






Introduction
这种操作模式以 PCIe Flit 模式为基础,其中可靠性流由物理层处理。
链路层中的flit 定义定义了插槽边界、插槽打包规则和信息流控制。
整个flit具有在物理层中定义的字段,并在本章中显示。在 68B Flit 模式中定义的 "All Data "概念在 256B Flit 模式中并不存在
Flit Overview
256B flit 有两种变体:标准和延迟优化Latency-Optimized (LOpt)。操作模式必须与物理层同步。
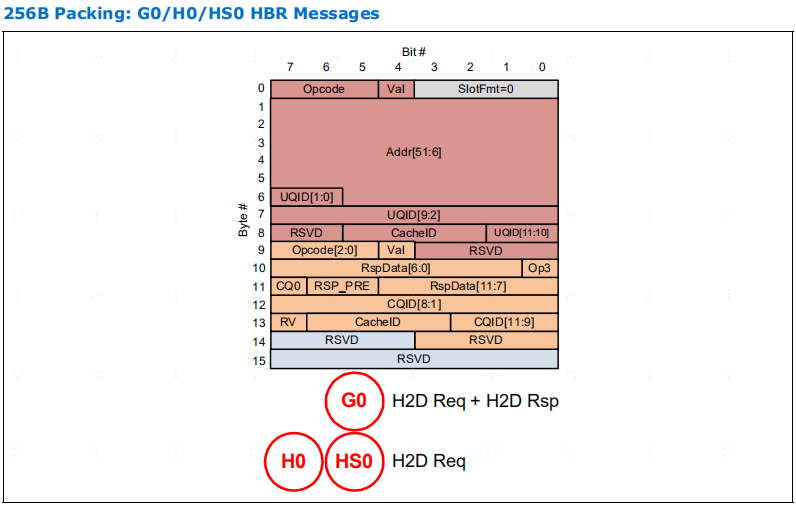
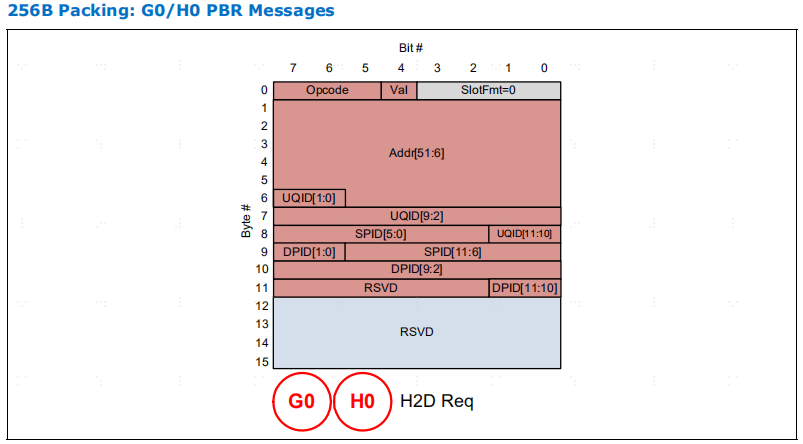
标准 256B flit 支持标准报文或基于端口的路由(PBR)报文,其中 PBR 报文带有额外的 ID 空间(DPID,有时也包括 SPID),以实现更先进的扩展/路由解决方案,详见第 3.0 章
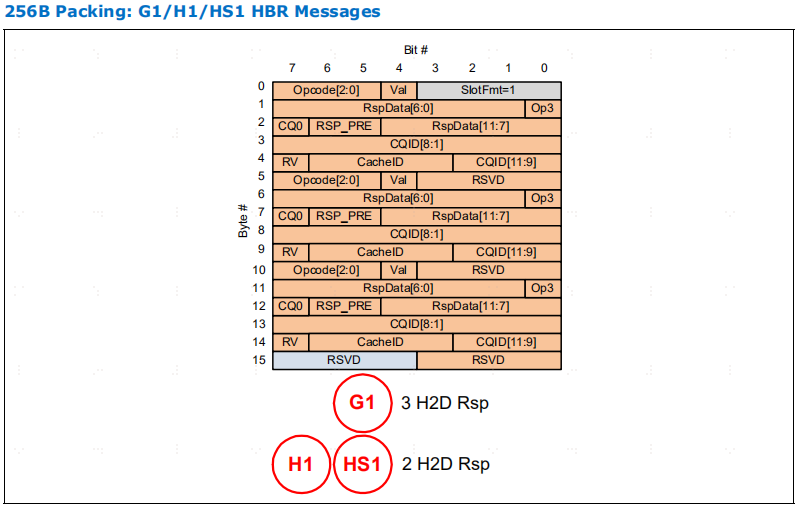
256B 流量报文被称为基于层次路由(HBR)报文,与 PBR 流量/报文相比。除非明确指出是 PBR,否则报文默认为 HBR。
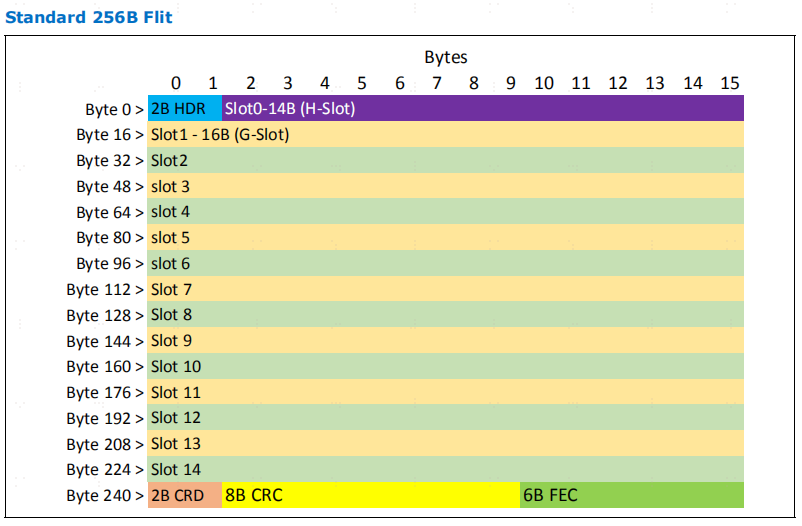
标准 256B 单位。在这种模式下,物理层控制着 16B 的比特位,其中的字段包括: HDR、CRC 和 FEC

延迟优化的比特。更多字节被分配给物理层,以便在传输无误时减少存储转发。在此比特流中,有 20B 字节分配给物理层,其中的字段包括12B CRC(分为 2 个 6B CRC 码)、6B FEC 和 2B HDR。
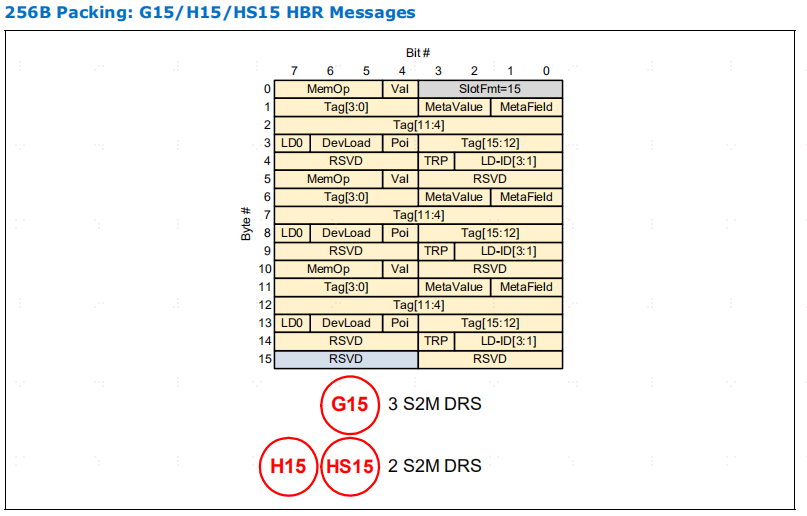
