






一、环境安装
准备工作:
1.安装Anaconda
2.安装CUDA
3.安装CUDnn
4.安装PyTorch
5.下载labelme
检验环境:
依次输入:
python
import torch
torch.cuda.is_available()
如果返回“True”,说明 PyTorch 安装成功且版本互相匹配。输入 exit() 退出 python。
二、Unet使用及部署
2.1数据集准备
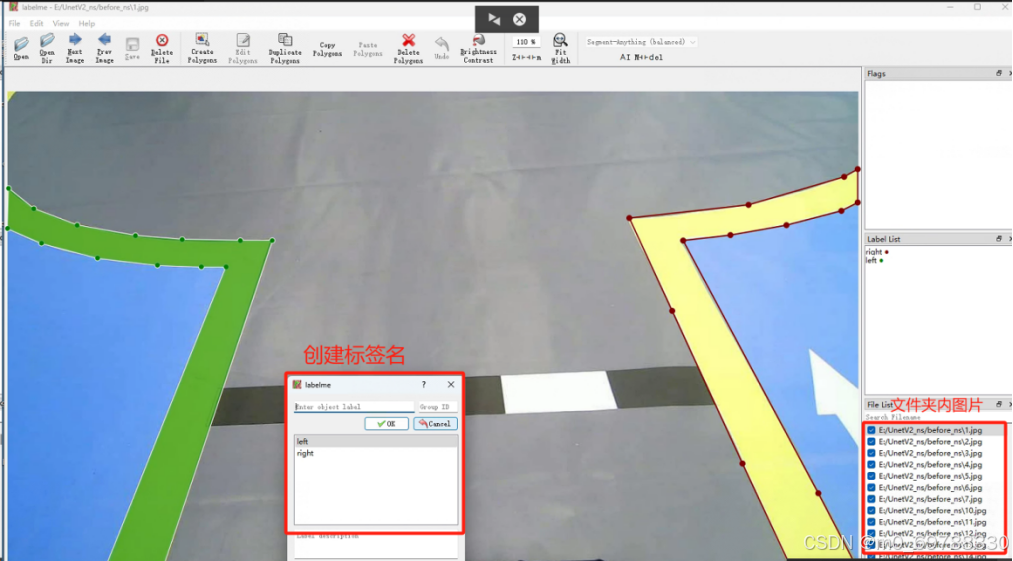
1.首先准备好训练的图片(.jpg),必须要保证图片名称1.jpg,2.jpg,3.jpg...将照片都存放在before_ns文件夹下,通过labelme打特征标签,比如车道线检测,打两侧的标签。打完之后的标签后缀名为json,打开文件夹before_ns,选择createpolygons创建目标,若出现错误,可选择editpolygons进行修改。
2.2相关文件转换
1.打完所有标签之后,提取before_ns中的所有jpg文件到文件夹jpg下,提取before_ns中的所有json文件到文件夹json下。
2.通过jpg2png.py将jpg文件夹下的所有图片转为png格式,保存在png文件夹下。
#!/usr/bin/python
# -*- coding:utf8 -*-
import os
from PIL import Image
def convert_images(source_dir, output_dir, source_format, output_format):
# 创建输出文件夹
os.makedirs(output_dir, exist_ok=True)
# 遍历图片文件夹中所有 jpg 格式的图片
for filename in os.listdir(source_dir):
if filename.endswith(source_format):
# 打开图片
image_path = os.path.join(source_dir, filename)
image = Image.open(image_path)
# 构造输出文件路径
output_path = os.path.join(output_dir, os.path.splitext(filename)[0] + output_format)
# 转换并保存图片
image.save(output_path, format=output_format[1:])
print("图片转换完成!")
# 示例用法
source_directory = r"./UnetV2_ns/jpg"
output_directory = r"./UnetV2_ns/png1"
source_image_format = ".jpg"
output_image_format = ".png"
convert_images(source_directory, output_directory, source_image_format, output_image_format)3.通过json_to_data.py将json文件进行语义分割,结束之后会打印出已打标签和background,将所得结果放在seg文件夹下。
import argparse
import base64
import json
import os
import os.path as osp
import imgviz
import PIL.Image
import numpy
from labelme.logger import logger
from labelme import utils
def main():
logger.warning(
"This script is aimed to demonstrate how to convert the "
"JSON file to a single image dataset."
)
logger.warning(
"It won't handle multiple JSON files to generate a "
"real-use dataset."
