







文章目录
一、基础理论
1.1、简介
- 决策树是一种基本的分类与回归方法。分类问题中,表示基于特征对实例进行分类的过程,它可以认为是if-then规则的集合,主要优点就是可读性强,分类速度快。学习时,利用训练数据,根据损失函数最小化的原则进行建立决策树模型。决策树学习通常包括三个步骤:特征选择、决策树的生成和决策树的剪枝。
- 决策树类似于流程图的树结构,由一个根节点,一组内部节点和一组叶节点组成。每个内部节点(包括根节点)表示在一个特征值,每个分枝表示一个特征值输出,每个叶节点表示一个类,有时不同的叶节点可以表示相同的类。
- 图中,从年龄开始分支,年龄含有3个阶段,因此分出三根树枝;41-50年龄段的类输出为c1,因此这个树枝直接输出类别c1;年龄段<=40的输出类别含有两个c1和c2,所以需要继续分支,按照公司员工分支的话,再分出两条支线是或否,公司职员为是的类别输出只有c1,因此该分支直接输出c1,公司职员为否的类别输出只有c2,因此该分支直接输出c2;信誉度原理相同。
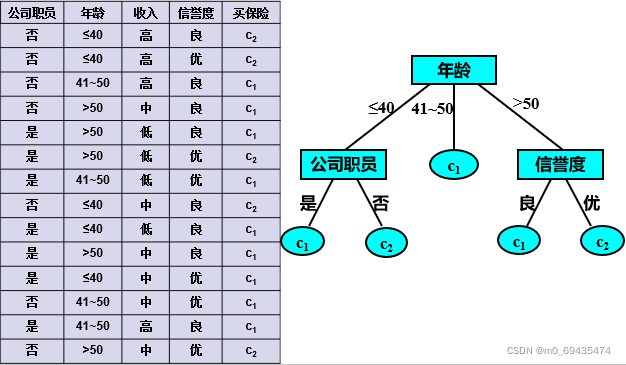
看完这张图就会有疑问了,你为什么不选择收入为节点呢?下面就看看如何选择特征进行分支的吧。
1.2、特征选择
- 特征选择在于选取对训练数据都具有分类能力的特征,这样可以提高决策树学习的效率。如果利用一个特征进行分类的结果与随即分类的结果没有很大差别,则称这个特征是没有分类能力的。经验上舍掉这种特征对决策树学习的精度影响不大。通过特征选择的准则是信息增益和信息增益比。下面通过一个例子说明特征选择的问题。

希望通过所给数据学习一个贷款申请的决策树,用以对未来的贷款申请进行分类,即当新客户提出贷款申请时,根据申请人的特征利用决策树判断是否批准贷款申请。
从表可以知道数据含有4个特征,一个类别。
1.2.1、信息增益
- 熵:表示随机变量不确定性的度量,设X为一个取有无限个值得离散随机变量,其概率分布为
P
(
X
=
x
i
)
=
p
i
,
i
=
1
,
2
,
3
…
,
n
P(X=x_i)=p_i,i=1,2,3…,n
P(X=xi)=pi,i=1,2,3…,n,那么随机变量X得熵为
H ( X ) = − ∑ i = 1 n p i l o g p i H(X)=-\sum^n_{i=1}p_ilogp_i H(X)=−i=1∑npilogpi
明显熵值与X的值无关,但与X的分布密切相关。熵越大,随机变量的不确定性越大。熵值范围[0,1]。 - 条件熵:表示再随机变量X的条件下随机变量Y的不确定性。设随机变量(X,Y),其联合分布为
P
(
X
=
x
i
,
Y
=
y
j
)
=
p
i
j
,
i
=
1
,
2
,
…
,
n
,
j
=
1
,
2
,
…
m
P(X=x_i,Y=y_j)=p_{ij},i=1,2,…,n,j=1,2,…m
P(X=xi,Y=yj)=pij,i=1,2,…,n,j=1,2,…m,条件熵为
H ( Y ∣ X ) = ∑ i = 1 n p i H ( Y ∣ X = x i ) H(Y|X)=\sum^n_{i=1}p_iH(Y|X=x_i) H(Y∣X)=i=1∑npiH(Y∣X=xi)
这里的 p i = P ( X = x i ) , i = 1 , 2 … n p_i=P(X=x_i),i=1,2…n pi=P(X=xi),i=1,2…n。
当熵和条件熵中的概率由数据估计(特别是极大似然估计)得到时,所对应的熵与条件熵分别成为经验熵和条件经验熵。 - 信息增益:表示得知特征X的信息使得类Y的信息的不确定性减少的程度。特征A对训练集D的信息增益g(D,A),定义为集合D的经验熵与特征A给定条件下D的经验条件熵H(D|A)之差,即:(信息增益越大,不确定性减少程度越大,因此选择信息增益大的作为特征。)
g ( D , A ) = H ( D ) − H ( D ∣ A ) g(D,A)=H(D)-H(D|A) g(D,A)=H(D)−H(D∣A)
1.2.3、信息增益比
- 以信息增益作为划分数据集的特征,存在偏向于取值较多的特征的问题。使用信息增益比可以对该问题进行校正。这是特征选择的另一个准则。
- 信息增益比:特征A对训练集D的信息增益比
g
R
(
