






★★★ 本文源自AI Studio社区精品项目,【点击此处】查看更多精品内容 >>>
从头搭建无人车车道线检测paddle2.4版解决方案
1. 项目介绍
- AI Studio举办过无人车车道线检测挑战赛,在当时还没有PaddleSeg套件,很多解决方案都是从头手撸代码,也包括很优秀的冠军方案,不过由于比赛比较早,该方案的paddle版本为1.8.4
- 最近在学习车道线分割方面的知识,所以用Paddle2.4对该解决方案进行重构,以期能学习代码、掌握基本原理、深入了解框架
2. 数据介绍与可视化
-
本次使用无人车车道线复赛数据集:无人车车道线检测训练集-复赛
-
无人车车道线挑战赛开放了数万幅精细标的车道线数据。此数据采集于北京和上海两个不同的城市,几种不同的交通场景,包含了绝大多数的道路标识以及一些不常见的类别。在整个数据集中,大约标注了33个类别。特别的,所有的车道线标注都是在三维点云上完成的,然后投影到二维的图像上。所有图像分辨率为3384×1710,如下表所示:
| Image | Label |
| — | — |
| |
|  |
| -
与常规的单通道数据标签格式不同,比赛所用数据集的label为三通道彩色图,标签和色彩的关系如下图所示:
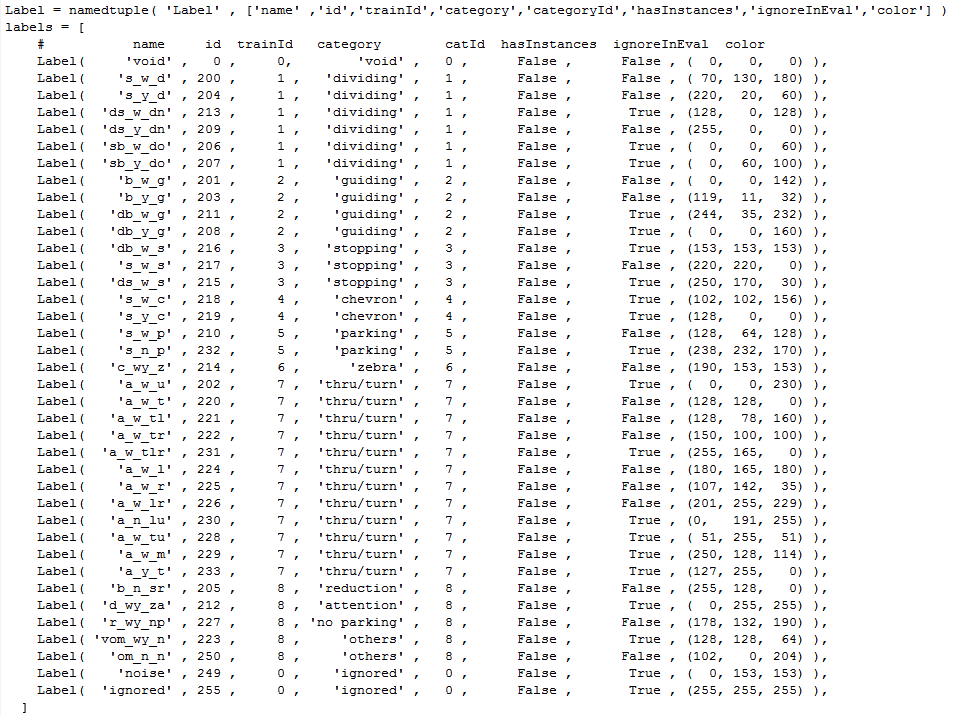
-
赛题中对数据的介绍如下:
1): name: 代表此类别的名字,其中,“s” 代表singe, “d” 代表double"w", 代表white, “y” 代表yellow,
2): id:代表的是标注时候的Id,也是现在发布数据中的class Id。
3): trainId: 代表的是建议的training Id。 在进行训练的过程中,数据的classId要是连续的整数。所以需要把label图像中的标注Id转化为trainId进行训练。
4): category: 代表的是不同的类别的具体含义;
5): catId: 代表的不同的不同的类别的Id,在这里我们的training Id 与 catId相同;
6): hasInstances: 代表这个类别是不是示例级别,这个在此task中并无实际意义。主要是与cityscape的mapping format保持一致;
7): ignoreInEval: 代表这个类别在评估时,是否忽略。请注意,不是所有的类别都在最终的结果中进行评估。原因是,有一些类别在此数据集中并不存在;
8): color: 代表不同的class对应的color map;
3. 标签处理
- 在训练过程中,需要将标签图转为连续的单通道数值图,同时在Encode的过程中需要考虑到不是所有类别都参与训练,而trainId是比赛主办方建议的训练类别,所以可以根据上述的标签对应表中的trainId和color进行Encode
# 解压数据集, 数据集较大, 仅以Road2为例子训练
!unzip -qo data/data3624/ColorImage_road02.zip -d work/ImageData/
!unzip -qo data/data3624/Gray_Label_New.zip -d work/
import os
import cv2
import numpy as np
import pandas as pd
import time
import shutil
from sklearn.utils import shuffle
# 编码标签, 将三通道的真值转为训练所用的单通道图
def encode_labels(color_mask):
encode_mask = np.zeros((color_mask.shape[0], color_mask.shape[1]), dtype='int32')
# 0
encode_mask[color_mask == 0] = 0
encode_mask[color_mask == 249] = 0
encode_mask[color_mask == 255] = 0
# 1
encode_mask[color_mask == 200] = 1
encode_mask[color_mask == 204] = 1
encode_mask[color_mask == 213] = 0
encode_mask[color_mask == 209] = 1
encode_mask[color_mask == 206] = 0
encode_mask[color_mask == 207] = 0
# 2
encode_mask[color_mask == 201] = 2
encode_mask[color_mask == 203] = 2
encode_mask[color_mask == 211] = 0
encode_mask[color_mask == 208] = 0
# 3
encode_mask[color_mask == 216] = 0
encode_mask[color_mask == 217] = 3
encode_mask[color_mask == 215] = 0
# 4 In the test, it will be ignored
encode_mask[color_mask == 218] = 0
encode_mask[color_mask == 219] = 0
# 4
encode_mask[color_mask == 210] = 4
encode_mask[color_mask == 232] = 0
# 5
encode_mask[color_mask == 214] = 5
# 6
encode_mask[color_mask == 202] = 0
encode_mask[color_mask == 220] = 6
encode_mask[color_mask == 221] = 6
encode_mask[color_mask == 222] = 6
encode_mask[color_mask == 231] = 0