)
# json_file是标注完之后生成的json文件的目录。out_dir是输出目录,即数据处理完之后文件保存的路径
json_file = r"./UnetV2_ns/json"
out_dir1 = r"./UnetV2_ns/seg"
# 如果输出的路径不存在,则自动创建这个路径
if not osp.exists(out_dir1):
os.mkdir(out_dir1)
# 将类别名称转换成数值,以便于计算
label_name_to_value = {"_background_": 0}
for file_name in os.listdir(json_file):
# 遍历json_file里面所有的文件,并判断这个文件是不是以.json结尾
if file_name.endswith(".json"):
path = os.path.join(json_file, file_name)
if os.path.isfile(path):
data = json.load(open(path))
# 获取json里面的图片数据,也就是二进制数据
imageData = data.get("imageData")
# 如果通过data.get获取到的数据为空,就重新读取图片数据
if not imageData:
imagePath = os.path.join(json_file, data["imagePath"])
with open(imagePath, "rb") as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode("utf-8")
# 将二进制数据转变成numpy格式的数据
img = utils.img_b64_to_arr(imageData)
for shape in sorted(data["shapes"], key=lambda x: x["label"]):
label_name = shape["label"]
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
lbl, _ = utils.shapes_to_label(img.shape, data["shapes"], label_name_to_value)
label_names = [None] * (max(label_name_to_value.values()) + 1)
for name, value in label_name_to_value.items():
label_names[value] = name
lbl_viz = imgviz.label2rgb(
label=lbl, image=imgviz.asgray(img), label_names=label_names, loc="rb"
)
# out_dir = osp.basename(file_name).replace('.', '_')
# out_dir = osp.join(out_dir1, out_dir)
# if not osp.exists(out_dir):
# os.mkdir(out_dir)
# print(out_dir)
# 将输出结果保存,
# PIL.Image.fromarray(img).save(osp.join(out_dir1, "%s_img.jpg" % file_name.split(".")[0]))
utils.lblsave(osp.join(out_dir1, "%s.png" % file_name.split(".")[0]), lbl)
# PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir1, "%s_label_viz.png"%file_name.split(".")[0]))
# with open(osp.join(out_dir, "label_names.txt"), "w") as f:
# for lbl_name in label_names:
# f.write(lbl_name + "\n")
logger.info("Saved to: {}".format(out_dir1))
print("label:", label_name_to_value)
if __name__ == "__main__":
main()4.接下来把上述得到的seg文件夹图片放到./UnetV2_ns/train_ns_data/SegmentationClass下。
5.接下来把上述得到的png文件夹图片放到./UnetV2_ns/train_ns_data/JPEGImagesxia下。


2.3模型训练
运行src/train.py
import os
# import os是Python中常用的导入操作系统相关功能的模块。os模块提供了许多函数和方法,用于与操作系统交互,例如处理文件和目录、执行系统命令、获取环境变量等。通过导入os模块,我们可以在Python程序中使用这些操作系统相关的功能。
import datetime # datetime模块提供了处理日期和时间的类和函数,使得我们可以在Python程序中进行日期和时间的操作和计算。
import tqdm # tqdm是一个用于在命令行中显示进度条的库,它可以用于跟踪迭代过程中的进度,让代码执行过程更加直观和可视化。
from torch import nn, optim # nn模块是PyTorch中最常用的模块之一,其中包含了许多用于构建深度神经网络的类和函数。
import torch
from Unet import *