在这两种比特模式中,比特报文打包规则是通用的,但槽位 8 除外,在 LOpt 256B比特模式中,槽位 8 是一个具有特殊打包规则的 12B 槽位。这些规则是插槽 0 包装规则的子集。这种插槽格式被称为 H 子集(HS)。PBR 打包是 HBR 报文打包规则的一个子集。
插槽 7 中的某些比特被分割成 128B 的两半,结果是插槽 7 中的某些报文在检查后半部分的 CRC 之前无法读取。
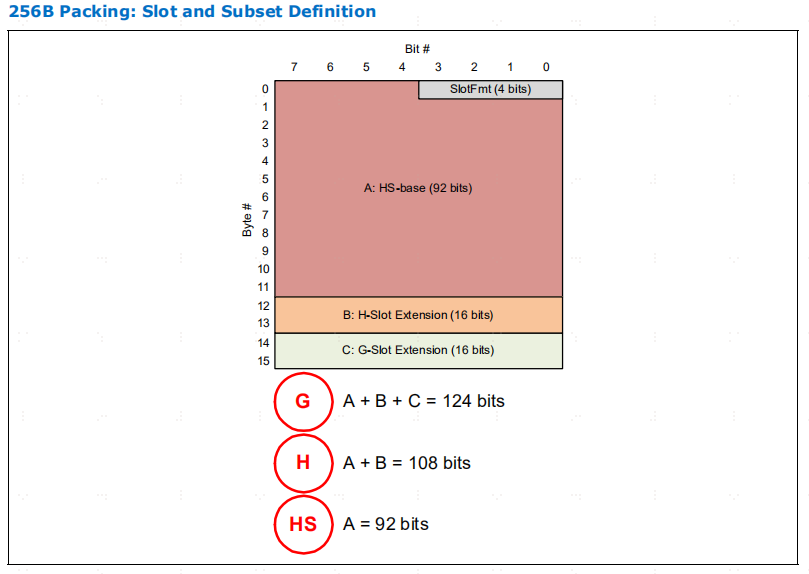
H 插槽的打包规则是 G 插槽规则的严格子集。子集关系由 14B 的 H 字节大小定义,任何超出第 14 个字节的 G 字节报文都不支持 H 字节格式。HS 插槽遵循相同的子集关系,其截止大小为 12B。
slot格式是由每个时隙开头的 4 位字段定义的,该字段包含报文头信息,这与 68B格式不同,后者的 3 位格式字段位于报文头内。
对于较大的 PBR 报文打包,由于 PBR 需要较大的报文大小,因此每个时隙中的报文都是 256B flit 报文打包规则的子集。
对于数据插槽和字节启用插槽,没有明确包含插槽格式字段,而是根据必须解码的先前报文头信息得知
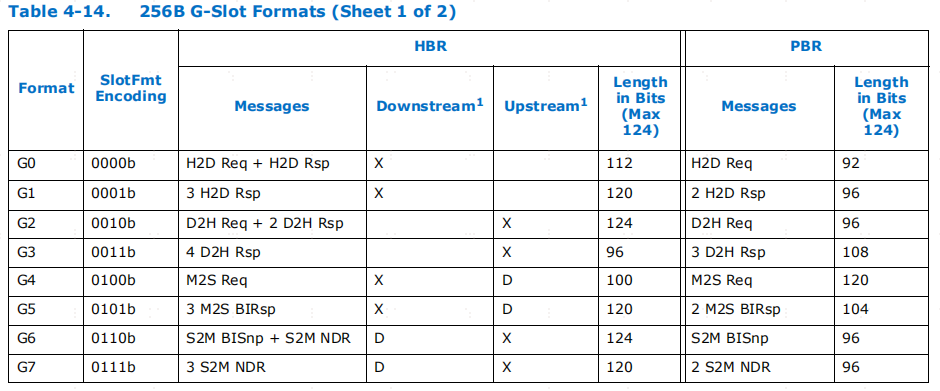
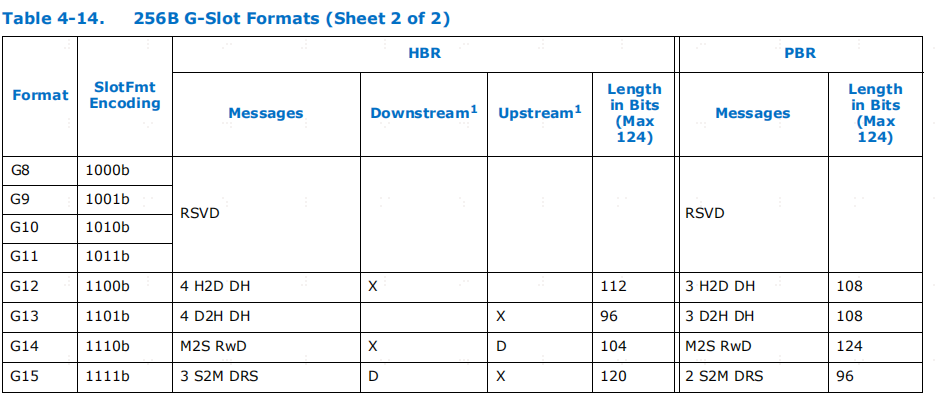
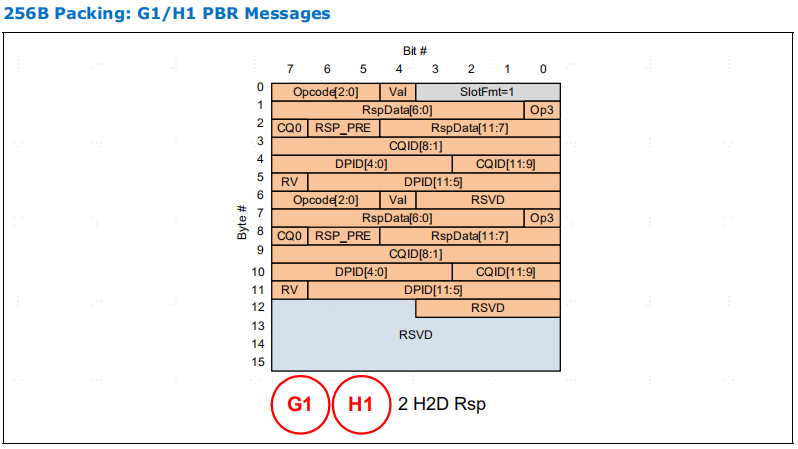
表4-14 是为 HBR (Hierarchy Based Routing)和 PBR (Port Based Routing)报文定义了 256B G 插槽。

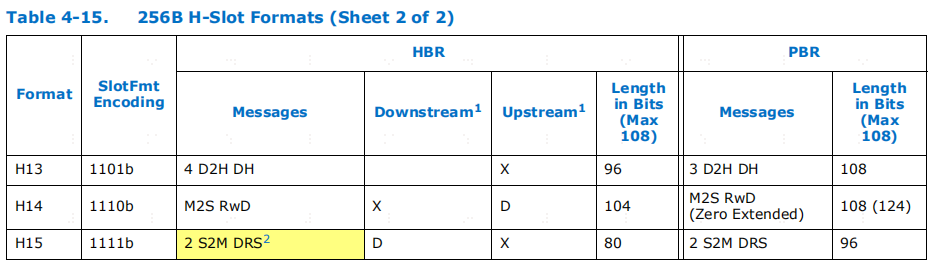
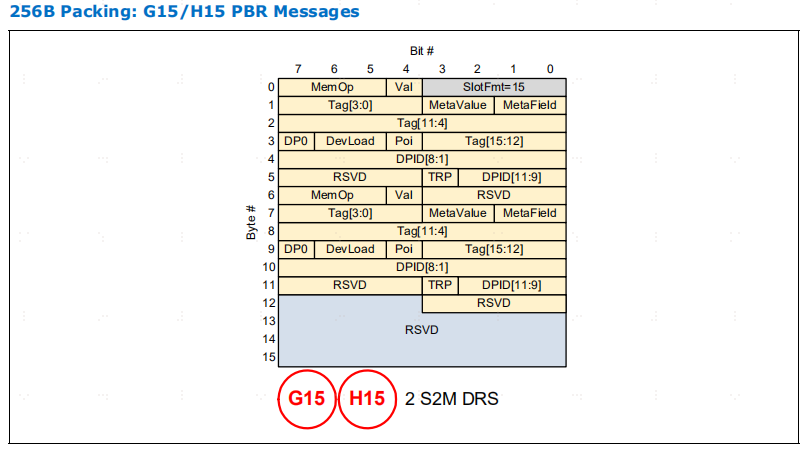