encode_mask[color_mask == 224] = 6
encode_mask[color_mask == 225] = 6
encode_mask[color_mask == 226] = 6
encode_mask[color_mask == 230] = 0
encode_mask[color_mask == 228] = 0
encode_mask[color_mask == 229] = 0
encode_mask[color_mask == 233] = 0
# 7
encode_mask[color_mask == 205] = 7
encode_mask[color_mask == 212] = 0
encode_mask[color_mask == 227] = 7
encode_mask[color_mask == 223] = 0
encode_mask[color_mask == 250] = 7
return encode_mask
# 解码, 将预测的单通道结果转为与训练集一致的三通道图
def decode_color_labels(labels):
decode_mask = np.zeros((3, labels.shape[0], labels.shape[1]), dtype='uint8')
# 0
decode_mask[0][labels == 0] = 0
decode_mask[1][labels == 0] = 0
decode_mask[2][labels == 0] = 0
# 1
decode_mask[0][labels == 1] = 70
decode_mask[1][labels == 1] = 130
decode_mask[2][labels == 1] = 180
# 2
decode_mask[0][labels == 2] = 0
decode_mask[1][labels == 2] = 0
decode_mask[2][labels == 2] = 142
# 3
decode_mask[0][labels == 3] = 153
decode_mask[1][labels == 3] = 153
decode_mask[2][labels == 3] = 153
# 4
decode_mask[0][labels == 4] = 128
decode_mask[1][labels == 4] = 64
decode_mask[2][labels == 4] = 128
# 5
decode_mask[0][labels == 5] = 190
decode_mask[1][labels == 5] = 153
decode_mask[2][labels == 5] = 153
# 6
decode_mask[0][labels == 6] = 0
decode_mask[1][labels == 6] = 0
decode_mask[2][labels == 6] = 230
# 7
decode_mask[0][labels == 7] = 255
decode_mask[1][labels == 7] = 128
decode_mask[2][labels == 7] = 0
return decode_mask
# 生成训练所用的路径表格
label_list = []
image_list = []
image_dir = 'work/ImageData'
label_dir = 'work/Gray_Label'
for s1 in os.listdir(image_dir):
image_sub_dir1 = os.path.join(image_dir, s1, 'ColorImage')
label_sub_dir1 = os.path.join(label_dir, 'Label_' + str.lower(s1).split('_')[1], 'Label')
# print(image_sub_dir1, label_sub_dir1)
for s2 in os.listdir(image_sub_dir1):
image_sub_dir2 = os.path.join(image_sub_dir1, s2)
label_sub_dir2 = os.path.join(label_sub_dir1, s2)
# print(image_sub_dir2, label_sub_dir2)
for s3 in os.listdir(image_sub_dir2):
image_sub_dir3 = os.path.join(image_sub_dir2, s3)
label_sub_dir3 = os.path.join(label_sub_dir2, s3)
# print(image_sub_dir3, label_sub_dir3)
for s4 in os.listdir(image_sub_dir3):
s44 = s4.replace('.jpg','_bin.png')
image_sub_dir4 = os.path.join(image_sub_dir3, s4)
label_sub_dir4 = os.path.join(label_sub_dir3, s44)
if not os.path.exists(image_sub_dir4):
print(image_sub_dir4)
if not os.path.exists(label_sub_dir4):
print(label_sub_dir4)
# print(image_sub_dir4, label_sub_dir4)
image_list.append(image_sub_dir4)
label_list.append(label_sub_dir4)
print(len(image_list), len(label_list))
save = pd.DataFrame({'image':image_list, 'label':label_list})
