






全称Compute Express Link。
CXL是协议的总称,实际上是由3个子协议组成,分别是CXL.io、CXL.cache、CXL.mem。这些协议被动态的复用在一起之后,通过标准 PCIe 5.0 的物理层以 32 GT/s 的速度进行传输。
CXL.io 子协议实际是具有某些增强功能的 PCIe 5.0 协议,主要用于初始化、链接、设备识别和枚举以及寄存器访问,它为 I/O 设备提供了非一致性的加载/存储接口。
CXL.cache是访问缓存的,定义了处理器与设备之间的交互,允许连接的 CXL 设备使用请求和响应方法,以极低的延迟高效地缓存处理器内存。
CXL.mem是访问内存的,使用加载和存储命令为处理器提供了对设备附加存储器的访问,其中处理器作为主设备,CXL 设备作为从设备,能够支持易失性和持久性的存储器架构
CXL 是一种动态多协议技术,为加速器访问系统提供了低延迟、高带宽的路径
直接连接的CPU链路,不能位于PCIe交换机后面
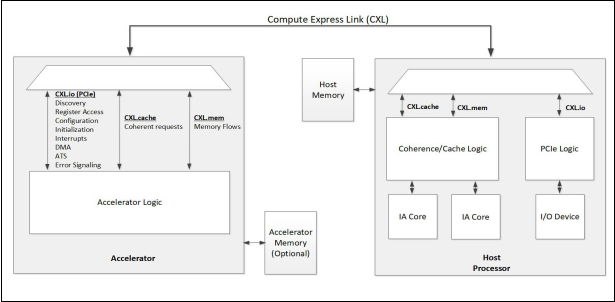
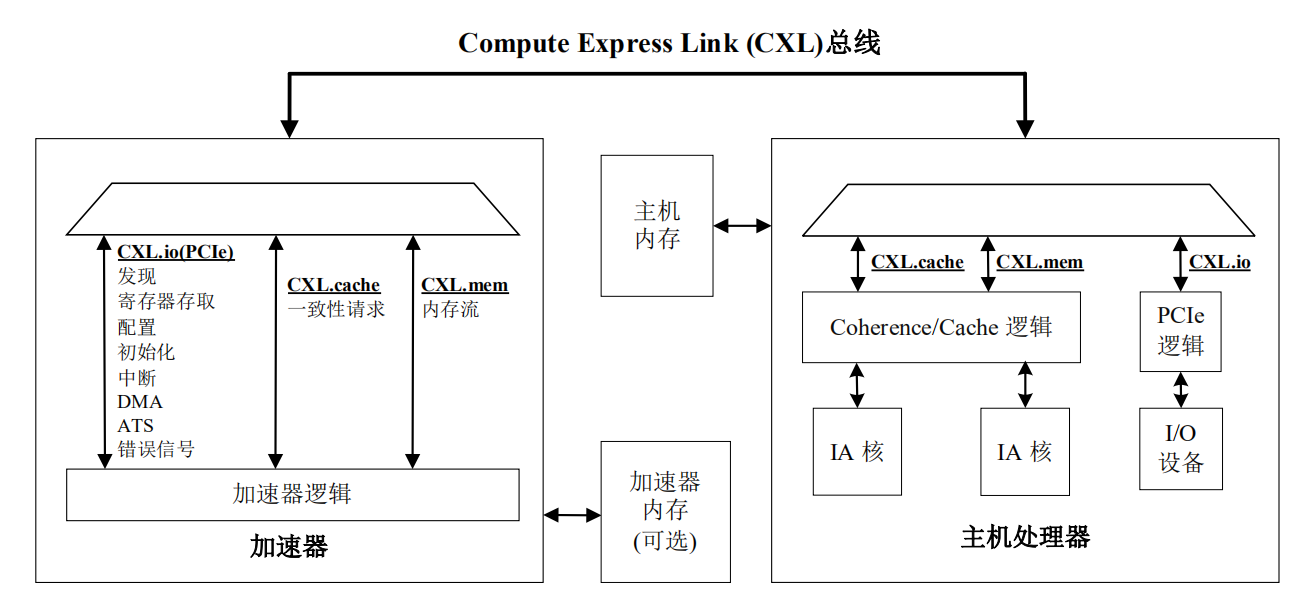
CXL连接到处理器的加速器的概念图
CXL1.0
CXL2.0
支持CXL 1.1规范之外的其他使用模式,同时完全向后兼容CXL 1.1(和CXL 1.0)规范
支持受管热插拔、安全性增强、持久内存支持、内存错误报告和遥测
实现了对扇出的单级交换支持
实现跨多个虚拟层级共享设备的能力,包括对内存设备的多域支持。
支持这些资源(内存或加速器)从一个域离线进入另一个域,从而允许资源根据其资源需求在不同的虚拟层次结构中进行时间复用
CXL3.0
兼容CXL 2.0、CXL 1.1、CXL 1.0规范
通过PAM-4信令,最大数据速率翻倍至64.0 GT/s,利用PCIe基本规范PHY及其CRC和FEC,带宽翻倍
提供可选的Flit配置以实现低延迟
支持多级交换,最多支持4K端口,使CXL能够发展为一个扩展到机架和机架级别的结构,包括非树拓扑。
设备能够使用UIO(除了之前存在的MMIO内存之外)对HDM内存执行直接的点对点访问,从而实现规模化性能
