






今年KAN横空出世,现在已经推出2.0版本,大有一统AI+科学的趋势。
仅仅发布4个月,就有很多KAN和LSTM/Transformer/时间序列/强化学习等结合的应用,在深度学习/自然语言处理/图像处理/数学金融/生物等非常多AI+领域展示出超强的性能。
KAN能提高模型的准确性和可解释性,并具有高度的灵活性和泛用性,逐渐成为研究的热点之一。
为了帮助大家寻找发文的创新点,本文总结了KAN+LSTM、KAN+Transformer、KAN+时间序列预测等全家桶系列研究成果。
需要的同学添加公众号【沃的顶会】 回复 KAN 即可全部领取
KAN原文
Kolmogorov–Arnold Networks
文章解析:
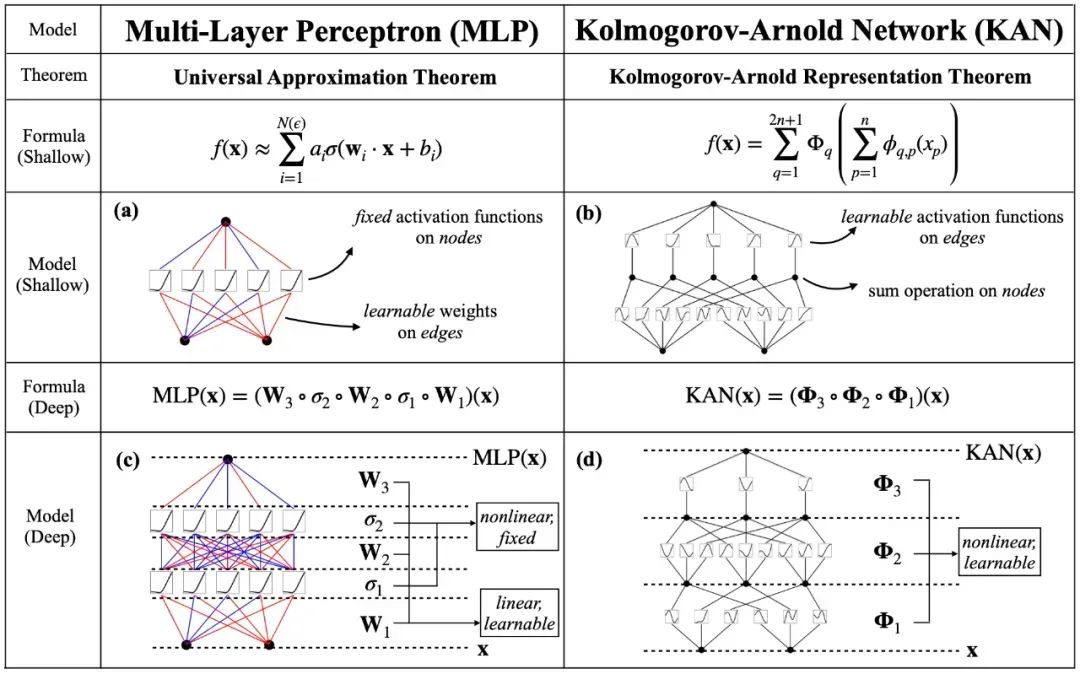
本文提出了一种全新的神经网络结构——Kolmogorov-Arnold Networks(KANs),旨在通过在网络边缘(而非传统的节点)引入可学习的激活函数,显著提升模型的准确性和可解释性。
深度学习模型,尤其是多层感知器(MLPs),在可解释性和参数效率方面存在明显的不足。传统的MLPs依赖于固定的激活函数,这不仅限制了模型的灵活性,还使得其内部机制难以解读。
相比之下,KANs通过在网络边缘引入参数化的可学习激活函数(基于样条函数),直接在模型设计阶段解决了这些问题,从而实现了更高的可解释性和模型性能的提升。
创新点:
1.受到Kolmogorov-Arnold表示定理的启发,提出KANs作为一种替代MLPs的模型,旨在通过在边缘上放置可学习的激活函数来提高模型的准确性和可解释性。
2. KANs的设计允许模型在保持完全连接结构的同时,通过学习激活函数来更好地捕捉和表示高维数据中的复杂关系。
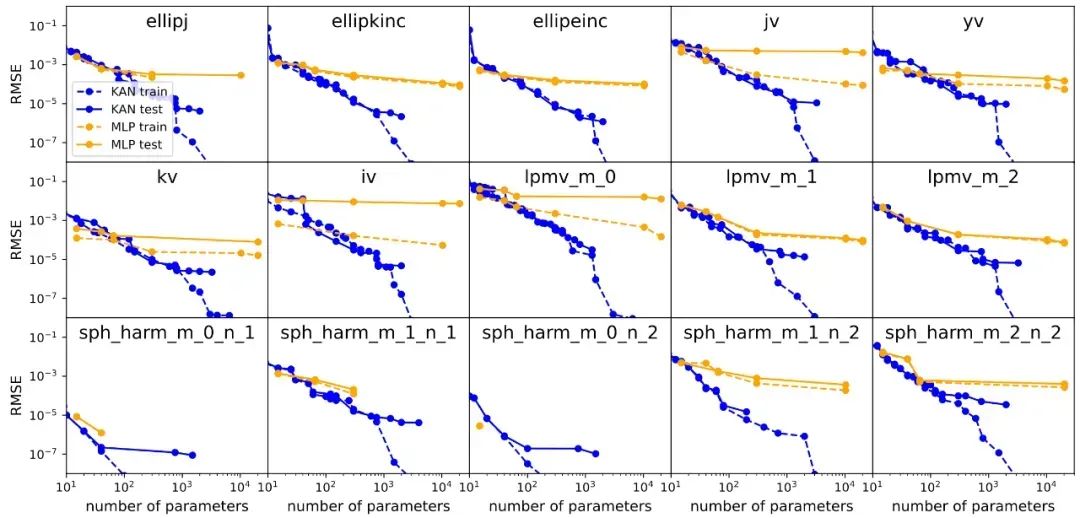