from torchvision.utils import save_image # 导入了PyTorch的torchvision库中的save_image函数。torchvision是PyTorch提供的一个辅助库,用于处理计算机视觉相关的任务,包括数据处理、图像转换、预训练模型等。 save_image函数用于将多张图像保存成一张合并的图像,通常用于可视化模型输出、数据重建等场景。它接受一个张量(或一个批次的张量)和一个输出文件路径作为输入,将张量中的多张图像按照指定的方式合并并保存为一张图像。
import cv2
import subprocess # 通过subprocess模块,你可以在Python中执行一些需要调用其他命令行工具或外部程序的任务,例如运行系统命令、调用其他脚本、执行shell脚本等。
import time
import tools
# 例如,如果在 "tools" 模块中有一个名为 function_name() 的函数,你可以在当前脚本中通过调用 tools.function_name() 来使用它。 需要注意的是,"tools" 模块必须在 Python 环境中可用。你可能需要确保 "tools.py" 文件或 "tools" 包位于与你的脚本相同的目录中,或者通过 Python 路径可以访问它。否则,Python 将会引发 ImportError,表示找不到该模块。
from torch.utils.tensorboard import SummaryWriter
# -----------------------------------------------------------------------------------------------------------
data_path = './UnetV2_ns/train_ns_data' # 该目录下必须有JPEGImages和SegmentationClass这两个文件夹
train_epoch = 30 # 训练次数 后期可以改成训练100次
max_batch_size = 8 # 表示每个批次的样本数量
num_classes = 4 + 1 # +1是背景也为一类
train_lr = 0.001 # 学习率
# -----------------------------------------------------------------------------------------------------------
tools.check(train_epoch)
# 是一个函数调用,它可能是由开发者在自定义的tools模块中实现的一个函数。根据函数名的含义,它可能是用于检查train_epoch变量的合法性或有效性。通常,在代码中使用tools.check(train_epoch)的目的是为了确保train_epoch的值满足某种条件或范围,以防止在后续的训练过程中出现问题或错误。例如,可能会检查train_epoch是否为正整数,并且不小于一个最小值,以确保训练的轮数设置正确。或者也可能是检查train_epoch是否为合理的范围,避免过多的训练轮数导致过拟合。具体的函数实现和用法需要查看tools模块的代码,或者根据上下文了解函数的用途和参数含义。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 如果系统支持 CUDA,就将设备设置为 GPU;否则,将设备设置为 CPU。这样,在后续的代码中,可以根据 device 变量的值来决定模型在何处运行。
save_dir = 'C:/Users/Administrator/Desktop/生产实习/UnetV2_ns/UnetV2_ns/params'
# 保存模型的根文件夹路径 将训练过程中的损失函数值、模型权重、验证结果等保存在 save_dir 目录下的不同子目录中,以便于跟踪训练过程和进行结果评估。
weight_path = tools.mkdirr(save_dir)
# 这样做的目的是为了创建一个用于存储模型权重的目录。在训练过程中,模型的权重会被保存到 weight_path 目录下,以便后续的加载和使用。通过将模型权重保存到单独的目录中,可以方便地管理和访问这些文件,并在需要时进行模型的加载和恢复。
save_path = os.path.join(weight_path, "train_result")
# 训练结果可视化的存储路径 通过调用 os.path.join(weight_path, "train_result"),可以将这两个路径组合在一起,形成一个新的路径,该路径指向 weight_path 目录下的 "train_result" 子目录。
if not os.path.exists(save_path): # 是一个条件语句,用于检查路径 save_path 是否存在。如果路径不存在,就会执行条件语句块中的代码。
os.makedirs(save_path)
# save_path 是之前通过 os.path.join(weight_path, "train_result") 得到的路径,用于指向保存训练结果的目录。所以,这行代码用于创建名为 "train_result" 的目录,以便将训练结果保存在其中。如果该目录已经存在,则不会进行任何操作。
time.sleep(1) # 在这个上下文中,time.sleep(1) 可能用于在每次循环迭代之间添加一秒钟的延迟,以降低程序的执行速度或避免资源过度使用。这样做可以防止程序运行过快,导致可能的问题或错误。
train_loss_list = []
# train_loss_list 是一个空列表,用于存储每个训练步骤(epoch)的训练损失值。在训练神经网络时,通常会在每个训练步骤结束后计算损失,并将其添加到该列表中,以便在训练过程结束后进行损失的可视化、分析或记录。通过记录训练损失,可以帮助我们监控模型的训练进度和性能,以及进行后续的优化和调整。
ptname = []