探听过滤器支持可在Type 2和Type 3设备中实现,以使用CXL.mem中引入的反向无效通道实现直接对等访问
跨多个虚拟层次的共享内存支持可用于跨多个虚拟层次的协作处理
CXL协议与PCIe CEM外形(4.0及更高版本)、与eds ff SSF-TA-1009(2.0版及更高版本)相关的所有外形以及支持PCIe的其他外形兼容。
FlexBus
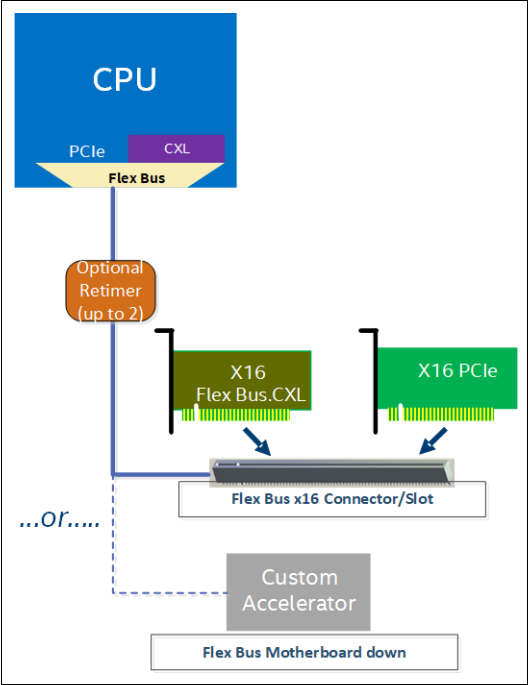
CPU Flex总线端口示例
Flex总线端口允许设计人员在通过高带宽、非封装链路提供本地PCIe协议或CXL之间进行选择;
该选择在引导期间通过自动协商进行,并取决于插入插槽的设备。
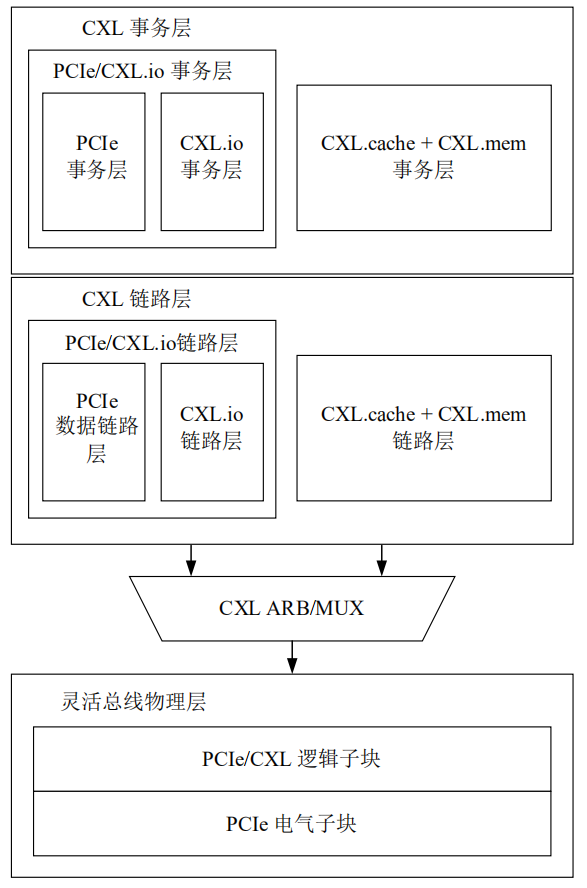
CXL.io走的是PCIE协议的通路,但是CXL.cache和CXL.mem走的是自己单独的事务层与链路层。
HOST CPU,它可能同时工作在CXL模式下或者PCIE模式下
CXL ARB/MUX 是一种仲裁或多路选择器,上面连接的是CXL和PCIE的链路层,它是用来选择把他们哪个链路层的数据给到物理层。
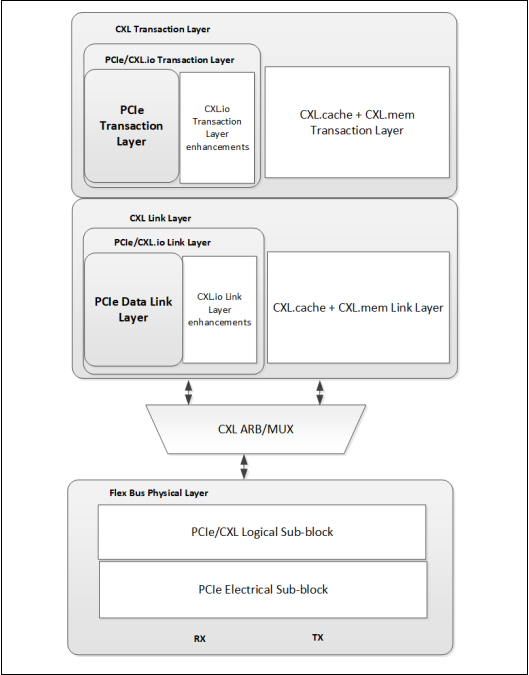
FlexBus分层的概念图
CXL.mem 和 CXL.cache 逻辑在事务层和链路层中是合并的,封装在一起并共享一个公共的链路层和事务层
在所有以 CXL 为传输链路的系统中都需要实现 CXL.io 子协议,而其他两种子协议根据预期的设备使用情况和工作负载有选择的实现
CXL 事务层中指定了数据包的事务类型、事务层包格式、事务排序规则和通道信用管理
CXL 链路层负责跨灵活总线链路数据包的可靠传输
CXL 链路层与 CXL 仲裁和多路复用模块(ARB/MUX)相连,三种子协议中的每一种数据都通过 ARB/MUX 动态的多路复用在一起,再交给灵活总线物理层进行 32GT/s 的传输
ARB/MUX 在来自 CXL 链路层的 CXL.io 和 CXL.cache/mem 的请求之间进行仲裁,跟据仲裁结果对数据进行多路复用,该结果使用加权轮询仲裁和主机设置的权重
ARB/MUX处理来自链路层的电源状态转换请求,为物理层创建单个请求以进行有序的掉电操作。