D
,
A
)
g_R(D,A)
gR(D,A),定义为其信息增益g(D,A)与数据集D关于特征A的值的熵
H
A
(
D
)
H_A(D)
HA(D)之比,即:
g R ( D , A ) = g ( D , A ) H A ( D ) g_R(D,A)=\frac {g(D,A)} {H_A(D)} gR(D,A)=HA(D)g(D,A)
其中 H A ( D ) = − ∑ i = 1 n ∣ D i ∣ ∣ D ∣ l o g 2 ∣ D i ∣ ∣ D ∣ , n H_A(D)=-\sum^n_{i=1}{\frac{|D_i|}{|D|}}{log_2\frac{|D_i|}{|D|}},n HA(D)=−∑i=1n∣D∣∣Di∣log2∣D∣∣Di∣,n是特征A取值的个数。
1.3、决策树的生成
1.3.1、ID3
- 核心:在决策树各个节点上应用信息增益准则选择特征,递归的构建决策树。相当于利用极大似然法进行概率模型的选择。
- 步骤:
- 选择信息增益最大的作为节点特征,由该特征的不同值建立子节点;
- 再对子节点递归的调用上述方法,构建决策树;
- 直到所有特征的信息增益均很小或没有特征可以选为止,最后得到一棵决策树。
- 缺点:
- ID3利用的是信息增益,因此它存在偏向于取值较多的特征的问题。例如,如果有一个属性为日期,那么将有大量取值,这个属性可能会有非常高的信息增益。假如它被选作树的根结点的决策属性则可能形成一颗非常宽的树,这棵树可以理想地分类训练数据,但是对于测试数据的分类性能可能会相当差。
- ID3算法只能处理离散值的特征。
- ID3算法增长树的每一个分支的深度,直到恰好能对训练样例完美地分类。当数据中有噪声或训练样例的数量太少时,产生的树会过拟合。
- ID3算法在搜索过程中不进行回溯。所以,它易受无回溯的爬山搜索中的常见风险影响:收敛到局部最优而不是全局最优。
1.3.2、C4.5
- 与ID3算法相似,C4.5对ID3进行了算法改进,C4.5在特征选择中,用信息增益比选择特征。其余一样的步骤。
- 改进之处:
- 用信息增益比选择特征,克服了用信息增益选择特征时偏向于选择取值多的特征的不足
- 能够完成对连续特征的离散化处理
- 可以处理具有缺少特征值的训练样本
- 在树构造过程中或者构造完成之后,通过使用不同的修剪技术以避免树的过度拟合
- K折交叉验证
- C4.5处理连续属性值:
- 将训练数据集D中样本按连续特征A的值进行递增排序,一般采用快速排序法。
- 按该顺序逐一将两个相邻值的平均值a作为分割点,分割点将D划分为两个子集,分别对应特征A小于等于a和大于a的两个子集,这样最多有n-1个分割点(n为特征A的取值个数)。
- 分别计算每个分割点的信息增益比,选择具有最大信息增益比率的分割点。
- lC4.5处理特征缺失值:
- 其处理方法是用最常用的值替代或者是将最常用的值分在同一类中
- 具体采用概率的方法,依据特征已知的值,计算各特征不同值的出现概率。例如,给定一个特征A,A中包含6个已知A=1和4个A=0的实例,那么A(x)=1的概率是0.6,而A(x)=0的概率是0.4。于是,实例x60%被分配到A=1的分支,40%被分配到另一个分支,目的是计算信息增益比。
- 缺点:
- C4.5算法采用的是分而治之的策略,搜索过程中不进行回溯,在构造树的内部结点的时候是局部最优的搜索方式,所以它所得到的最终结果尽管有很高的准确性,仍然可能达不到全局最优的结果。
- C4.5算法用一边构造决策树一边进行评价的方法构造决策树,当决策树构造出来之后,很难再调整树的结构和内容,决策树性能的改善十分困难。
- C4.5算法也会产生过度拟合问题。
- ID3算法和C4.5算法都是在建树时将训练集一次性装载入内存的。但当面对有着上百万条数据时,就无法实际应用这些算法。
1.4、决策树的剪枝
决策树生成算法递归的产生决策树,直到不能继续下去为止。这样产生的决策树对训练数据的分类很准确,但对测试数据的分类没有那么准确,即出现过拟合现象。过拟合的原因在于学习时过多的考虑对训练数据的正确分类,从而构建出复杂的决策树。解决这个问题的办法就是对决策树进行剪枝,使决策树简化。决策树简化的过程就叫做剪枝。
