束,曲率约束是一个非线性约束,曲率约束一般和车的最大侧向加速度有关,曲率约束一般对参考线影响不大,对速度规划影响较大。在规划参考线时可以将平滑性的权重设置大一点。
曲率的近似计算如下:
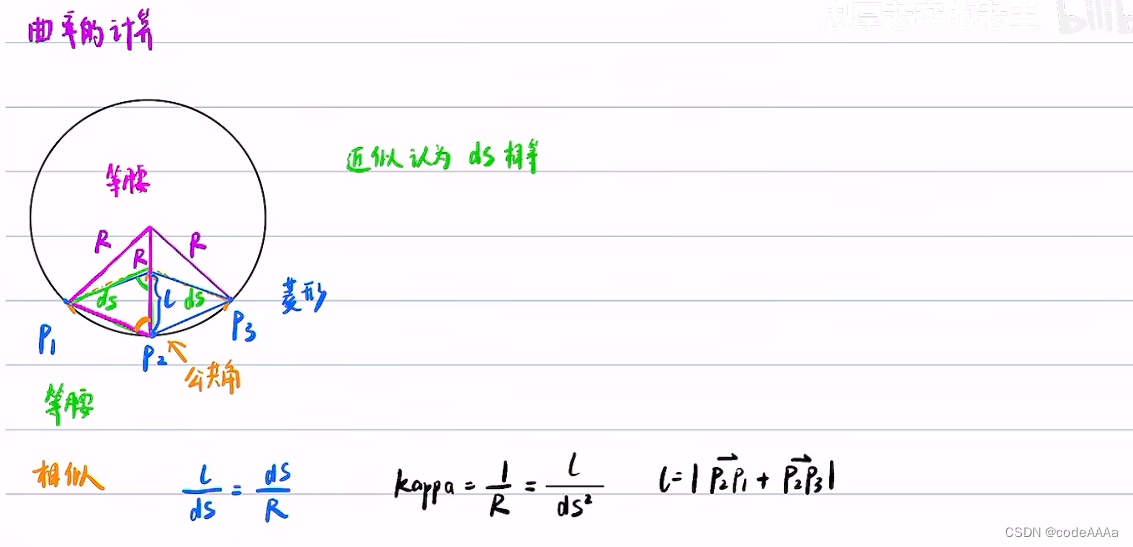
其中,曲率kappa的参考方式是L/ds^2,其中l是向量的模,是个非线性量。
参考线算法


以匹配点为原点向前150m,向后30米,需要注意的是只有在采样参考线时才以匹配点为原点采样,但是把车和障碍物投影在参考线上自然坐标系时还是需要计算投影点的。


改进:
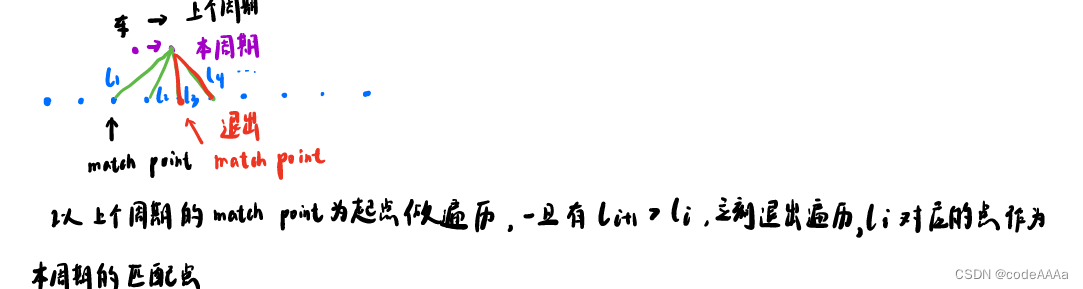
这里有一个注意事项,判断遍历的方向:

汽车如果往前走,遍历方向就是往前,往后走遍历方向就往后,如果判断车辆往前后还是往后走的方法:
其中d是车和上个匹配点组成的向量,τ是上个匹配点的方向向量。用两个点乘的结果来判断,如果两者的点乘结果很小,说明两种几乎垂直,可以将上个规划周期的匹配点当做本周期的匹配点。
 这个方法有点像梯度下降:
这个方法有点像梯度下降:
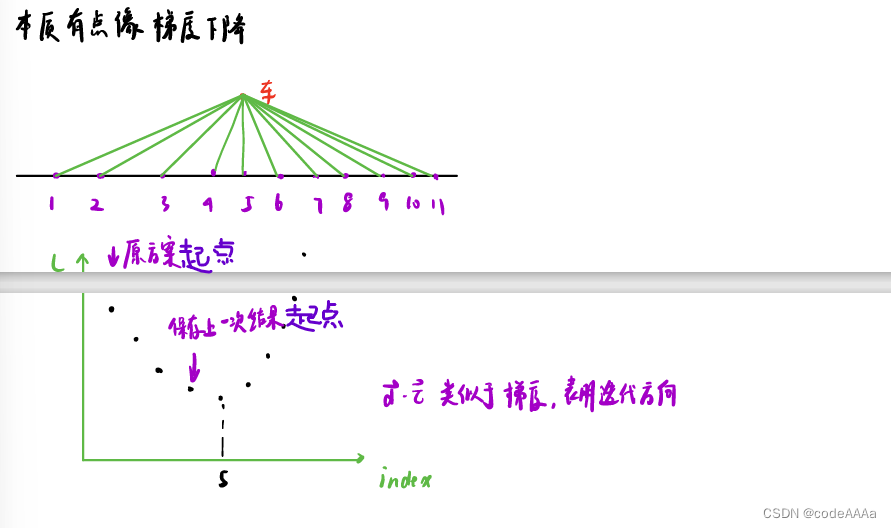


使用本方法的缺陷如上图,如果以上一个周期的匹配点做为起点的话,有可能会导致落入局部极小值,但是上图上本周期实际上的匹配带你绿色文字处那个。但是这种情况出现的概率极小,如下:

万一发生时的双保险:

上面伪代码的含义就是发现了第一个极小值后,在遍历这个极小值后面的点。遍历过程中如果发现l在增大,increase count就加1,increase count是l连续增加的次数,在遍历过程中如果连续遍历了10次还没找到新的极小值,这个极小值点就是匹配点,如果遍历遍历过程中发现了新的极小值点,就把这个新的极小值点存储,同时increase count就清零,再遍历这个新的极小值点后面的点,过程原理和上面一样,最后将存储到的极小值点进行比较,选择最小的。