save_shuffle = shuffle(save)
save_shuffle.to_csv('/home/aistudio/work/train.csv', index=False)
10972 10972
4. 图像分析与处理
-
图像分辨率为3384×1710,直接训练会爆显存。这些数据有一个共同的特点:图片的上三分之一部分都是天空,是没有车道线存在的。知道了这点后,就可以设置剪裁图像上方的像素,简单地将天空剪裁掉,本项目设置剪裁690个像素
-
裁剪后,进行数据增强,本项目仅写了随机剪裁,更多的可以参考PaddleSeg中的增强方式,这里仅抛砖引玉。数据增强后选择缩放至1024×512的分辨率进行训练,也是考虑到尽可能达到相同的比例关系
-
注意: 当缩放Mask的时候,一定要采用最临近插值,如果使用其他方式,label就会发生变化,这一点一定要非常注意
# 随机剪裁
def random_crop(image, label):
random_seed = np.random.randint(0, 10)
if random_seed < 5:
return image, label
else:
width, height = image.shape[1], image.shape[0]
new_width = int(float(np.random.randint(88, 99)) / 100.0 * width)
new_height = int(float(np.random.randint(88, 99)) / 100.0 * height)
offset_w = np.random.randint(0, width - new_width - 1)
offset_h = np.random.randint(0, height - new_height - 1)
new_image = image[offset_h : offset_h + new_height, offset_w : offset_w + new_width]
new_label = label[offset_h: offset_h + new_height, offset_w: offset_w + new_width]
return new_image, new_label
# 剪裁图像上方的像素, 并将其缩放
def crop_resize_data(image, label=None, image_size=[1024, 512], offset=690):
roi_image = image[offset:, :]
if label is not None:
roi_label = label[offset:, :]
crop_image, crop_label = random_crop(roi_image, roi_label)
train_image = cv2.resize(roi_image, (image_size[0], image_size[1]), interpolation=cv2.INTER_LINEAR)
train_label = cv2.resize(roi_label, (image_size[0], image_size[1]), interpolation=cv2.INTER_NEAREST)
return train_image, train_label
else:
train_image = cv2.resize(roi_image, (image_size[0], image_size[1]), interpolation=cv2.INTER_LINEAR)
return train_image
# 对验证的数据进行剪裁与缩放
def crop_val_resize_data(image, label=None, image_size=[1024, 512], offset=690):
roi_image = image[offset:, :]
roi_label = label[offset:, :]
val_image = cv2.resize(roi_image, (image_size[0], image_size[1]), interpolation=cv2.INTER_LINEAR)
val_label = cv2.resize(roi_label, (image_size[0], image_size[1]), interpolation=cv2.INTER_NEAREST)
return val_image, val_label
# 将预测的图像转为没裁剪天空时图像的预测结果
def expand_resize_color_data(prediction=None, submission_size=[3384, 1710], offset=690):
color_pred_mask = decode_color_labels(prediction)
color_pred_mask = np.transpose(color_pred_mask, (1, 2, 0))
color_expand_mask = cv2.resize(color_pred_mask, (submission_size[0], submission_size[1] - offset), interpolation=cv2.INTER_NEAREST)
color_submission_mask = np.zeros((submission_size[1], submission_size[0], 3), dtype='uint8')
color_submission_mask[offset:, :, :] = color_expand_mask
return color_submission_mask
5. 数据加载
- 原冠军方案版本较老,是自己搭的数据集与加载器。本项目使用Paddle2.4已有的api来实现数据集加载部分
import paddle