flex bus物理层作为 CXL 总线的最底层负责链路训练,使其处于操作状态,接收来自 CXL 链路层的数据信息通过灵活总线链路进行设备间的数据通信
PCIe 事务层和数据链路层可以有选择地实现,如果实现,则分别与 CXL.io事务层和链路层进行融合
flex bus物理层的逻辑子块是一个融合的逻辑物理层,可以在PCIe模式或 CXL 模式下运行,具体取决于链路训练过程中备用模式协商的结果
CXL系统架构
传统的非一致IO设备
主要依赖于标准的生产者-消费者订购模型(producer-consumer ordering model),并针对主机连接的内存(Host-attached memory主机附属的内存)执行。
除了工作提交和工作完成边界上的信号外,几乎没有与主机交互
加速器也倾向于处理数据流或大型连续数据对象
不需要CXL提供的高级功能,传统的PCIe足以作为加速器连接介质
生产者-消费者订购模型:
生产者和消费者在同一时间段内共用同一个存储空间,生产者往存储空间中添加产品,消费者从存储空间中取走产品,当存储空间为空时,消费者阻塞,当存储空间满时,生产者阻塞。两者之间通过共享内存缓冲进行通信
3类CXL设备,Type 1支持CXL.cache和CXL.io;Type 2支持CXL.cache,CXL.mem和CXL.io;Type 3支持CXL.mem和CXL.io
-
第一种设备类型 带缓存的CXL
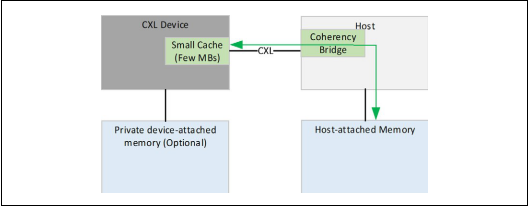
可实现缓存一致性
在PCIE上不能实现的一些复杂的原子操作,可以使得加速器使用各种的指令模型,无限制的使用原子操作
只需要很小的一部分缓存,并且缓存可以被处理器监听过滤机制追踪到
设备缓存的大小取决于主机监听过滤器能支持多少容量
可以利用CXL.cache的链路实现缓存一致性
-
第二种设备类型 带内存的CXL
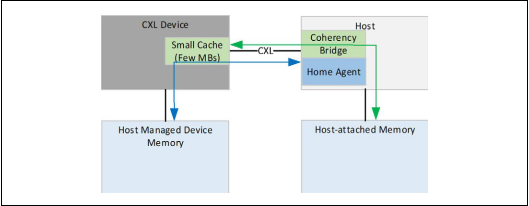
自己挂载有相关存储,比如DDR、高带宽存储(HBM)等
性能好坏跟加速器和设备挂载的存储间的数据带宽速度有关
提供一条链路,使得主机能够把操作数放到设备挂载的存储中,之后再把结果从存储中拿回来,不会增加额外的软硬件损耗