H 插槽格式。在使用插槽格式 H4 和 H14 发送的 PBR 报文中使用了 "零扩展",因为它们不适合插槽。这种方法允许报文使用这种格式,前提是未发送的比特位为 0。

HS 插槽格式。HS 插槽格式仅用于 LOpt 256B flits。请注意,HS4 和HS14 中使用了 "零扩展 "槽格式。
PBR 报文从不使用 LOpt 256B 单位,因此不使用 HS-Slot 格式。
Slot Format Definition
插槽图显示了插槽内的详细位域位置。每个插槽图都包括 G 插槽、H 插槽和 HS 插槽,其中的子集是这样创建的:H 插槽是 G 插槽的子集,其中不包括超出14 字节边界的报文。同样,HS-插槽格式是 H-插槽和 G-插槽的子集,其中不包括超出 12 字节边界的报文。


缩写列表
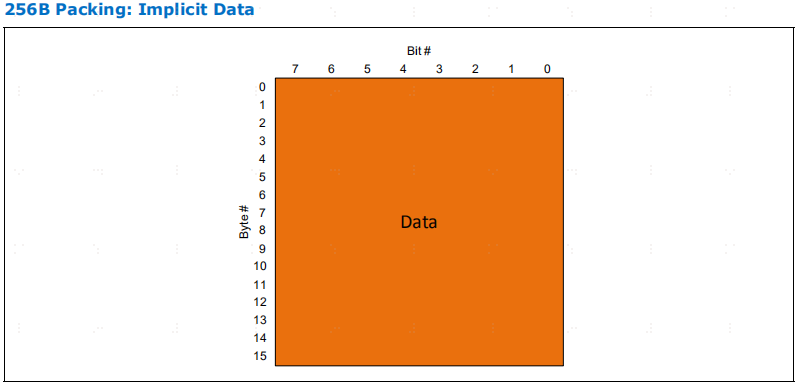
Implicit Data Slot Decode
根据之前的报文头,可以隐含地知道 G 槽的数据和字节启用槽。
为简化slot格式字段的解码,可使用 SlotFmt 快速解码,以了解下 4 个 G 槽是否为数据槽。4 个 G 槽之外的其他 G槽也可能携带数据,这取决于翻转值、有效数据报文头的数量以及报文头中的 BE 位。
H 插槽和 HS 插槽从不携带数据,因此它们总是有明确的 4 位编码来定义格式。
实施说明:当前槽的快速解码用于确定接下来的 4 个 G 槽是否为数据槽。与 G 槽相比,H/HS 槽所需的解码不同。H/HS 插槽比较 SlotFmt[3:2] 等于 11b,而 G 插槽只比较 SlotFmt[3] 等于 1。解码要求不同是因为 H8/HS8 格式表示 LLCTRL 信息,而 G8 是保留编码。
由于链路层数据路径宽 64B,每个时钟只处理 4 个槽,因此可以简化解码,减少逻辑中的关键路径,以确定 G 槽是数据槽还是报头槽。所有进一步的解码都从上一个时钟周期开始。