# ptname 是一个空列表,用于存储每个训练步骤(epoch)结束后保存的模型权重文件名。在训练神经网络时,通常会在每个训练步骤结束后将当前模型的权重保存到磁盘,以便在训练过程中定期保存模型的状态,避免因意外中断或其他问题导致的训练进度丢失。将权重文件名添加到 ptname 列表中,可以记录每个训练步骤保存的模型状态,并在训练结束后可以根据需要选择最优的模型进行后续的评估和使用。
if __name__ == '__main__':
data_loader = tools.ReadData(data_path,
max_batch_size) # 通常,在深度学习训练过程中,数据集往往是庞大的,无法一次性全部载入到内存中。因此,数据加载器的作用就是按照指定的批量大小,将数据集分批加载到内存中,并在每个训练迭代中提供这些批量数据给模型进行训练。
# net = UNet(num_classes).to(device) # old big model
net = UNet(out_channels=num_classes).to(
device) # 在这段代码中,创建了一个名为 net 的 UNet 模型,并将其移动到设备 device 上进行计算。与之前注释的代码不同的是,这里使用了一个额外的参数 out_channels 来定义 UNet 模型输出的通道数。在 UNet 中,输出通道数决定了分割结果的通道数,也就是图像分割任务中需要预测的类别数量。因此,out_channels 可以看作是分割任务中的类别数目。通常情况下,out_channels 会包括目标物体类别和背景类别,所以至少为 2。如果任务涉及更多的类别,例如对多类别的图像进行分割,out_channels 就会相应地增加。这段代码创建了一个 UNet 模型,并定义其输出通道数为 num_classes,然后将模型移动到设备 device 上,准备进行训练或推断。
opt = optim.Adam(net.parameters(),
lr=train_lr) # 这段代码创建了一个 Adam 优化器(optim.Adam)来优化神经网络模型的参数。优化器的作用是根据损失函数的梯度信息来更新模型参数,使得模型能够更好地拟合训练数据。net.parameters(): 这里传入了 net 模型的参数,它会返回模型中所有需要优化的参数。在这里,Adam优化器将会更新UNet模型中所有需要训练的权重和偏置。lr = train_lr: 这里的train_lr是之前定义的学习率,它决定了优化器每次更新参数时的步长。学习率是一个超参数,需要进行调整以获得更好的训练结果。通常情况下,学习率越大,模型收敛速度越快,但可能会导致不稳定的训练过程;学习率越小,模型收敛速度越慢,但可能会得到更好的结果。
loss_fun = nn.CrossEntropyLoss() # 定义损失函数,在训练过程中,我们将模型的输出与真实标签传递给交叉熵损失函数,该函数会根据预测概率和真实标签计算损失值。然后通过反向传播算法将损失反向传递给模型的参数,以便优化模型,使其在语义分割任务中能够更准确地预测像素的类别。最终,我们希望通过最小化交叉熵损失来使模型在训练数据上表现得更好,并在测试数据上表现出良好的泛化能力。
epoch = 0
# 设置了初始的训练轮数(epoch)在神经网络的训练过程中,一个epoch表示将所有训练数据都过一遍的训练周期。在每个epoch中,训练数据会被分成多个batch(批次),每个batch包含一定数量的样本。模型通过处理每个batch中的样本并更新参数来进行训练。当所有训练数据都被使用过一次,即完成了一个epoch,模型就完成了一次完整的训练。在初始时,将epoch设置为0表示还没有进行任何训练,训练过程将从第一个epoch开始。随着训练的进行,epoch的值会逐渐增加,直到达到预设的训练轮数。
min_loss = float('inf')
# min_loss = float('inf') 这行代码将min_loss设置为正无穷大。在训练过程中,我们通常会跟踪损失函数的值,以便在训练过程中找到最小的损失值,即最佳的模型参数。通过将min_loss初始化为正无穷大,可以确保在训练过程中的初始时刻,任何损失值都会比min_loss小,从而确保第一个epoch的损失值被记录下来,并作为初始最小损失值。随着训练的进行,如果发现新的损失值比min_loss更小,就会将min_loss更新为新的最小损失值。这样,最终min_loss将保存整个训练过程中的最小损失值,对应的模型参数也会被记录下来。这个过程通常用于保存最佳的模型,以便在训练结束后选择损失最小的模型进行评估或应用。
starttime = time.time()
# starttime = time.time() 这行代码用于记录当前时间,以便后续计算训练的总时长。在深度学习训练过程中,经常需要知道训练所花费的时间,特别是在训练时间较长的情况下,这可以帮助了解模型的训练效率和性能。通过记录训练开始的时间戳starttime,可以在训练结束后计算训练的总时长,即endtime - starttime,从而得到模型训练所花费的时间。
def compute_accuracy(out_image, segment_image):
_, predicted = torch.max(out_image, 1)
correct = (predicted == segment_image).sum().item()
total = segment_image.size(0)
accuracy = correct / total
return accuracy
while epoch < train_epoch: # 这个while循环用于执行训练过程,循环的条件是epoch < train_epoch,即训练的当前轮数小于设定的总训练轮数train_epoch。在每次循环迭代中,会执行一轮完整的训练过程,包括前向传播、计算损失、反向传播和优化器更新。训练过程会一直进行,直到达到设定的总训练轮数为止。