- 预剪枝(pre-pruning):预剪枝就是在构造决策树的过程中,先对每个结点在划分前进行估计,若果当前结点的划分不能带来决策树模型泛华性能的提升,则不对当前结点进行划分并且将当前结点标记为叶结点。预剪枝使得决策树的很多分支都不会展开,这不仅降低了过拟合的风险,还显著减少了决策树的训练时间和测试时间。采用了贪心的思想,适合大规模问题。但预剪枝可能提前停止生长,有可能存在欠拟合的风险。
- 后剪枝(post-pruning):后剪枝就是先把整颗决策树构造完毕,然后自底向上的对非叶结点进行考察,若将该结点对应的子树换为叶结点能够带来泛华性能的提升,则把该子树替换为叶结点。可以最大限度的保留树的各个节点,避免了欠拟合的风险。相较于预剪枝的时间开销巨大。
关于剪枝的内容可以参考其他博主的这篇文章,他把剪枝的过程写的很详细,可以看看。我觉得还是挺全面的。
决策树(decision tree)(二)——剪枝
1.5、例子(ID3算法)
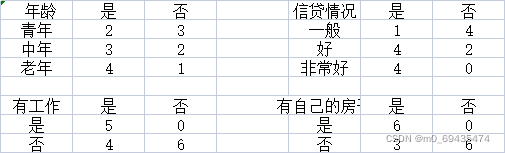
经验熵为
H
(
D
)
=
−
∑
i
=
1
n
p
i
l
o
g
p
i
=
−
6
15
l
o
g
6
15
−
9
15
l
o
g
9
15
=
0.971
H(D)=-\sum^n_{i=1}p_ilogp_i=-\frac{6} {15}log\frac{6}{15}-\frac{9} {15}log\frac{9}{15}=0.971
H(D)=−∑i=1npilogpi=−156log156−159log159=0.971
计算各特征对数据集D的信息增益,分别以A1,A2,A3,A4表示年龄、有工作、有自己的房子和信贷情况4个特征,则经验条件熵分别为:(按照特征取值分为n个子集,再计算子集熵,按比例加起来)
H
(
D
∣
A
1
)
=
∑
i
=
1
n
p
i
H
(
Y
∣
X
=
x
i
)
=
5
15
∗
(
−
2
5
l
o
g
2
5
−
3
5
l
o
g
3
5
)
+
5
15
∗
(
−
3
5
l
o
g
3
5
−
2
5
l
o
g
2
5
)
+
5
15
∗
(
−
4
5
l
o
g
4
5
−
1
5
l
o
g
1
5
)
=
0.888
H(D|A_1)=\sum^n_{i=1}p_iH(Y|X=x_i)=\frac{5}{15}*(-\frac{2} {5}log\frac{2}{5}-\frac{3} {5}log\frac{3}{5})+\frac{5}{15}*(-\frac{3} {5}log\frac{3}{5}-\frac{2} {5}log\frac{2}{5})+\frac{5}{15}*(-\frac{4} {5}log\frac{4}{5}-\frac{1} {5}log\frac{1}{5})=0.888
H(D∣A1)=∑i=1npiH(Y∣X=xi)=155∗(−52log52−53log53)+155∗(−53log53−52log52)+155∗(−54log54−51log51)=0.888
H ( D ∣ A 2 ) = ∑ i = 1 n p i H ( Y ∣ X = x i ) = 5 15 ∗ ( − 5 5 l o g 5 5 − 0 5 l o g 0 5 ) + 10 15 ∗ ( − 4 10 l o g 4 10 − 6 10 l o g 6 10 ) = 0.647 H(D|A_2)=\sum^n_{i=1}p_iH(Y|X=x_i)=\frac{5}{15}*(-\frac{5} {5}log\frac{5}{5}-\frac{0} {5}log\frac{0}{5})+\frac{10}{15}*(-\frac{4} {10}log\frac{4}{10}-\frac{6} {10}log\frac{6}{10})=0.647 H(D∣A2)=∑i=1npiH(Y∣X=xi)=155∗(−55log55−50log50)+1510∗(−104log104−106log106)=0.647