下图显示了快速解码 SlotFmt 字段以确定哪些槽是隐式数据槽的示例。此外,由于 H 槽从不携带数据,因此可以在不知道先前报头的情况下对其进行解码。
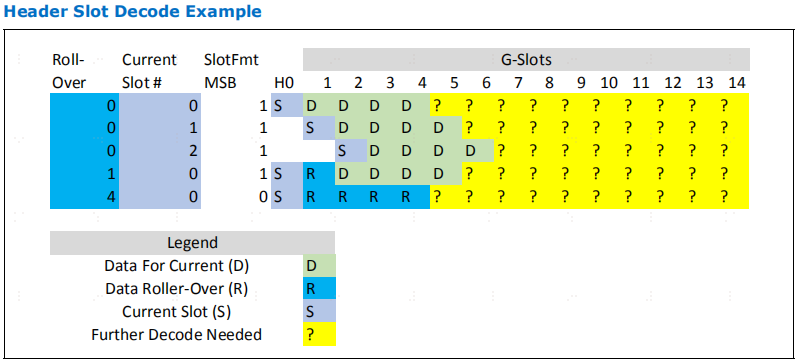
这段主要讲的这个slotfmt这个编码 在之前flit没有剩余的slot要发情况下 (也就是1,2,3行)此时编码为1 ,那么接下来的四个数据槽就是它要发的数据。第四行 rollerover=1 就是有之前的flit要发的1个数据
Trailer Decoder
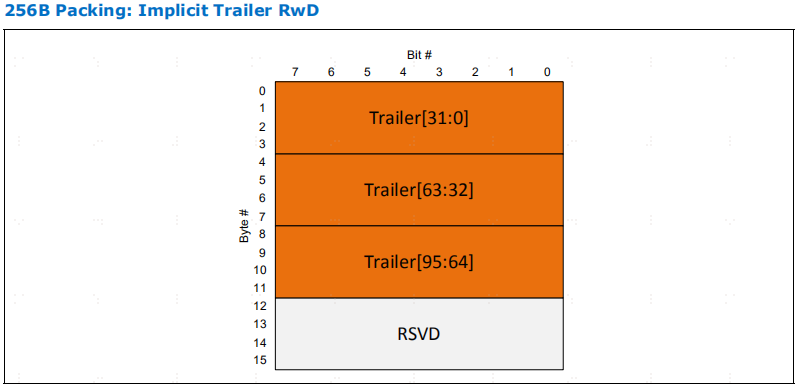
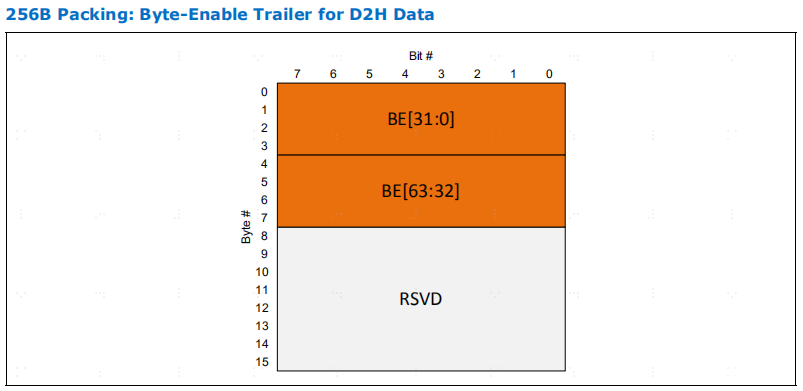
当报文头中的 TRP 或 BEP 位被设置时,数据传输报文中就会包含一个trailer。trailer的大小可根据链路的能力而变化。基本功能要求支持trailer的 "字节启用 "用例。trailer的扩展元数据 (EMD) 使用是可选的
对于 RwD 和 D2H DH 报文,如果为报文设置了 TRP 或 BEP,则trailer字符始终跟随 4个数据槽
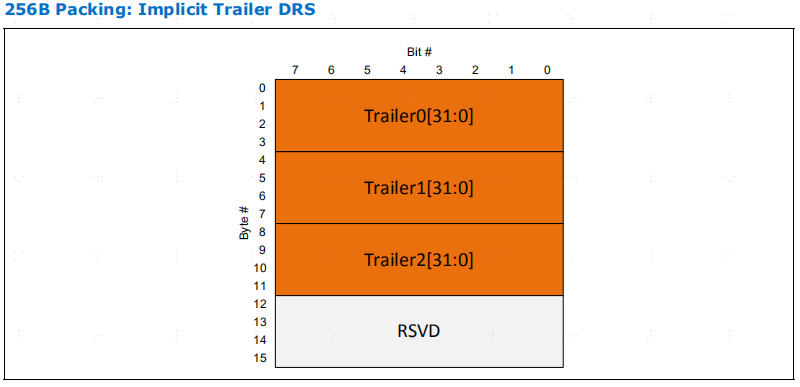
对于 DRS,即使数据头0没有相关的trailer,trailer也能在数据头 0 的第一次 64B数据传输后将最多 3 个trailer打包在一起。在 TRP 位被设置的情况下,每个报文头的trailer都会被紧密打包。
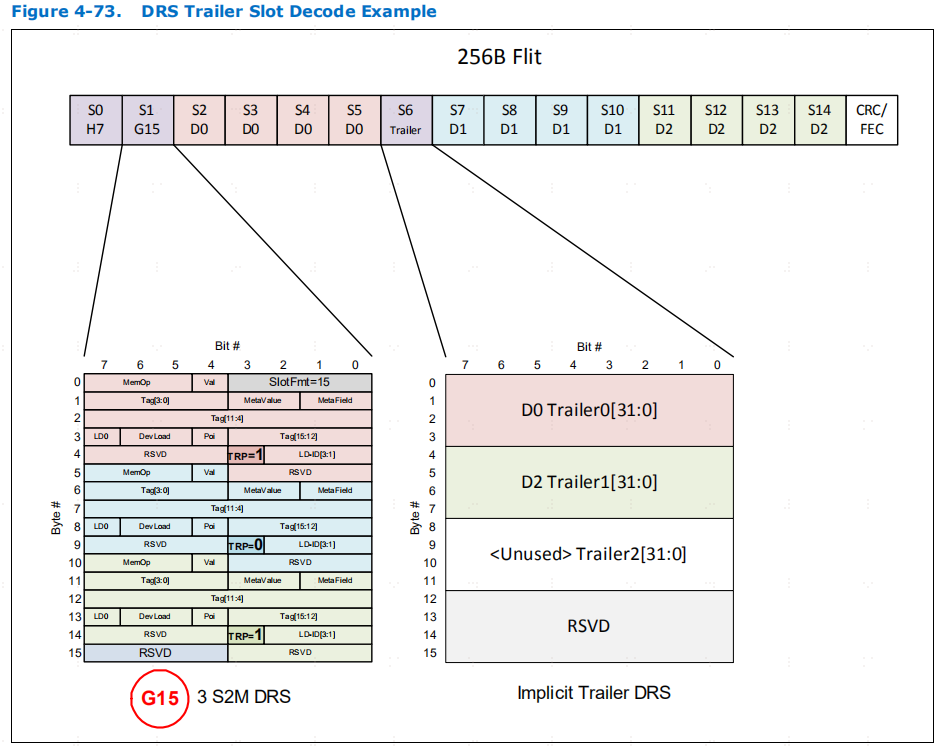
这个组织形式和trailerslot的含义跟CXL规定有关,传输层在介绍D2H DATA、H2D DATA等和数据传输相关的message header时说:如果设置了TRP/BEP域段,则在后续第5个slot会放置对应的信息,大部分情况是字节使能,还有些情况是Meta Data