在up的github上的代码处理方法如下:
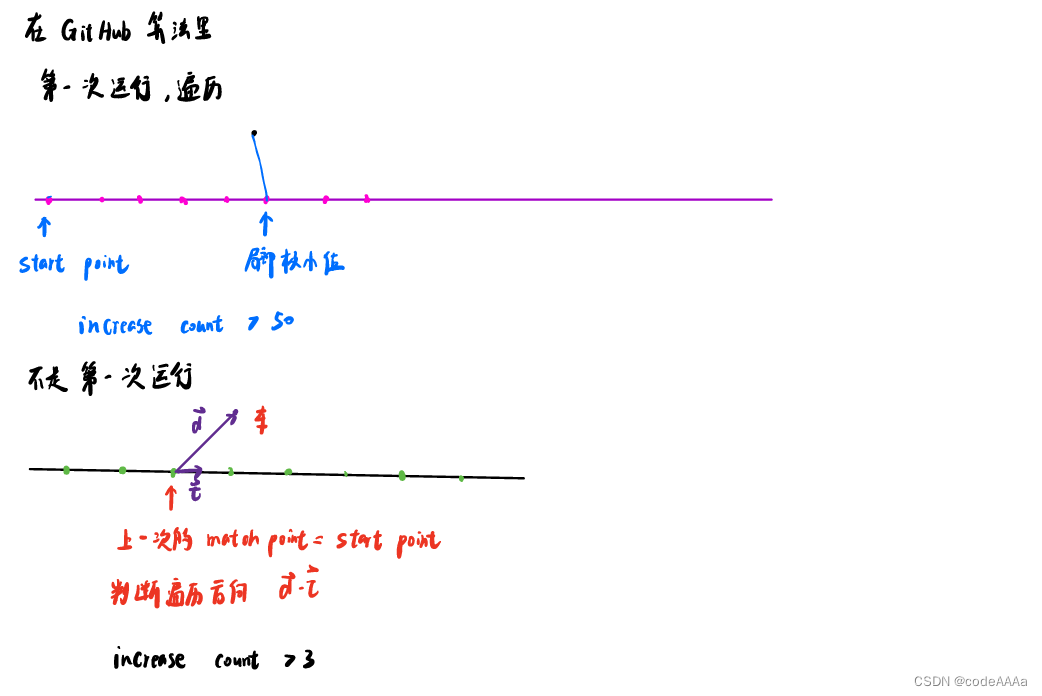
首次运行时以第一个点为起点开始遍历,increase设置为50,次数多一些,从第二点开始就以上一个规划周期的匹配点为地点开始遍历,increase count设置为3。
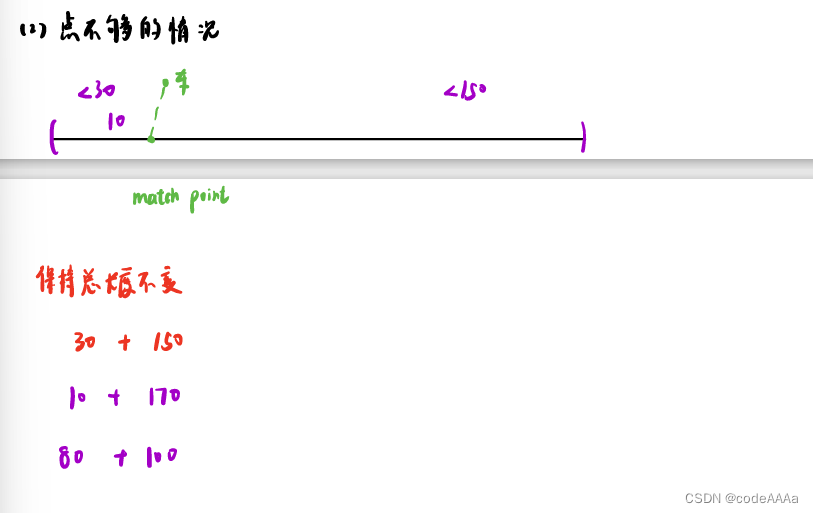
前面规定了车辆在参考线上的投影往前取150米,往后取30米,但是如果前面或者后面长度不够时,解决方案就是保持整个长度不够,因为总长度不变,优化的个数也不变,这样二次规划矩阵的尺寸也不变,更符合编程特点。
综上找到每个规划周期的匹配点,并且采用后使用二次规划参考线平滑算法就可以将每个规划周期内参考线平滑之后得到一条平滑参考线。
因为规划周期只有100ms,所以每个规划周期所选的参考线区间一定会有大量重复,需要将每个规划周期内和前面规划周期不重复的区间拼接在一起,如下:
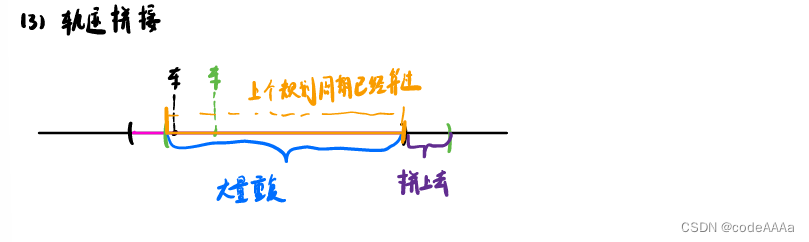
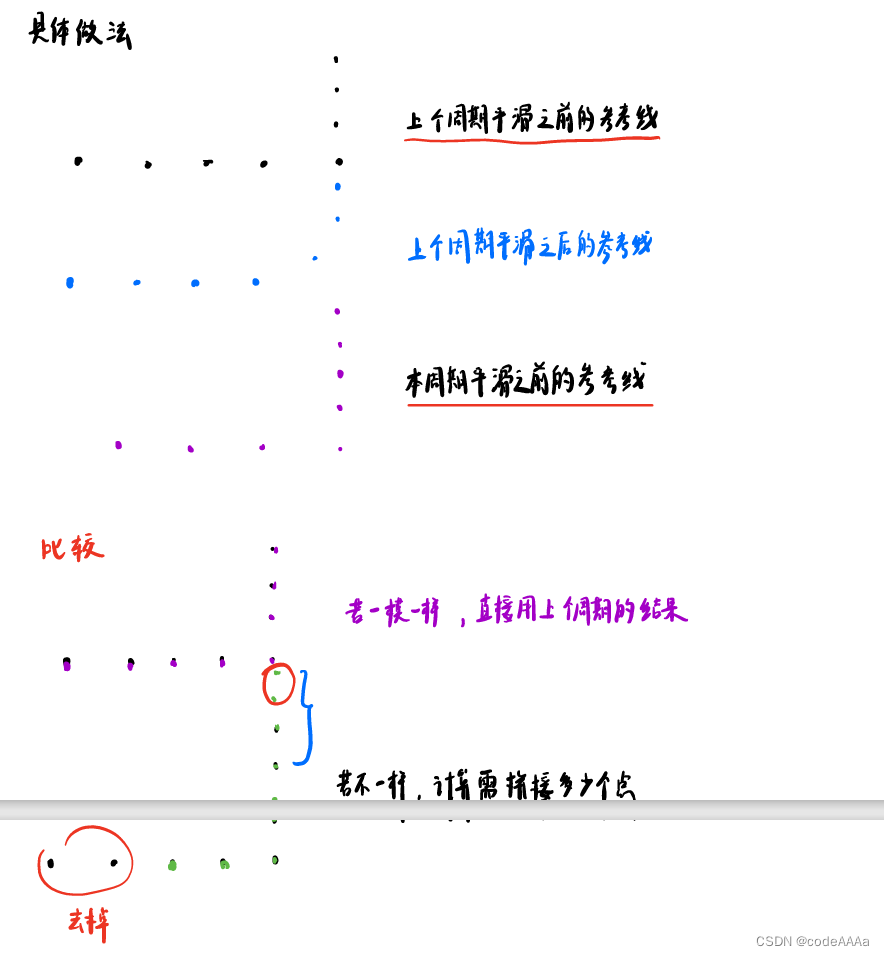