from paddle.io import Dataset, DataLoader
# 数据集
class BasicDataset(Dataset):
def __init__(self, train_list, image_size=[1024, 512], crop_offset=690):
super(BasicDataset, self).__init__()
self.train_list = train_list
self.image_dir = np.array(self.train_list['image'])
self.label_dir = np.array(self.train_list['label'])
self.image_size = image_size
self.crop_offset = crop_offset
def __getitem__(self, index):
ori_image = cv2.imread(self.image_dir[index])
ori_mask = cv2.imread(self.label_dir[index], cv2.IMREAD_GRAYSCALE)
# 剪裁天空部分, 并缩放图像
train_img, train_mask = crop_resize_data(ori_image, ori_mask, self.image_size, self.crop_offset)
# 将三通道的Label图转为单通道的
train_mask = encode_labels(train_mask)
out_image = np.array(train_img)
out_mask = np.array(train_mask)
out_image = out_image[:, :, ::-1].transpose(2, 0, 1).astype(np.float32) / 255.0 # BGR转RGB 转换shape
out_mask = out_mask.astype(np.int64)
return {'Image': out_image, 'Label': out_mask}
def __len__(self):
return len(self.train_list)
def get_train_loder(dataset, batch_size, num_workers=4, is_shuffle=True):
train_loader = DataLoader(dataset,
batch_size=batch_size,
num_workers=num_workers,
drop_last=True,
shuffle=is_shuffle,
use_shared_memory=True)
return train_loader
6. 模型组网
- 冠军方案所用的模型为U-Net,这里保持一致,依然使用U-Net模型
- 该比赛距今已过了4年,期间涌现了很多优秀的语义分割模型,大家可以自行替换
import paddle.nn as nn
import paddle.nn.functional as F
def SyncBatchNorm(*args, **kwargs):
"""In cpu environment nn.SyncBatchNorm does not have kernel so use nn.BatchNorm2D instead"""
if paddle.get_device() == 'cpu' or os.environ.get('PADDLESEG_EXPORT_STAGE'):
return nn.BatchNorm2D(*args, **kwargs)
elif paddle.distributed.ParallelEnv().nranks == 1:
return nn.BatchNorm2D(*args, **kwargs)
else:
return nn.SyncBatchNorm(*args, **kwargs)
class ConvBNReLU(nn.Layer):
def __init__(self,
in_channels,
out_channels,
kernel_size,
padding='same',
**kwargs):
super().__init__()
self._conv = nn.Conv2D(
in_channels, out_channels, kernel_size, padding=padding, **kwargs)
if 'data_format' in kwargs:
data_format = kwargs['data_format']
else:
data_format = 'NCHW'
self._batch_norm = SyncBatchNorm(out_channels, data_format=data_format)
self._relu = nn.ReLU()
def forward(self, x):
x = self._conv(x)
x = self._batch_norm(x)
x = self._relu(x)
return x
class UNet(nn.Layer):
"""
Args:
num_classes (int): The unique number of target classes.
align_corners (bool): An argument of F.interpolate. It should be set to False when the output size of feature
is even, e.g. 1024x512, otherwise it is True, e.g. 769x769. Default: False.
use_deconv (bool, optional): A bool value indicates whether using deconvolution in upsampling.