256B Flit Packing Rules
256B 单位的规则在位顺序和密集规则方面遵循与 68B 单位相同的基本要求。密集规则适用于最多 4 个槽位组,而不是整个单位。这些组的定义如下0 至 3、4 至 7、8至 11 和 12 至 14。请注意,最后一组只跨 3 个插槽。
要发送的剩余数据槽小于或等于 16 个, Tx 在 H 槽/HS 槽中注入数据头
剩余数据的最大计数限制为 36(16 + 4(新数据头)* 5(4 个数据插槽+ 1 个字节启用插槽)= 36)
MDH 禁用控制位用于将有效数据报头位数限制为每个插槽一个
如果使用数据头插槽格式(G/H/HS 12 至 15),则第一个报文必须设置有效位
rolling
最大报文规则适用于滚动 128B 分组,其中分组为 A="插槽 0 至 3",B="插槽 4 至7",C="插槽 8 至 11",D="插槽 12 至 14"。将这些规则扩展到 128B 边界可使 256Bflit 插槽格式完全利用。
256B flit 插槽每个插槽的报文数量往往超过传统 68B flit 报文速率所允许的数量。扩展到 128B 可以在不增加单位带宽报文速率的情况下使用这些高报文数插槽。
滚动的定义是将各组合并为 128B 个滚动组:AB(0 至 7 号信槽)、BC(4 至 11 号信槽)、CD(8 至 14 号信槽)和 DA(12 至 14 号信槽在当前信道中,0 至 3 号信槽在下一个信道中)。最大报文速率适用于每个组。LOpt 256B flit 对这一规则进行了修改,将插槽 7 包括在 B 组和 C 组中:B="插槽 4 至 7",C="插槽 7 至 11"。子组C 有 5 个插槽。
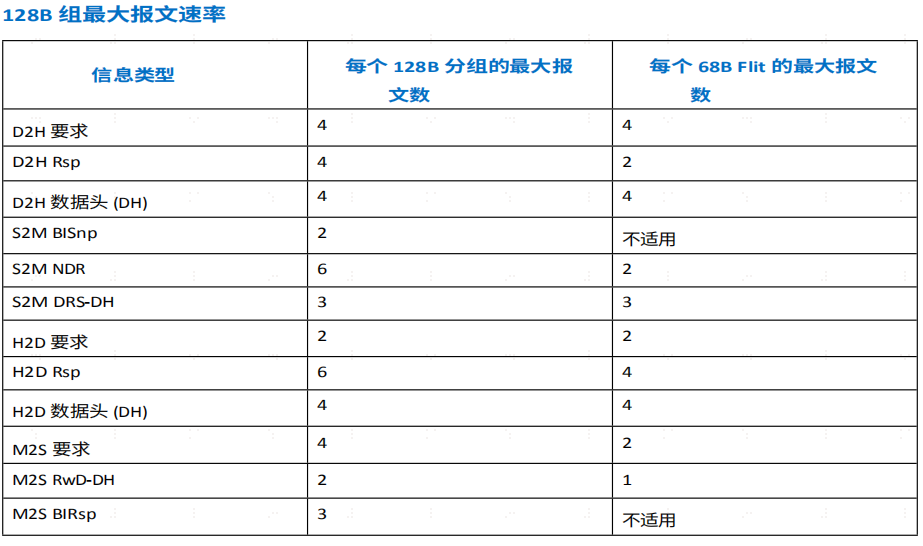
