







随机点击一张图片上的人或者物,就可以让他们瞬间动起来,这项有着无限想象空间的技术已经变成现实了。
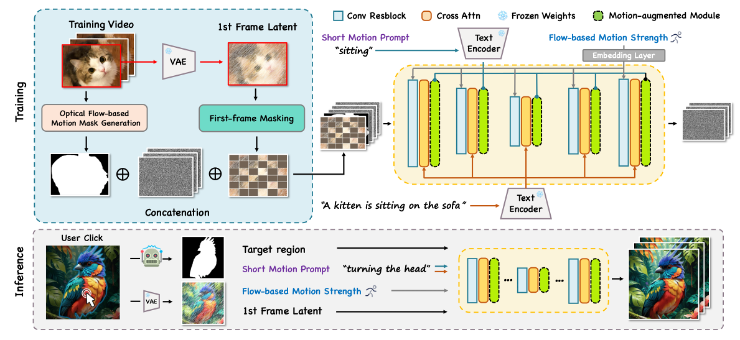
3月15日,腾讯混元和清华大学、香港科技大学联合推出全新图生视频模型“Follow-Your-Click“,基于输入模型的图片,用户只需点击对应区域,加上少量提示词,就可以让图片中原本静态的区域动起来,一键转换成视频。

虽然目前市场上已经有一些图生视频大模型,但一般的生成方法不仅需要用户在提示词中描述运动区域,还需要提供运动指令的详细描述,过程较为复杂,而且,从生成的效果来看,现有的图像生成视频技术在移动图像的指定部分上缺乏控制,生成的视频往往需要移动整个场景,而不是图像上的某一个区域,精准度和灵活性上有所欠缺。
为了解决这些问题,腾讯混元大模型团队、清华和港科大的联合项目组提出了更实用和可控的图像到视频生成模型Follow-Your-Click,带来更加便捷的交互,也让图片“一键点,万物动”成为现实。

实现方式上,“Follow-Your-Click“首先整合了图像语义分割工具Segment-Anything,将用户点击转换为二进制区域Mask,将其作为网络条件之一。其次,为了更好地正确学习时间相关性,还引入了一种有效的首帧掩模策略,这种方式对模型生成的视频质量有较大的性能提升,不论是在畸变还是首帧的重构效果上都有很大的帮助。
为了实现短提示词的文字驱动能力,研究团队构建了一个名为WebVid-Motion的数据集,通过利用大型语言模型(LLM)来过滤和注释视频标题,并强调人类情感、动作和常见物体的运动,通过数据集提升模型对动词的响应能力和识别能力。联合研究团队设计了一个运动增强模块,主要用来更好地适应数据集,并增强模型对运动相关词语的响应,并理解短提示指令。
在视频中,不同类型的物体可能表现出不同的运动速度。在先前的工作中,每秒帧数(FPS)主要作为全局的动作幅度控制参数,间接调整多个物体的运动速度。然而,它无法有效控制移动物体的速度。例如,一个展示雕塑的视频可能具有很高的FPS,但是没有物体的运动速度。
为了实现对运动速度的准确学习,研究团队还提出了一种新颖的基于光流的运动幅度控制。使用光流模长作为新的视频运动幅度控制参数。通过这些新提出来的方法以及各个模块的组合,Follow-Your-Click能够很好地使用简单文本指令来实现图像局部动画。大大提升了可控图生视频的效率和可控性。
今年以来,图像到视频生成的技术已经成为最热门的AI技术之一,这些技术在电影内容制作、增强现实、游戏制作以及广告等多个行业的AIGC应用上有着广泛前景。
论文:https://arxiv.org/abs/2403.08268
主页:https://follow-your-click.github.io/
代码链接:https://github.com/mayuelala/FollowYourClick
——完——
记得关注我们,及时接收精彩内容哦~
公众号/视频号:腾讯太极机器学习平台
腾讯太极机器学习平台,致力于让用户更加聚焦业务AI问题解决和应用,一站式解决算法工程师在应用过程中特征处理、模型训练、模型服务等工程问题。

















 331
331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









