







链路层有两种运行模式:68B flit 和 256B flit。68B flit 在链路层中定义为 66B,在 ARB/MUX中定义为 2B,支持高达 32 GT/s 的物理层速度。为了支持更高的速度,定义了 256B的流量定义;该流量定义的可靠性流量由物理层处理,因此 68B 流量模式的重试流量不适用。256B 信道可支持任何法定传输速率,但必须大于 32 GT/秒。
High-Level CXL.cachemem Flit
flit是flow control unit的缩写,flit是最小的流控单元,也是链路层的传输单元。
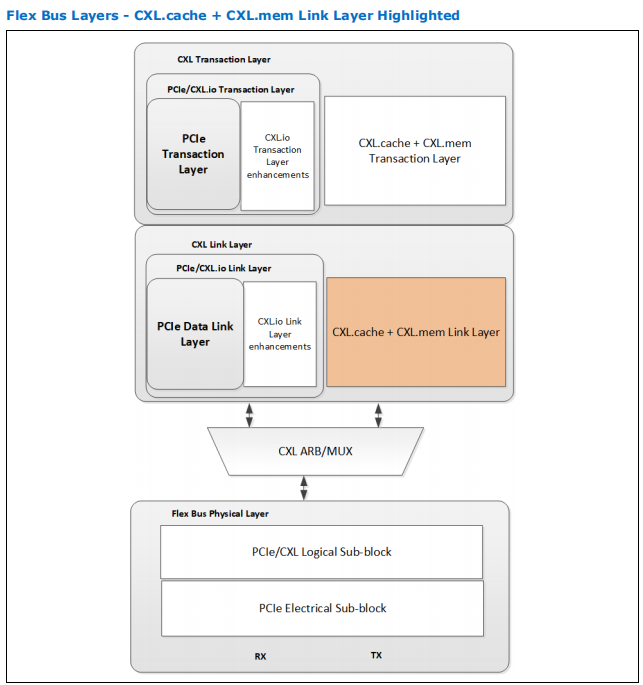
相比于CXL.io的链路层,它是独立于PCIE的,并且cache通道和mem通道共用。
链路层接收来自事务层的数据,经过处理之后,形成自己的flit数据类型,之后发给物理层。每个flit其实就是一拍的数据。每个flit是固定的528bit数据,其中16bit的CRC校验码。由于每个数据块是128bit,所以
512bit的数据至少要有4个数据块。
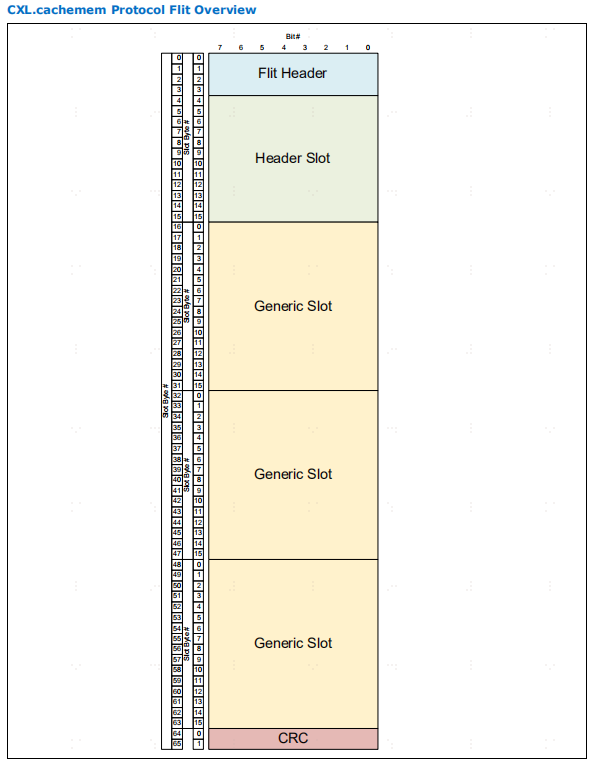
CXL.cachemem flit 大小为固定的 528bit。如下图所示,有 2B (16bit)的 CRC 代码和 4 个各为 16B 的插槽。
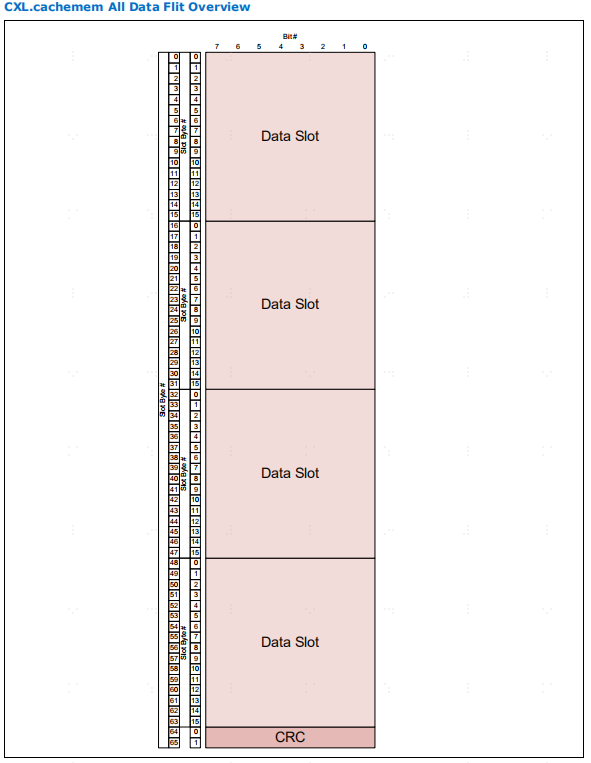
数据块分为两种类型,一种是header数据块(帧头数据块),一种是Generic数据块(通用数据块)。下图第一张是带有header的flit,第二张是全数据的flit。
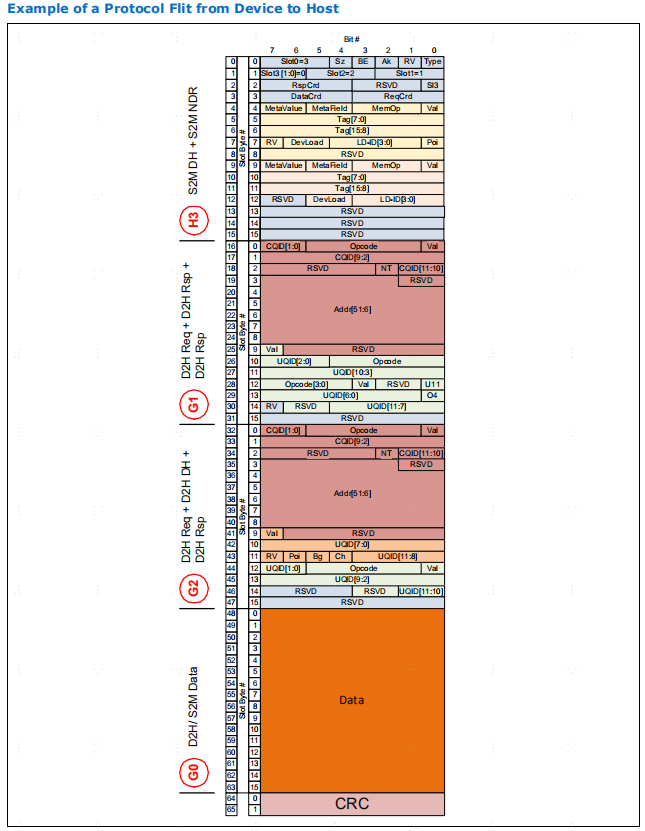