# 训练步骤开始
for i, (image, segment_image) in enumerate(tqdm.tqdm(
data_loader)): # 在这个循环中,enumerate函数用于遍历数据加载器data_loader中的批次数据,并且通过tqdm.tqdm函数包装,显示一个进度条,使得在训练过程中可以实时观察到训练进度。在每次循环迭代中,i是当前迭代的索引,image是训练样本图像,segment_image是对应的标签图像。data_loader会从数据集中加载一批批次的图像和标签,并将它们传递给训练模型。然后,你可以使用这些图像和标签进行模型的训练和优化。
image, segment_image = image.to(device), segment_image.to(
device) # 在这行代码中,image和segment_image被移动到计算设备(GPU或CPU),以便在模型的训练过程中使用。image.to(device)用于将image张量移动到指定的计算设备。如果计算设备是GPU,它将被移动到GPU上,如果计算设备是CPU,它将保持在CPU上。同样,segment_image.to(device)也将segment_image张量移动到相同的计算设备。这样做是为了确保模型和数据都在同一个设备上运行,以获得更好的训练性能。
# cv2.imshow('image',image)
# cv2.imshow('segment_image',segment_image)
# print(segment_image.shape)
out_image = net(
image) # 在这个代码片段中,使用训练好的神经网络模型net对输入图像image进行推断(inference)。神经网络模型会将输入图像作为输入,并输出对应的预测结果out_image。根据代码的上下文,out_image可能是一个包含预测标签的张量或矩阵,用于表示图像中每个像素点所属的类别或类别概率。在深度学习中,神经网络通过前向传播(forward pass)将输入数据经过一系列的权重和激活函数的运算,得到输出结果。在图像分割任务中,输出的out_image通常是一个与输入图像大小相同的矩阵,每个元素表示对应像素点的预测标签。请注意,在这段代码中,image和out_image都被移动到了GPU设备(如果有可用的GPU),这是为了加速计算和利用GPU的并行计算能力。这样的操作通常通过image.to(device)和out_image.to(device)实现,其中device是指定的硬件设备,可以是'cpu'或'cuda',具体取决于计算环境和硬件支持情况。
# print(out_image.shape)
train_loss = loss_fun(out_image,
segment_image.long()) # 在这行代码中,计算了训练损失(train_loss)。损失函数(loss_fun)被用来计算模型的预测结果 out_image 与真实标签 segment_image 之间的差异,也就是模型在当前批次(batch)的训练数据上的性能。损失函数是深度学习中的关键部分,用于量化模型的性能,帮助模型学习如何优化参数,使得预测结果更接近真实标签。计算训练损失后,可以利用该损失来优化模型的参数,帮助模型更好地拟合训练数据,以提高图像分割任务的准确性。通常在后续代码中会调用优化器(optimizer)的backward()和step()函数,来实现自动求导和参数更新过程。
# 优化器优化模型
opt.zero_grad() # opt.zero_grad()是用来清空优化器中保存的参数的梯度信息的函数。在训练神经网络时,优化器用于更新模型的参数,通过最小化损失函数来提高模型性能。在每一轮迭代中,首先需要计算损失函数关于模型参数的梯度,然后根据梯度信息来更新参数。
train_loss.backward() # train_loss.backward()是用于执行反向传播的函数。在深度学习中,反向传播是训练神经网络的一种常用优化算法。它通过计算损失函数对模型参数的梯度,从而使模型的参数朝着减小损失函数的方向更新,从而提高模型的性能。具体地说,train_loss.backward()会自动计算train_loss关于模型的各个可训练参数(通常是网络的权重和偏置)的梯度,并将梯度信息保存在各个参数的.grad属性中。这些梯度信息将用于优化器进行参数更新。需要注意的是,在执行反向传播之前,需要先进行前向传播,即将输入数据通过神经网络计算出预测结果,然后将预测结果与真实标签进行比较得到损失函数的值。然后才能调用backward()函数执行反向传播,计算出各个参数的梯度。反向传播是深度学习训练中的关键步骤,通过自动计算梯度,可以大大简化优化算法的实现,同时也使得训练过程更加高效和稳定。
opt.step() # opt.step() 是 PyTorch 中优化器的方法,用于执行参数更新步骤。在深度学习中,优化器负责根据计算得到的梯度来更新模型的参数,以最小化损失函数并提升模型性能。具体而言,opt.step() 会根据优化器中定义的更新策略,将参数的梯度应用到对应的参数上,从而更新模型的权重和偏置。这个过程通常发生在每个训练步骤(或者每个批次)结束后。