定义了每个 128B 分组的最大报文传输速率,其中包括 68B flit 报文传输速率
不适用于 256B 单位的其他 68B 规则:
MDH 规则要求每个 MDH >1 个有效报文头。在 256B 插槽中,每种报文类型只提供一种打包格式,因此该规则不适用;
与 BE 相关的规则并不适用,因为它们是用单独的报文头位而不是flit头位来处理的,而且在 TRP 或 BEP 位被设置时,对报文的数量也没有特别的限制。
32B 传输规则不适用,因为只支持 64B 传输。
H 插槽和 G 插槽之间的打包选择会对效率产生直接影响。如果能充分利用 H 插槽(或 HS 插槽)的报文与能更好地利用 G 插槽的报文相比,优先使用 H 插槽,则效率可能会提高。
该模式可发送 MemRd、MemWr 和 BIRsp 的稳定下游流量。在此示例中,MemRd 和 MemWr 可以充分利用 H 型插槽,并没有因为打包到 G 型插槽而受益。与 H 型插槽(2)相比,BIRsp 的打包可以让 G 型插槽(3)容纳更多的信息,因此优先将其打包到 G 型插槽中可以提高效率。在本例中,与简单的加权轮循仲裁相比,将 BIRsp 优先分配到 G 插槽可改善约 1.5% 的带宽。
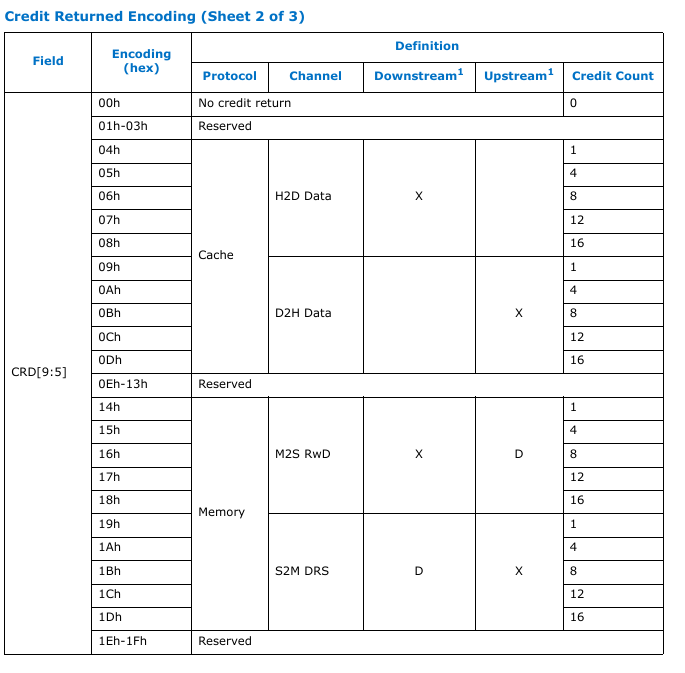
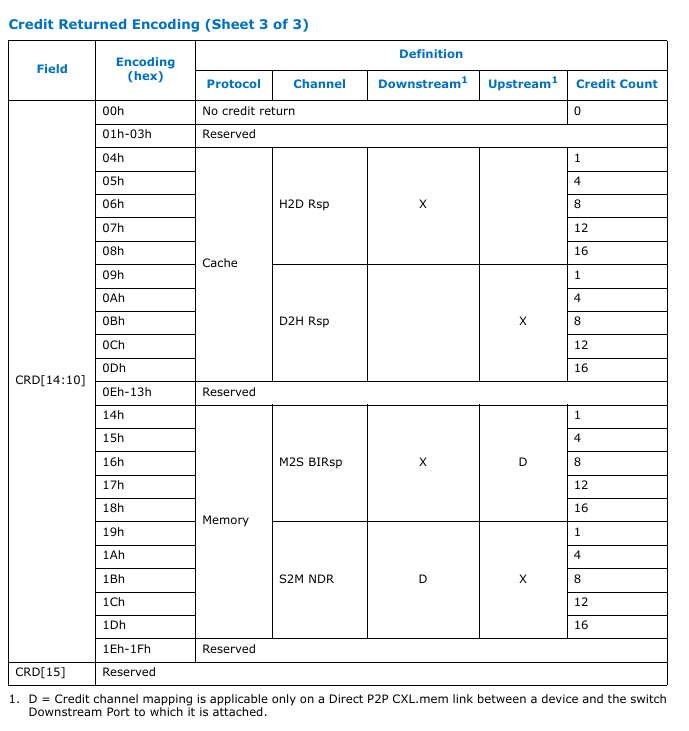
Credit Return
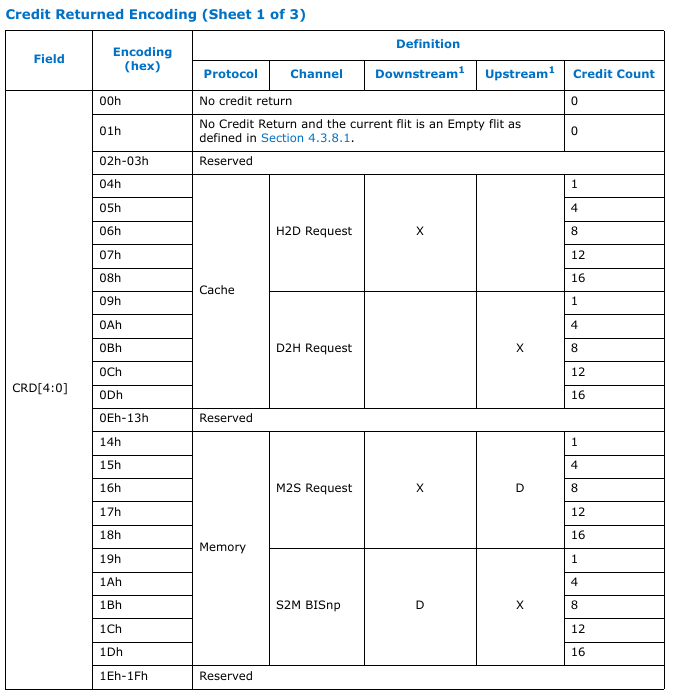
这个章节主要讲的是 256B flit 中要返回多少个信用值的credit return encoding
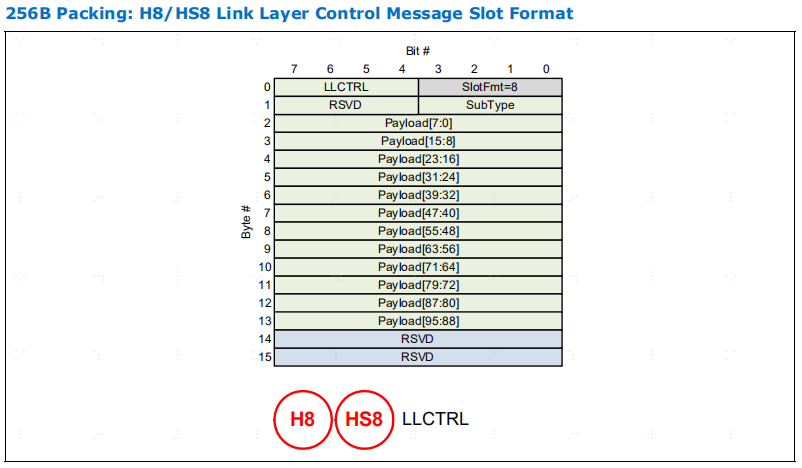
Link Layer Control Messages