H ( D ∣ A 3 ) = ∑ i = 1 n p i H ( Y ∣ X = x i ) = 6 15 ∗ ( − 6 6 l o g 6 6 − 0 6 l o g 0 6 ) + 9 15 ∗ ( − 3 9 l o g 3 9 − 6 9 l o g 6 9 ) = 0.551 H(D|A_3)=\sum^n_{i=1}p_iH(Y|X=x_i)=\frac{6}{15}*(-\frac{6} {6}log\frac{6}{6}-\frac{0} {6}log\frac{0}{6})+\frac{9}{15}*(-\frac{3} {9}log\frac{3}{9}-\frac{6} {9}log\frac{6}{9})=0.551 H(D∣A3)=∑i=1npiH(Y∣X=xi)=156∗(−66log66−60log60)+159∗(−93log93−96log96)=0.551
H
(
D
∣
A
4
)
=
∑
i
=
1
n
p
i
H
(
Y
∣
X
=
x
i
)
=
5
15
∗
(
−
1
5
l
o
g
1
5
−
4
5
l
o
g
4
5
)
+
6
15
∗
(
−
4
6
l
o
g
4
6
−
2
6
l
o
g
2
6
)
+
4
15
∗
(
−
4
4
l
o
g
4
4
−
0
4
l
o
g
0
4
)
=
0.608
H(D|A_4)=\sum^n_{i=1}p_iH(Y|X=x_i)=\frac{5}{15}*(-\frac{1} {5}log\frac{1}{5}-\frac{4} {5}log\frac{4}{5})+\frac{6}{15}*(-\frac{4} {6}log\frac{4}{6}-\frac{2} {6}log\frac{2}{6})+\frac{4}{15}*(-\frac{4} {4}log\frac{4}{4}-\frac{0} {4}log\frac{0}{4})=0.608
H(D∣A4)=∑i=1npiH(Y∣X=xi)=155∗(−51log51−54log54)+156∗(−64log64−62log62)+154∗(−44log44−40log40)=0.608
各特征的信息增益为:
g
(
D
,
A
1
)
=
H
(
D
)
−
H
(
D
∣
A
1
)
=
0.971
−
0.888
=
0.083
g(D,A_1)=H(D)-H(D|A_1)=0.971-0.888=0.083
g(D,A1)=H(D)−H(D∣A1)=0.971−0.888=0.083
g
(
D
,
A
2
)
=
H
(
D
)
−
H
(
D
∣
A
2
)
=
0.971
−
0.647
=
0.324
g(D,A_2)=H(D)-H(D|A_2)=0.971-0.647=0.324
g(D,A2)=H(D)−H(D∣A2)=0.971−0.647=0.324
g
(
D
,
A
3
)
=
H
(
D
)
−
H
(
D
∣
A
3
)
=
0.971
−
0.551
=
0.420
g(D,A_3)=H(D)-H(D|A_3)=0.971-0.551=0.420
g(D,A3)=H(D)−H(D∣A3)=0.971−0.551=0.420
g
(
D
,
A
4
)
=
H
(
D
)
−
H
(
D
∣
A
4
)
=
0.971
−
0.608
=
0.363
g(D,A_4)=H(D)-H(D|A_4)=0.971-0.608=0.363
g(D,A4)=H(D)−H(D∣A4)=0.971−0.608=0.363
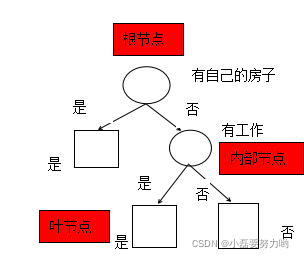
最后,比较各特征的信息增益,由于A3即有自己的房子的信息增益最大,因此选择有自己的房子为最优特征。根节点为有自己的房子。
- 有自己的房子特征值为是的类别输出都为是,因此左支结束分支,特征值为否的类别输出既有是也有否,因此需要找特征继续分支。这次的数据子集为有自己的房子的特征值为否的数据,即9条数据,记为数据集D2(A3=否)。
对D2则需从A1.A2,A4中选择新的特征,计算各特征的信息增益:
以A1为例,类别是有3个数据,否有6个数据,根据这个计算D2的熵H(D2);年龄含有3个取值,青年(共4条数据,输出类别是1条,否3条)、中年(2条数据,输出类别是2条)、老年(3条数据,输出类别是2条,否1条)。