# 通常的训练流程如下:1、计算模型的输出:使用前向传播计算模型的输出。2、计算损失:根据输出和真实标签计算损失函数的值。3、计算梯度:使用反向传播计算损失函数相对于模型参数的梯度。4、参数更新:调用优化器的 opt.step() 方法,根据梯度更新模型参数。5、清零梯度:调用 opt.zero_grad() 方法,将之前计算的梯度清零,为下一次梯度计算做准备。 这个循环会在训练过程中不断重复,直到达到设定的训练轮数或者其他停止条件。通过不断地优化模型参数,训练过程逐渐使模型收敛于最优解,并且在验证集或测试集上取得较好的性能。
if i % 1 == 0: # 在这段代码中,if i % 1 == 0: 表示每训练一次(每处理一个批次),都会执行一次对应的代码块。这里使用了 % 运算符,它表示取模运算,即取得 i 除以 1 的余数。因为 i 是一个整数,所以 i % 1 的结果永远是 0,所以这个条件始终为真,相当于在每次迭代中都会执行对应的代码。
# 通常情况下,我们会在训练过程中设置一个较大的批次数,例如 100 或 1000,而不是 1。这样做是为了加快训练过程,因为每处理一个批次都需要进行前向传播、损失计算、反向传播和参数更新,如果批次数较小,会导致训练过程非常缓慢。然而,有时候我们需要在训练过程中观察每一个批次的训练情况,或者进行一些特定的调试操作,这时候就可以将批次数设置为 1,以便每次迭代都可以观察到对应的输出和损失。在实际训练中,为了加快训练速度,我们会将批次数设置为较大的值。
print(
f'{epoch}-{i}-train_loss===>>{train_loss.item()}') # {epoch}: 这里是代表当前训练的轮数(epoch)的变量,它是一个整数,表示模型训练的当前迭代次数。{i}: 这里是代表当前处理的批次的索引(index)的变量,它也是一个整数,表示当前处理的是模型训练中的第几个批次数据。{train_loss.item()}: 这里是代表当前批次的训练损失(loss)的变量,它通过 train_loss.item() 得到的是一个浮点数,表示当前批次的训练损失值。
_image = image[
0]
# 在这里,image 是一个张量,它包含了一个批次的图像数据。通过 image[0],我们取出了这个批次中的第一个图像(通常是一个单独的图像),并将它赋值给 _image 变量。这样做可能是为了在后续的代码中单独处理这个图像,例如进行可视化、保存图像或者其他处理操作。在训练过程中,通常会对每个批次的图像进行相同的处理,但有时也需要单独处理某个图像,因此将它提取出来并赋值给 _image 变量可以更方便地对该图像进行操作。
_segment_image = torch.unsqueeze(segment_image[0],
0) * 255 # 首先,segment_image 是一个张量(tensor),包含了一个批次的分割图像数据。通过 segment_image[0],我们取出了这个批次中的第一个分割图像(通常是一个单独的分割图像) 接下来,使用 torch.unsqueeze(segment_image[0], 0) 将这个分割图像的维度从 [H, W] 扩展为 [1, H, W]。这样做的目的是为了与 _image 的维度保持一致,因为 _image 是一个单独的图像,其维度是 [C, H, W],其中 C 表示通道数。最后,将 _segment_image 的值乘以 255,这可能是为了将像素值转换为可视化所需的范围。通常情况下,分割图像的像素值是类别索引,取值范围是 [0, num_classes-1],其中 num_classes 表示类别的数量。通过乘以 255,可以将像素值映射到 [0, 255] 的范围,方便可视化显示。综上所述,这段代码的目的是将一个批次中的第一个分割图像提取出来,并将其维度扩展为 [1, H, W],然后将像素值映射到 [0, 255] 的范围,以便后续进行可视化操作。
_out_image = torch.argmax(out_image[0], dim=0).unsqueeze(
0) * 255 # 首先,out_image 是一个张量(tensor),包含了一个批次的模型输出图像数据。通过 out_image[0],我们取出了这个批次中的第一个模型输出图像(通常是一个单独的图像)。综上所述,这段代码的目的是将一个批次中的第一个模型输出图像提取出来,并将其维度扩展为 [1, H, W],然后将类别索引映射为像素值,以便后续进行可视化操作。
img = torch.stack([_segment_image, _out_image],
dim=0)
# 在这段代码中,img 是一个张量(tensor),它通过 torch.stack 函数对 _segment_image 和 _out_image 进行堆叠(叠加)得到。_segment_image 和 _out_image 都是单通道的图像张量,其维度是 [1, H, W],其中 H 是图像的高度,W 是图像的宽度。通过 torch.stack([_segment_image, _out_image], dim=0),将 _segment_image 和 _out_image 沿着维度 dim=0 进行堆叠,得到一个新的张量 img。这样做之后,img 的维度变为 [2, 1, H, W],其中 2 表示有两个通道,第一个通道存储 _segment_image 的数据,第二个通道存储 _out_image 的数据。通过将这两个单通道图像叠加在一起,可以将它们同时可视化,以便对比模型输出和真实标签之间的差异。这在训练和验证过程中非常有用,可以帮助我们了解模型的训练情况和性能。
save_image(img,
f'{save_path}/{i}.png') # 在这段代码中,save_image 函数用于将张量 img 保存为图像文件。这个函数是来自 PyTorch 的 torchvision.utils 模块。img 是一个包含两个通道的张量,其中第一个通道存储 _segment_image 的数据,第二个通道存储 _out_image 的数据。每个通道都是单通道的图像张量,其维度为 [1, H, W],其中 H 是图像的高度,W 是图像的宽度。f'{save_path}/{i}.png' 是图像文件保存的路径和文件名。{save_path} 是之前定义的保存路径,{i} 是当前批次中的图像索引,.png 表示保存为 PNG 格式的图像文件。这样,每个训练批次都会将两张图像(_segment_image 和 _out_image)保存为一张叠加的图像,并以不同的文件名保存在指定的路径下,用于后续的观察和分析。这是一个可视化训练过程中输出和标签之间的重要步骤。