如果不一样的话,计算要拼接几个点,因为每个规划周期内参考线的点的总数是一样的,所以后面新出来几个点,后面就会多出来几个点。拼接时就要把这个规划周期内新的点添加上去,把后面的点去掉。而且重复的点在上个周期内已经平滑过了,所以在这个周期只要平滑线的点即可。同时由于fem算法它至少需要三个点,所以拼接一个点时需要借助已经算好的两个点来平滑这个点,上图是两个不一样,就至少需要关注4个点。
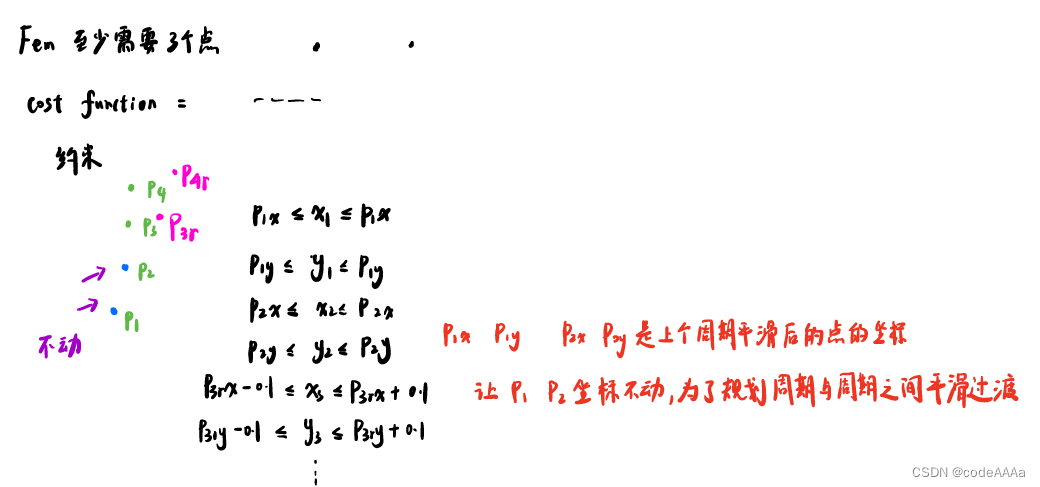
具体做法在约束中体现,优化的cost function形式和上面一样,但是优化的规模要比前面小很多,由于p1和p2是作为辅助的,所以他的坐标是不动的,具体表现在约束上就是![]() 、
、
![]() ,也就是这两个点是一个等式约束,新的点约束会稍微放松点。
,也就是这两个点是一个等式约束,新的点约束会稍微放松点。















 296
296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