在 256B Flit 模式下,控制报文使用 H8 格式编码,有时也使用 HS8 格式编码。
下图为 LLCTRL 报文的 256B 包装。
4 位插槽格式编码后;H8 提供 108 位用于编码控制报文,8 位用于编码 LLCTRL/子类型,4 位作为保留位,有效载荷为 96 位;对于 HS8,它被限制为少 2 个字节,从而将可用有效载荷减少到 80 位。
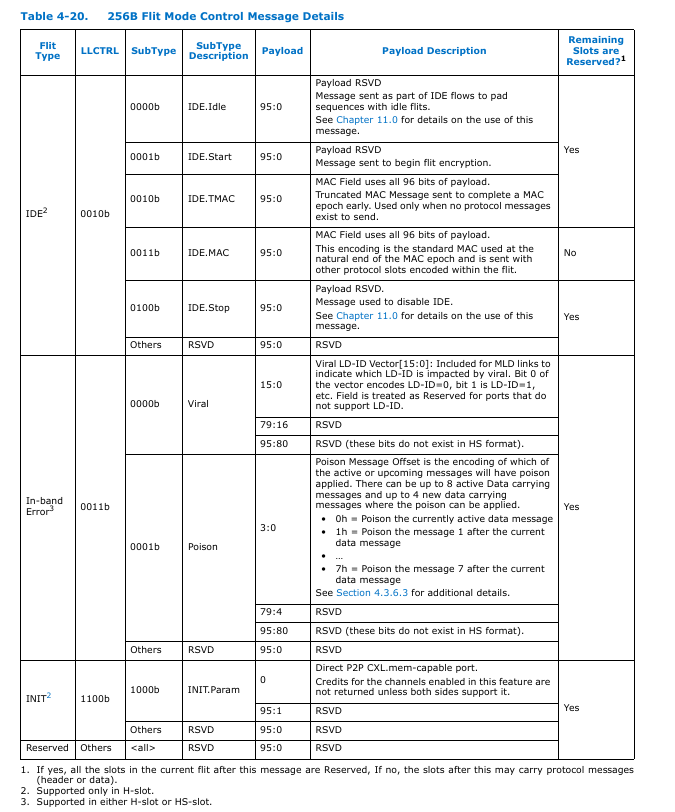
下表列出了已定义的控制信息。几乎在所有情况下,控制信息后的剩余槽都被视为保留槽(即清零),不携带任何协议信息。但 IDE.MAC 是个例外,它允许在单位内的其他槽中发送协议信息。对于注入 HS 槽的信息,HS 槽之前的slot可携带协议信息,但 HS 槽之后的slot为保留时隙
Link Layer Initialization
在初始链路训练(从链路 Down 开始)之后,链路层必须在开始正常运行之前 发送和接收 INIT.Param 信号。达到正常运行后,链路层将首先使用标准credit返还机制返还所有可能的credit。在发送其他控制信息(IDE、带内错误)之前,也需要正常运行
Viral Injection and Containment
Late Poison
Link Integrity and Data Encryption (IDE)
Credit Return Forcing
为避免饥饿,信用返还规则确保即使在没有协议报文待处理的情况下也能发送信用。
在 68B Flit 模式中,这使用了一种名为 LLCRD 的特殊控制报文(其算法在第4.2.8.2 节中有描述)。对于 256B Flit 模式,使用相同的强制基础算法,但有以下变化:
Ack forcing 不适用于 256B flit。
对于256B flits,CRD 是标准单位定义的一部分,因此不需要特殊的控制报文。