if epoch % 1 == 0: # 这段代码用于在每个完整的训练周期(epoch)结束后执行特定的操作。epoch 是一个整数变量,表示当前训练的周期数。if epoch % 1 == 0 的意思是,如果当前的训练周期 epoch 是1的倍数(也就是每个完整的周期),则执行下面的代码块。这样的条件通常是为了在特定的训练周期(例如每个完整的周期)进行一些额外的操作,比如记录训练过程中的损失、保存模型、进行验证等。在这个条件成立的情况下,会执行相应的代码块。
TrainLossrecord = train_loss.item() # 在这段代码中,TrainLossrecord 变量被赋值为 train_loss.item(),其中 train_loss 是一个损失函数的计算结果,item() 方法用于获取这个损失函数的标量值。通常,在训练过程中,我们会记录每个训练步骤(或每个小批次)的损失,并在每个周期结束后保存这些损失值。这样做有助于了解模型的训练过程,观察损失值的变化趋势,以及可能需要调整的训练超参数。
train_loss_list.append(
TrainLossrecord) # 在这段代码中,TrainLossrecord是当前训练步骤(iteration)的训练损失值,train_loss_list是一个用于存储训练损失值的列表。在每个训练步骤结束后,将当前的训练损失值添加到train_loss_list中,以便后续可以分析和可视化训练过程中的损失值变化。例如,如果训练过程一共有100个训练步骤,那么train_loss_list将包含100个训练损失值,分别对应每个训练步骤的损失。这样,我们就可以通过观察train_loss_list中的数值变化来了解模型在训练过程中损失的情况,以及模型是否在逐步收敛到较低的损失值。
if epoch > (
train_epoch / 2): # 只保留后面的训练模型,前期训练模型损失值大,没有必要保存,增加了CPU和硬盘之间的IO操作,理论上会降低训练速度//在这段代码中,条件epoch > (train_epoch/2)意味着当前的训练轮数(epoch)是否大于训练总轮数(train_epoch)的一半。这个条件可能是为了在训练过程中执行某些特定操作,例如学习率衰减、保存模型、或者执行其他操作。在训练过程的后半阶段,有时会采取一些策略来调整模型的训练参数,以更好地优化模型。这可能是因为在初始阶段模型可能较难收敛,而在后半阶段已经接近最优解,因此可以使用不同的优化策略。具体到代码中,你可以查看后续的代码部分,看看在这个条件成立时做了什么操作。
last_weight_path = os.path.join(weight_path,
"last.pt") # 在这段代码中,last_weight_path是一个字符串变量,用于表示模型训练过程中保存最新的权重文件的路径。os.path.join(weight_path, "last.pt")使用os.path.join()函数将weight_path和"last.pt"拼接在一起,生成最终的权重文件路径。weight_path是之前定义的模型权重保存路径,而"last.pt"是权重文件的文件名,".pt"可能表示该文件是一个PyTorch模型权重文件。通过这个last_weight_path路径,你可以在训练过程中持续保存模型的权重,以便在训练过程中发生意外或在训练结束后进行模型评估时使用。这样可以确保你在训练过程中得到的最新权重都被保存下来,避免数据丢失或覆盖。
torch.save(net.state_dict(),
last_weight_path) # 在这段代码中,torch.save()函数用于将模型的状态字典(state_dict)保存到文件中,以便在训练过程中保存最新的模型权重。net.state_dict()是一个Python字典,包含了模型的所有参数和对应的权重。通过调用torch.save(net.state_dict(), last_weight_path),将模型的状态字典保存到名为last_weight_path的文件中,这个文件是一个二进制文件,通常以.pt、.pth或其他自定义的扩展名来表示。这样做的好处是,你可以在训练过程中定期保存模型的权重,以防止训练过程中的意外中断导致模型的参数丢失。同时,还可以在训练结束后加载这些保存的权重,用于模型的评估、测试或推理。
if TrainLossrecord < min_loss: # 找出损失值最小的模型//在这段代码中,TrainLossrecord是当前训练的损失值,min_loss是之前保存的最小损失值。该条件判断语句的作用是检查当前训练的损失是否比之前保存的最小损失还要小。如果TrainLossrecord小于min_loss,则说明当前训练得到的模型在验证集上的损失比之前保存的最小损失更低,意味着模型性能有所提升。因此,在这种情况下,代码会执行相应的操作,可能包括保存当前模型权重、更新最小损失值等。这样做的目的是记录在训练过程中获得的最佳模型,并在训练结束后使用该模型进行测试或部署。
min_loss = TrainLossrecord # 正是如您所猜测的那样。在这段代码中,min_loss被更新为当前训练得到的损失值 TrainLossrecord。这样做是为了在训练过程中记录并保存获得的最小损失值,以便在后续的训练迭代中进行比较,并在得到更小的损失时更新模型的权重。通过持续地更新min_loss,您可以确保最终保存的模型是在验证集上获得了最佳性能的模型。