主机管理的设备存储(HDM):做过一致性系统地址映射,且由设备挂载的存储
HDM&PDM(传统的IO/PCIE私有的设备存储):
从主机挂载的存储到设备挂载的存储有大量的数据交互,涉及到拿到操作数,写回结果,额外的软硬件损耗
PDM:GDDR的GPGPU设备。GDDR被认为是GPGPU2私有的,主机并不能访问,GDDR也不需要与系统保持存储一致性。这样的存储完全由设备自己的硬件和驱动来管理
HDM,有两种设想的模型
-
带有偏向性的一致性模型的优点:
保持设备挂载的存储数据的一致性。
设备可以以高带宽的方式访问存储,同时不增加其他的缓存一致性的开支(对主机的监听)。
主机以一致的统一的方式访问设备挂载的存储,就像挂载在主机自己下面一样
-
主机偏向性的一致性模型
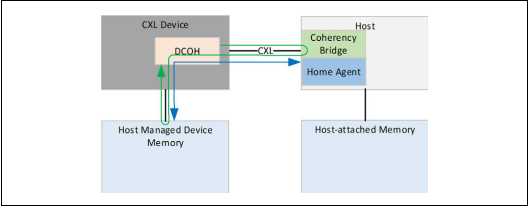
挂载在设备下的存储就好像挂载在主机下面一样,设备想访问挂载在设备下的存储,需要先向主机发起请求,有主机来解决请求的line的一致性问题
应用场景是主机在将需要计算的数据写到存储(挂载在设备下面的)中或从存储中读取计算结果
-
主机此时可以高速的访问存储(蓝色的路径),但是由于设备访问请求需要经过主机,所以设备访问存储的效率不高(绿色的路径)。
-
设备偏向性的一致性模型
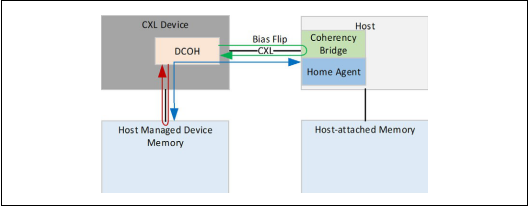
要保证主机中没有对应的cache line的副本,这样设备可以随意的访问设备挂载的存储,而不需要向主机发送任何的请求事务
设备独占了存储的访问权,其他地方没有数据的副本
设备在执行工作,需要以高带宽低延迟的方式访问存储(红色线)
主机依旧可以访问存储,但是对存储放弃了所有权,访问存储会延迟高、带宽小
-
第二种类型的设备需要做到以下几个方面:
建一个偏向表格,以页为粒度去记录偏向性(比如:1bit 记录 4KB页大小),并保存在设备里的Bias cache中。
通过TA(Transition Agent)来支持偏向性转换。就像清空page的DMA引擎,这也会清空page中对应主机里所有的cache line。
支持到加速器存储的加载和存储访问。
-