Ak 字段是链路层重试协议的一部分,用于向远端发送器发出通过 CRC 的信号。发送器设置 Ak 位,以确认成功收到 8 个单位;接收器忽略清除的 Ak 位。
BE(字节启用)和 Sz(大小)字段与数据报文的可变大小有关。为了达到其效率目标, CXL.cachemem 链路层假定大多数数据通常都启用了所有字节,而且数据是以完整的高速缓存行粒度传输的。当所有字节都启用时,链路层不会传输字节启用比特,而是清除相应比特头的字节启用字段。当接收器解码字节启用字段被清除时,它必须将字节启用位重新生成全 1,然后再将数据报文传递给事务层。如果字节使能位被设置,链路层 Rx 将期待一个包含字节使能信息的额外数据块槽
Sz 字段反映了 CXL.cachemem 协议允许以半高速缓存线粒度传输数据的事实。当设置 "大小 "位时,链路层 Rx 预计会有四个数据块插槽,相当于一个完整的高速缓存行。清除 "大小 "位后,链路层 Rx 只需要两个数据块插槽。在后一种情况下,每半个高速缓存行传输都会有自己的数据报头。
将 "大小 "和 "字节使能 "信息打包到流量报文头中的一个重要假设是,每个流量报文包最多只能发送一条数据报文

发送机设置 CRD 字段,以显示同地接收机可释放的资源,供远程发送机使用。每个报文类别的传输都有credit,这就是为什么flit head包含独立的请求、响应和数据 CRD字段。请注意,在 S2M 方向上没有源于请求的信息,在 M2S 方向上也没有源于响应的信息
在数据通道上发送的报文要求整个报文使用一个Data Credit。这意味着,1 个credit可进行一次数据传输,包括报文头,无论传输量是 64B 或32B,还是包含字节使能
事务层要求所有携带有效载荷的报文都要发送 64B 的数据,而链路层允许将这些报文作为独立的 32B 报文发送,以便在只有 32B 数据准备发送的特定实施情况下优化延迟