If False, use resize_bilinear. Default: False.
"""
def __init__(self,
num_classes,
input_channel=3,
align_corners=False,
use_deconv=False):
super().__init__()
self.encode = Encoder(input_channel)
self.decode = Decoder(align_corners, use_deconv=use_deconv)
self.cls = self.conv = nn.Conv2D(
in_channels=64,
out_channels=num_classes,
kernel_size=3,
stride=1,
padding=1)
def forward(self, x):
logit_list = []
x, short_cuts = self.encode(x)
x = self.decode(x, short_cuts)
logit = self.cls(x)
return logit
class Encoder(nn.Layer):
def __init__(self, input_channel=3):
super().__init__()
self.double_conv = nn.Sequential(
ConvBNReLU(input_channel, 64, 3),
ConvBNReLU(64, 64, 3))
down_channels = [[64, 128], [128, 256], [256, 512], [512, 512]]
self.down_sample_list = nn.LayerList([
self.down_sampling(channel[0], channel[1])
for channel in down_channels
])
def down_sampling(self, in_channels, out_channels):
modules = []
modules.append(nn.MaxPool2D(kernel_size=2, stride=2))
modules.append(ConvBNReLU(in_channels, out_channels, 3))
modules.append(ConvBNReLU(out_channels, out_channels, 3))
return nn.Sequential(*modules)
def forward(self, x):
short_cuts = []
x = self.double_conv(x)
for down_sample in self.down_sample_list:
short_cuts.append(x)
x = down_sample(x)
return x, short_cuts
class Decoder(nn.Layer):
def __init__(self, align_corners, use_deconv=False):
super().__init__()
up_channels = [[512, 256], [256, 128], [128, 64], [64, 64]]
self.up_sample_list = nn.LayerList([
UpSampling(channel[0], channel[1], align_corners, use_deconv)
for channel in up_channels
])
def forward(self, x, short_cuts):
for i in range(len(short_cuts)):
x = self.up_sample_list[i](x, short_cuts[-(i + 1)])
return x
class UpSampling(nn.Layer):
def __init__(self,
in_channels,
out_channels,
align_corners,
use_deconv=False):
super().__init__()
self.align_corners = align_corners
self.use_deconv = use_deconv
if self.use_deconv:
self.deconv = nn.Conv2DTranspose(
in_channels,
out_channels // 2,
kernel_size=2,
stride=2,
padding=0)
in_channels = in_channels + out_channels // 2
else:
in_channels *= 2
self.double_conv = nn.Sequential(
ConvBNReLU(in_channels, out_channels, 3),
ConvBNReLU(out_channels, out_channels, 3))
def forward(self, x, short_cut):
if self.use_deconv:
x = self.deconv(x)
else:
x = F.interpolate(
x,
paddle.shape(short_cut)[2:],
mode='bilinear',
align_corners=self.align_corners)
x = paddle.concat([x, short_cut], axis=1)
x = self.double_conv(x)
return x
7. 评价指标与损失函数
- 一个方案的优劣,最终要通过特定的指标来进行评价,本次比赛采用的就是比较通用的mIou的评价方式,所以在训练过程中同样以相同的指标对预测结果评价
- 同时,损失函数也要尽可能贴近,所以损失函数最终选择了Binary CrossEntropy和DICE相结合,以求达到更加鲁棒的结果
# 计算混淆矩阵
def _fast_hist(label_true, label_pred, n_class):
# mask在和label_true相对应的索引的位置上填入true或者false
# label_true[mask]会把mask中索引为true的元素输出
mask = (label_true >= 0) & (label_true < n_class)
# np.bincount()会给出索引对应的元素个数
# hist是一个混淆矩阵
# hist是一个二维数组,可以写成hist[label_true][label_pred]的形式
# 最后得到的这个数组的意义就是行下标表示的类别预测成列下标类别的数量
# 比如hist[0][1]就表示类别为1的像素点被预测成类别为0的数量
# 对角线上就是预测正确的像素点个数
# n_class * label_true[mask].astype(int) + label_pred[mask]计算得到的是二维数组元素
# 变成一位数组元素的时候的地址取值(每个元素大小为1),返回的是一个numpy的list,然后
# np.bincount就可以计算各中取值的个数
hist = np.bincount(
n_class * label_true[mask].astype(int) +
label_pred[mask], minlength=n_class ** 2).reshape(n_class, n_class)
return hist
# label_trues 正确的标签值
# label_preds 模型输出的标签值
# n_class 数据集中的分类数
def label_accuracy_score(label_trues, label_preds, n_class):
"""Returns accuracy score evaluation result.