g ( D 2 , A 1 ) = H ( D 2 ) − H ( D 2 ∣ A 1 ) = ( − 3 9 l o g 3 9 − 6 9 l o g 6 9 ) − [ 4 9 ( − 3 4 l o g 3 4 − 1 4 l o g 1 4 ) + 2 9 ( − 2 2 l o g 2 2 − 0 2 l o g 0 2 ) + 3 9 ( − 2 3 l o g 2 3 − 1 3 o g 1 3 ) ] = 0.251 g(D_2,A_1)=H(D_2)-H(D_2|A_1)=(-\frac3 9log\frac3 9-\frac6 9log\frac6 9)-[\frac4 9(-\frac3 4log\frac3 4-\frac1 4log\frac1 4)+\frac2 9(-\frac2 2log\frac2 2-\frac0 2log\frac0 2 )+\frac 3 9(-\frac2 3log\frac2 3-\frac1 3og\frac1 3 )]=0.251 g(D2,A1)=H(D2)−H(D2∣A1)=(−93log93−96log96)−[94(−43log43−41log41)+92(−22log22−20log20)+93(−32log32−31og31)]=0.251
同理: g ( D 2 , A 2 ) = 0.918 g(D_2,A_2)=0.918 g(D2,A2)=0.918, G ( D 2 , A 4 ) = 0.474 G(D_2,A_4)=0.474 G(D2,A4)=0.474
信息增益最大的是A2(有工作),因此针对A1特征为否的数据集继续按照A2(有工作)进行划分,A2=是的类别输出都为是,不需要继续分支了;A2=否的类别输出都为否,也不需要继续分支了。这样就生成了决策树,仅仅用了两个特征就完成了决策树的生成。如下:
二、python实战
2.1、重要参数
- Criterion这个参数正是用来决定模型特征选择的计算方法的。sklearn提供了两种选择:
输入”entropy“,使用信息熵(Entropy)
输入”gini“,使用基尼系数(Gini Impurity) - random_state & splitter
random_state用来设置分枝中的随机模式的参数,默认None,在高维度时随机性会表现更明显。
splitter也是用来控制决策树中的随机选项的,有两种输入值,输入”best",决策树在分枝时虽然随机,但是还是会优先选择更重要的特征进行分枝(重要性可以通过属性feature_importances_查看),输入“random",决策树在分枝时会更加随机,树会因为含有更多的不必要信息而更深更大,并因这些不必要信息而降低对训练集的拟合。 - max_depth
限制树的最大深度,超过设定深度的树枝全部剪掉。这是用得最广泛的剪枝参数,在高维度低样本量时非常有效。决策树多生长一层,对样本量的需求会增加一倍,所以限制树深度能够有效地限制过拟合。 - min_samples_leaf
min_samples_leaf ,一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本,否则分枝就不会发生,或者,分枝会朝着满足每个子节点都包含min_samples_leaf个样本的方向去发生。一般搭配max_depth使用,在回归树中有神奇的效果,可以让模型变得更加平滑。这个参数的数量设置得太小会引起过拟合,设置得太大就会阻止模型学习数据。
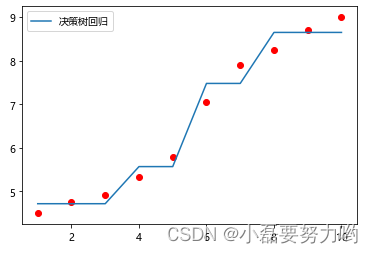
2.2、回归
import numpy as np
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.tree import DecisionTreeRegressor,plot_tree
plt.rcParams['font.sans-serif'] =['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 构造数据集
x = np.array([1,2,3,4,5,6,7,8,9,10])
y = [4.5,4.75,4.91,5.34,5.80,7.05,7.90,8.23,8.70,9]