每次flit发出的数据块中,带有纯数据的时候,就消耗一个信用,不管数据是64bytes, 32bytes还是带有64bits的byte enable的数据块,如果没有信用就不能发送。同时请求数据块和相应数据块也是一样的。信用是接收方给发送方的。
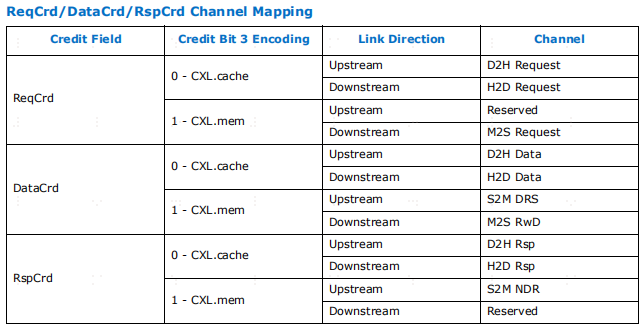
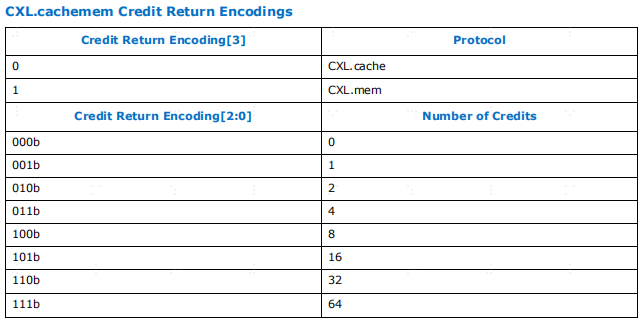
通道映射的详细信息。对于设备或主机不支持的通道,返回的credit应被静默丢弃。credit的粒度为每条信息,这些字段以指数方式编码
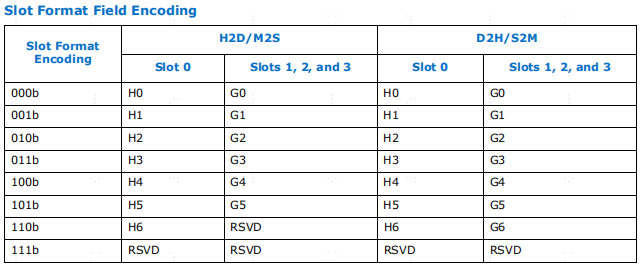
slot0/1/2/3对应的数据块格式类型。字段位宽是3bit
"槽格式类型"(Slot Format Type)字段对片头槽和单位中其他通用槽的槽格式进行编码(如果 "单位类型"(Flit Type)位指定该单位为协议单位)。提供了槽格式字段编码的快速参考
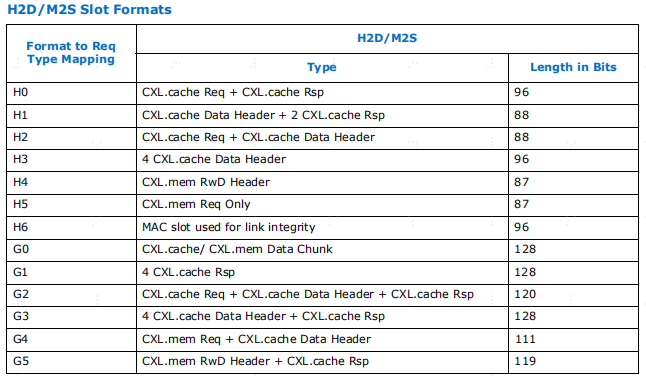
如果DLL判断数据是来自于事务层H2D通道的,那么3'b000,对于slot0来说,就是H0格式的,对于slot1/2/3就是G0格式的。为什么slot0要特殊,因为flist header只能是放在slot0中的前32bit位置,这就会导致128bit的数据块,还剩96bit装数据了,不像slot1/2/3有128bit的量。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 83
83

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