- overall accuracy
- mean accuracy
- mean IU
- fwavacc
"""
hist = np.zeros((n_class, n_class))
# 一个batch里面可能有多个数据
# 通过迭代器将一个个数据进行计算
for lt, lp in zip(label_trues, label_preds):
hist += _fast_hist(lt.flatten(), lp.flatten(), n_class)
# np.diag(a)假如a是一个二维矩阵,那么会输出矩阵的对角线元素
# np.sum()可以计算出所有元素的和。如果axis=1,则表示按行相加
# acc是准确率 = 预测正确的像素点个数/总的像素点个数
# acc_cls是预测的每一类别的准确率(比如第0行是预测的类别为0的准确率),然后求平均
# iu是召回率Recall,公式上面给出了
# mean_iu就是对iu求了一个平均
# freq是每一类被预测到的频率
# fwavacc是频率乘以召回率
acc = np.diag(hist).sum() / hist.sum()
with np.errstate(divide='ignore', invalid='ignore'):
acc_cls = np.diag(hist) / hist.sum(axis=1)
acc_cls = np.nanmean(acc_cls)
with np.errstate(divide='ignore', invalid='ignore'):
iu = np.diag(hist) / (
hist.sum(axis=1) + hist.sum(axis=0) - np.diag(hist)
)
mean_iu = np.nanmean(iu)
freq = hist.sum(axis=1) / hist.sum()
fwavacc = (freq[freq > 0] * iu[freq > 0]).sum()
return acc, acc_cls, mean_iu, fwavacc
class DiceLoss(nn.Layer):
def __init__(self, ignore_index=255, smooth=0.):
super(DiceLoss, self).__init__()
self.ignore_index = ignore_index
self.eps = 1e-5
self.smooth = smooth
def forward(self, logits, labels):
labels = paddle.cast(labels, dtype='int32')
labels_one_hot = F.one_hot(labels, num_classes=logits.shape[1])
labels_one_hot = paddle.transpose(labels_one_hot, [0, 3, 1, 2])
labels_one_hot = paddle.cast(labels_one_hot, dtype='float32')
logits = F.softmax(logits, axis=1)
mask = (paddle.unsqueeze(labels, 1) != self.ignore_index)
logits = logits * mask
labels_one_hot = labels_one_hot * mask
dims = (0, ) + tuple(range(2, labels.ndimension() + 1))
intersection = paddle.sum(logits * labels_one_hot, dims)
cardinality = paddle.sum(logits + labels_one_hot, dims)
dice_loss = ((2. * intersection + self.smooth) /
(cardinality + self.eps + self.smooth)).mean()
return 1 - dice_loss
8. 模型训练
- 数据部分、模型组网、损失函数、评价指标都已经设计好,解下来就是将其组合在一起,进行模型的训练了
- 训练结果的权重保存在
work/model_weight文件夹下
# 训练所需要的配置参数
IMG_SIZE =[512, 1024]
SUBMISSION_SIZE = [3384, 1710]
num_classes = 8
batch_size = 4
base_lr = 0.001
save_freq = 1 # 每隔多少个epoch保存一次
use_pretrained = False
num_epochs = 5
crop_offset = 690
data_dir = r'work/train.csv'
model_dir = r'work/model_weight'
data_list = pd.read_csv(data_dir)
train_list = data_list.iloc[:-972, :] # 训练集数据列表
val_list = data_list.iloc[-972:, :] # 测试集数据列表
# 创建保存模型的文件夹
if not os.path.exists(model_dir):
os.mkdir(model_dir)
# 定义训练数据的加载器
train_dataset = BasicDataset(train_list, image_size=IMG_SIZE, crop_offset=crop_offset)
train_dataloader = get_train_loder(dataset=train_dataset, batch_size=batch_size, num_workers=0)
# 定义验证数据的加载器
val_dataset = BasicDataset(val_list, image_size=IMG_SIZE)
val_dataloader = get_train_loder(dataset=val_dataset, batch_size=1, num_workers=0, is_shuffle=False)
# 定义模型
model = UNet(num_classes)
# 定义损失函数
cross_entropy = nn.CrossEntropyLoss(reduction='mean', ignore_index=255, axis=1) # 交叉熵损失
dice_loss = DiceLoss() # Dice损失
# 定义优化器
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=base_lr, T_max=num_epochs*len(train_list), verbose=True)
optimizer = paddle.optimizer.Momentum(parameters=model.parameters(),
learning_rate=scheduler,
momentum=0.9,
weight_decay=1e-5)
W0118 00:14:09.230144 29212 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0118 00:14:09.236057 29212 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
Epoch 0: CosineAnnealingDecay set learning rate to 0.001.
class AverageMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.total = 0
self.avg = 0
self.cnt = 0
def update(self, val, n=1):
self.cnt += n
self.total += val * n
self.avg = self.total / self.cnt
# 训练代码
def train(dataloader, model, cross_entropy, dice_loss, optimizer, total_batch):
model.train()
train_loss_list = []
train_acc_list = []
train_iou_list = []
train_loss_meter = AverageMeter()
for batch_id, traindata in enumerate(dataloader):
optimizer.clear_grad()
image = traindata["Image"]
label = traindata["Label"]
pred = model(image)
loss = 0
crossloss = cross_entropy(pred, label)
diceloss = dice_loss(pred, label)
loss = crossloss + diceloss
loss.backward()
optimizer.step()
lr = optimizer.get_lr()
with paddle.no_grad():
label_pred = np.argmax(pred.numpy(), 1)
label_true = label.numpy()
acc, acc_cls, mean_iu, fwavacc = label_accuracy_score(label_true, label_pred, n_class=num_classes)
n = image.shape[0]
train_loss_meter.update(loss.numpy()[0], n)
print(f"Batch[{batch_id:03d}/{total_batch:03d}], " +
f"learning rate: {lr:4f}," +
f"Average Loss: {train_loss_meter.avg:4f}, " +
f"Average Acc: {acc:4f}, " +
f"Mean_iou: {mean_iu:4f}")
train_loss_list.append(train_loss_meter.avg)
train_acc_list.append(acc)
train_iou_list.append(mean_iu)
return np.mean(train_loss_list), np.mean(train_acc_list), np.mean(train_iou_list)
# 验证代码
def val(dataloader, model):
model.eval()
val_acc_list = []
val_iou_list = []
for batch_id, data in enumerate(dataloader):
image = data["Image"]
label = data["Label"]
pred = model(image)
with paddle.no_grad():
label_pred = np.argmax(pred.numpy(), 1)
label_true = label.numpy()
acc, acc_cls, mean_iu, fwavacc = label_accuracy_score(label_true, label_pred, n_class=13)
val_acc_list.append(acc)
val_iou_list.append(mean_iu)
return np.mean(val_acc_list), np.mean(val_iou_list)
star = 0
total_batch = int(len(train_dataset) / batch_size)
for epoch in range(star, num_epochs+1):
train_loss, train_acc, train_mean_iou = train(train_dataloader, model, cross_entropy, dice_loss, optimizer, total_batch)
print(f"----- Epoch[{epoch}/{num_epochs}] Train Loss: {train_loss:.4f} Train Acc: {train_acc:.4f} Train Mean_iou: {train_mean_iou:.4f}")
val_acc, val_mean_iou = val(val_dataloader, model)
print(f"----- Epoch[{epoch}/{num_epochs}] Val Acc: {val_acc:.4f} Mean iou: {val_mean_iou:.4f}")
if epoch % save_freq == 0 or epoch == num_epochs:
model_path = '{}/{}_epoch{}'.format(model_dir, 'unet_base', epoch)
paddle.save(optimizer.state_dict(), '{}/{}_epoch{}'.format(model_dir, 'unet_base', epoch)+'.pdopt')
paddle.save(model.state_dict(), '{}/{}_epoch{}'.format(model_dir, 'unet_base', epoch)+'.pdparams')
print(f'----- Save model: {model_path}.pdparams')
print(f'----- Save optimizer: {model_path}.pdopt')















 2218
2218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