# 创建决策树回归实例,树的最大深度为2
DR = DecisionTreeRegressor(max_depth=2)
# 拟合 输入数据必须是二维数组 reshape(-1,1)将一维数组转化为二维数组
tree_DR = DR.fit(x.reshape(-1,1),y)
# 散点图
plt.scatter(x,y,color='r',marker='o')
# 决策树回归线
plt.plot(x,tree_DR3.predict(x.reshape(-1,1)),label='决策树回归')
plt.legend()
plt.show()
2.3、分类
import numpy as np
from sklearn.tree import DecisionTreeClassifier # 决策树分类器
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.tree import plot_tree # 决策树可视化
from sklearn.datasets import load_iris # 鸾尾花数据集
from sklearn.model_selection import train_test_split # 训练集测试集分割
from sklearn.metrics import accuracy_score # 准确度
plt.rcParams['font.sans-serif'] =['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
x = load_iris().data # 输入特征
y = load_iris().target # 输出类别
x_train,x_test,y_train,y_test= train_test_split(x,y,test_size=0.3,random_state=2022) # 按3:7分割测试集和训练集
destree = DecisionTreeClassifier(criterion='entropy',splitter='best',max_depth=3)# 利用信息熵准则生成决策树 最大深度为3
dd = destree.fit(x_train,y_train) # 训练数据
ytest_pre = destree.predict(x_test) # 预测测试集
ytrain_pre = destree.predict(x_train) # 预测训练集
print(f'训练集准确度:{accuracy_score(y_train,ytrain_pre)}')
print(f'测试集准确度:{accuracy_score(y_test,ytest_pre)}')
训练集准确度:0.9619047619047619
测试集准确度:0.9555555555555556
print(dd.feature_importances_) # 四个特征的重要性 最重要的是特征3,其次是特征4,最后是特征2和特征1
[0.01950424 0.04832737 0.64638568 0.28578271]
plt.figure(figsize=(8,6))
plot_tree(dd) # 决策树可视化
plt.show()
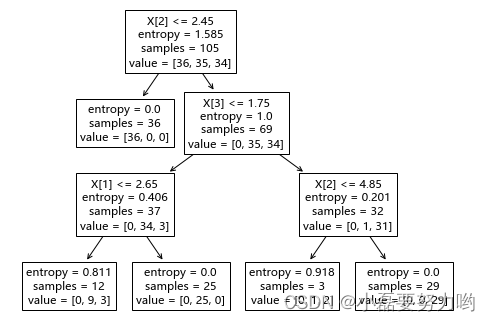
- 输入四个特征,根据信息增益准则首先选取了特征3(X[2])分支,左枝value[36,0,0]表示X[2]<=2.45的鸾尾花全部为类别1,不需要往下分支了;而右枝value=[0,35,34]说明x[2]>2.45的含有35条类别2的数据和34条类别3的数据,需要继续选择重要性第二的特征4(x[3])分支,以x[3]=1.75为分割点,……,最后还是含有value=[0,9,3]和[0,1,2]表明这类中还是含有混合类别的,但我们在创建决策树时定义了最大深度为3,因此没有分完也必须终止分支了。如果不指定最大深度,默认直至全部类别都划分开结束分支。
参考:
《统计学习方法 李航著》
课后ppt















 5574
5574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