min_loss_weight_path = os.path.join(weight_path,
"min_loss.pt") # 这行代码用于构建保存最小损失值对应模型权重的路径。min_loss_weight_path变量保存了存储最小损失模型权重的文件路径,该路径是在原始保存路径weight_path的基础上添加了文件名"min_loss.pt"。这样,在训练过程中,如果发现当前的训练损失TrainLossrecord比之前记录的最小损失值min_loss要小,就会保存当前的模型权重到这个新路径上,从而保留下损失最小的模型。
min_loss_round = epoch # 这行代码用于保存最小损失值对应的训练轮数。min_loss_round变量存储了当前训练阶段(epoch)的值,当发现当前的训练损失TrainLossrecord比之前记录的最小损失值min_loss要小时,将min_loss_round更新为当前训练轮数(epoch)。这样,我们就能够追踪损失最小时对应的训练轮数,以便在训练结束后能够知道最优模型是在哪个训练轮次获得的。
torch.save(net.state_dict(),
min_loss_weight_path) # 这行代码用于保存在训练过程中发现的最小损失对应的模型权重。min_loss_weight_path是一个字符串变量,表示保存最小损失模型权重的文件路径。net.state_dict()返回当前神经网络net的模型权重,torch.save()函数将这些权重保存到指定的文件路径min_loss_weight_path中。这样,在训练结束后,我们就能得到损失最小时对应的模型权重,以便在后续使用中使用这个最优模型。
else:
pass # 在这段代码中,使用else: pass语句表示如果未满足之前的条件(即if TrainLossrecord < min_loss),则什么都不做,直接跳过该代码块。这可以用来处理在训练过程中损失没有减小的情况,不需要进行任何特定的操作。
epoch += 1 # 这行代码是在训练过程中的每个epoch结束后将epoch数加1,以继续进行下一个epoch的训练。这样可以确保模型在整个训练过程中都会经过指定的epoch数进行优化和训练。
endtime = time.time() # endtime 是一个变量,用于记录训练结束的时间。在这行代码中,time.time() 函数被调用,用于获取当前时间的时间戳,然后将其赋值给 endtime 变量,从而记录训练的结束时间。
execution_time = round((endtime - starttime) / 60,
2) # `execution_time` 是一个变量,用于记录训练的执行时间,即训练的持续时间。在这行代码中,`(endtime - starttime)` 计算了训练的时间差(以秒为单位),然后除以 60 来转换为分钟,并用 `round()` 函数将结果保留两位小数,最终将计算结果赋值给 `execution_time` 变量。
tools.save_to_excel(train_loss_list,
weight_path) # tools.save_to_excel(train_loss_list, weight_path) 是一个函数调用,用于将训练损失列表 train_loss_list 中的数据保存到 Excel 文件中。该函数会调用 tools.py 文件中的 save_to_excel 函数,将训练损失数据保存到名为 train.xlsx 的 Excel 文件中,并保存在 weight_path 目录下。
tools.train_print(min_loss_weight_path, min_loss, min_loss_round,
execution_time) # tools.train_print(min_loss_weight_path, min_loss, min_loss_round, execution_time) 是一个函数调用,用于在控制台打印模型训练的相关信息。该函数会调用 tools.py 文件中的 train_print 函数,并将最小损失权重文件路径 min_loss_weight_path、最小损失值 min_loss、最小损失对应的训练轮数 min_loss_round 以及训练的执行时间 execution_time 作为参数传递给该函数。train_print 函数会在控制台打印出模型训练过程中的相关信息,例如最小损失的权重文件路径、最小损失的数值、对应的训练轮数以及模型训练的总执行时间。这些信息有助于了解模型的训练效果和性能。
tools.draw(train_epoch, train_loss_list,
weight_path) # tools.draw(train_epoch, train_loss_list, weight_path) 是一个函数调用,用于绘制模型训练过程中损失函数的变化曲线图。该函数会调用 tools.py 文件中的 draw 函数,并将训练的总轮数 train_epoch、每一轮训练对应的损失值列表 train_loss_list 以及保存图片的文件夹路径 weight_path 作为参数传递给该函数。draw 函数会根据训练过程中损失值的变化,生成一张损失函数曲线图,并将其保存在指定的文件夹路径中。这样可以直观地观察模型训练的效果,了解模型在每一轮训练中损失函数的变化情况,从而对模型的性能进行评估和调优。
最终训练的结果放在params/expx中,修改.pt后缀名为.pth方便之后使用。(这里的expx针对于自己电脑的训练次数来说,若是第一次训练为exp0)



















 1605
1605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