由于协议报文与 CRD 都属于 256B 单位,因此不需要对它们进行优先排序。
当执行4.3.8的一种特殊打包方法时,如果没有有效报文或信用返回,则会将flit末尾标记为空。除非触发了信用强制算法,否则只有在有其他有效报文发送时,flit才会返回一个非零的信用值。
Latency Optimizations
为了获得最佳的延迟特性,256B 的比特流预计将与实现 64B 或 128B 流水线的链路层和延迟优化比特流(可选)一起发送。这些功能的基本原理是不言而喻的。
通过向 ARB/MUX 发送空闲时隙调度流量,可避免等待流量对齐的下一次开始,从而实现额外的延迟优化。CXL.io 与空闲slot调度之间存在权衡,因此应考虑整体带宽。
实施说明:空闲slot调度需要考虑的一种情况是链路层流水线为 64B 时,空闲slot允许将晚到的报文打包到flit的后面。通过这种方式,发射机可以利用空闲slot开始传输,从而避免停滞。
一个 x4 端口的例子就是这样,报文出现时刚好错过了前 64B的信道。在这种情况下,由于 ARB/MUX 注入的是空比特或来自 CXL.io 的比特,因此在发送报文前还需要等待 192B 的时间。在本例中,在 x4 中观察到的额外延迟为 6 ns(192 字节/x4 * 8 位/字节/64 GT/s)。
Empty Flit
作为本章所描述的延迟优化的一部分,链路层需要包含一种方法来指示当前flit没有报文或 CRD 信息。在这种情况下,"空 "的定义是整个单位可以被丢弃,而不会对链路层产生副作用:
• 不发送数据插槽
• 任何协议插槽中都未设置有效位
• 不发送控制信息
• CRD 字段不返回 Credits

















 2771
2771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