模式管理
软件辅助管理方案:
软件识别出页,并以页为粒度去选择是主机偏向还是设备偏向1bit数据用来记录4KB大小的一页。1bit数据用来记录它是主机偏向还是设备偏向。
硬件自主管理方案
根据给出的页设置和基于请求,自适应的决定是哪种偏向性
-
第三种设备类型 带内存的CXL
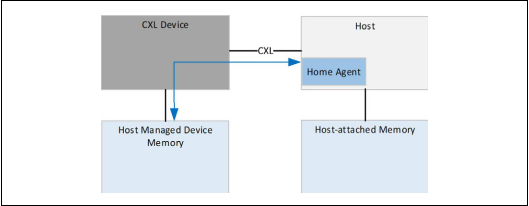
第三种设备类型是主机的内存扩展器
由于这不是加速器,设备不会通过CXL.cache发出任何请求,只是使用CXL.io和CXL.mem的协议,并没有涉及到缓存一致性的问题。
CXL.mem来服务从主机发送的请求
CXL.io用来作为设备的发现、枚举、错误报告和管理使用。
多逻辑设备(Multi Logical Device,MLD)
仅支持Type 3的多逻辑组件
MLD组件最多可以将其资源划分为16个独立的逻辑设备(Logical Device,LD),每个逻辑设备都作为Type 3设备运行
CXL.io和CXL.mem协议中,每个逻辑设备都由逻辑设备标识符(LD-ID)标识
LD-ID是一个16位逻辑设备标识符,适用于CXL.io和CXL.mem请求和响应。MLD设备返回的所有目标请求和响应必须包括LD-ID。
CXL.mem仅支持LD-ID的低4位,CXL.io支持为通过MLD端口转发的所有请求和响应携带16位LD-ID。LD-ID 0xFFFF是保留的,始终由FM使用。CXL.io利用供应商定义的本地TLP前缀来携带16位LD-ID值。
LD-ID对虚拟层次结构(Virtual Hierarchy,VH)可见,LD-ID对访问VH的软件是透明的
MLD组件对于所有逻辑设备中的每个协议都有公共事务层和链路层
MLD组件有一个为FM保留的LD和最多16个可用于主机绑定的LD
FM(Fabric Manager)结构控制器 ,FM拥有的LD(FMLD)允许FM跨LD配置资源分配,并管理与多个VCS(Virtual CXL Switch)共享的物理链路


















 1395
1395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