3.通过实验,展示了KANs在小规模AI+Science任务中相较于MLPs在准确性和可解释性方面的优势,特别是在数学和物理定律的发现中,KANs能够作为科学家的有用“合作者”。
需要的同学添加公众号【沃的顶会】 回复 KAN 即可全部领取
KAN+时间序列
Kolmogorov-Arnold Networks (KANs) for Time Series Analysis
文章解析:
本文介绍了一种新颖的Kolmogorov-Arnold Networks(KANs)在时间序列预测中的应用,重点展示了其通过自适应激活函数增强预测模型性能的独特优势。
现代机器学习技术通过数据驱动的方法识别时间模式,在深度学习的推动下,神经网络、长短期记忆(LSTM)网络等模型在时间序列预测中取得了显著成效。然而,传统多层感知器(MLP)尽管成功应用于许多领域,却在可扩展性和可解释性方面存在局限性。
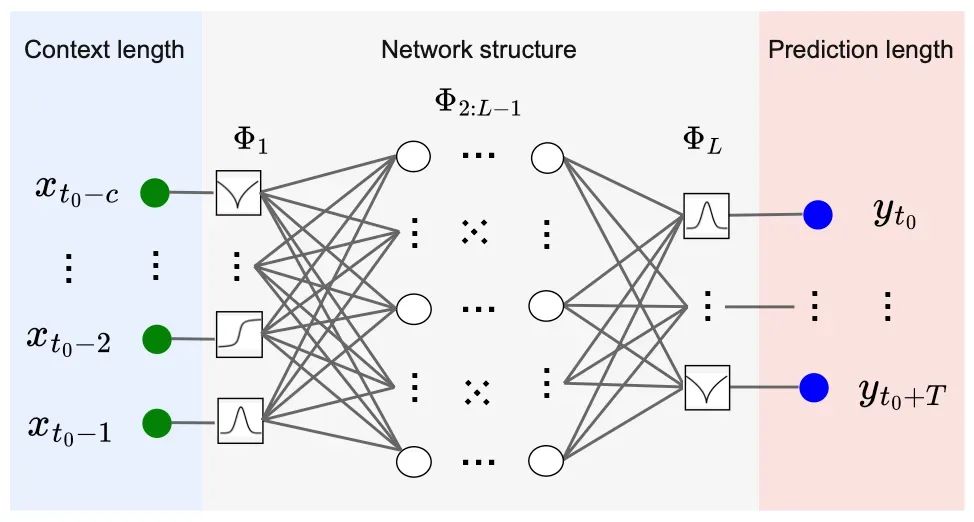
KANs作为一种创新的神经网络架构,基于Kolmogorov-Arnold表示定理,通过将线性权重替换为基于样条的自适应单变量函数,使得网络能够动态学习和优化激活模式。
本文旨在评估KANs在实际时间序列预测中的应用潜力,分析其在可训练参数数量和预测精度方面与传统MLP的对比表现,探讨其在复杂时间序列应用中的优势。
创新点:
1.KANs利用样条函数作为激活函数,能够根据时间序列数据的动态特性自适应地调整激活模式,这与传统的固定激活函数相比,可以更精确地捕捉时间序列中的复杂模式和变化。
2.KANs通过减少模型中的参数数量,实现了对时间序列数据的有效预测。这种优化使得模型更加简洁,同时保持或提高了预测精度,这对于处理大规模时间序列数据尤为重要。
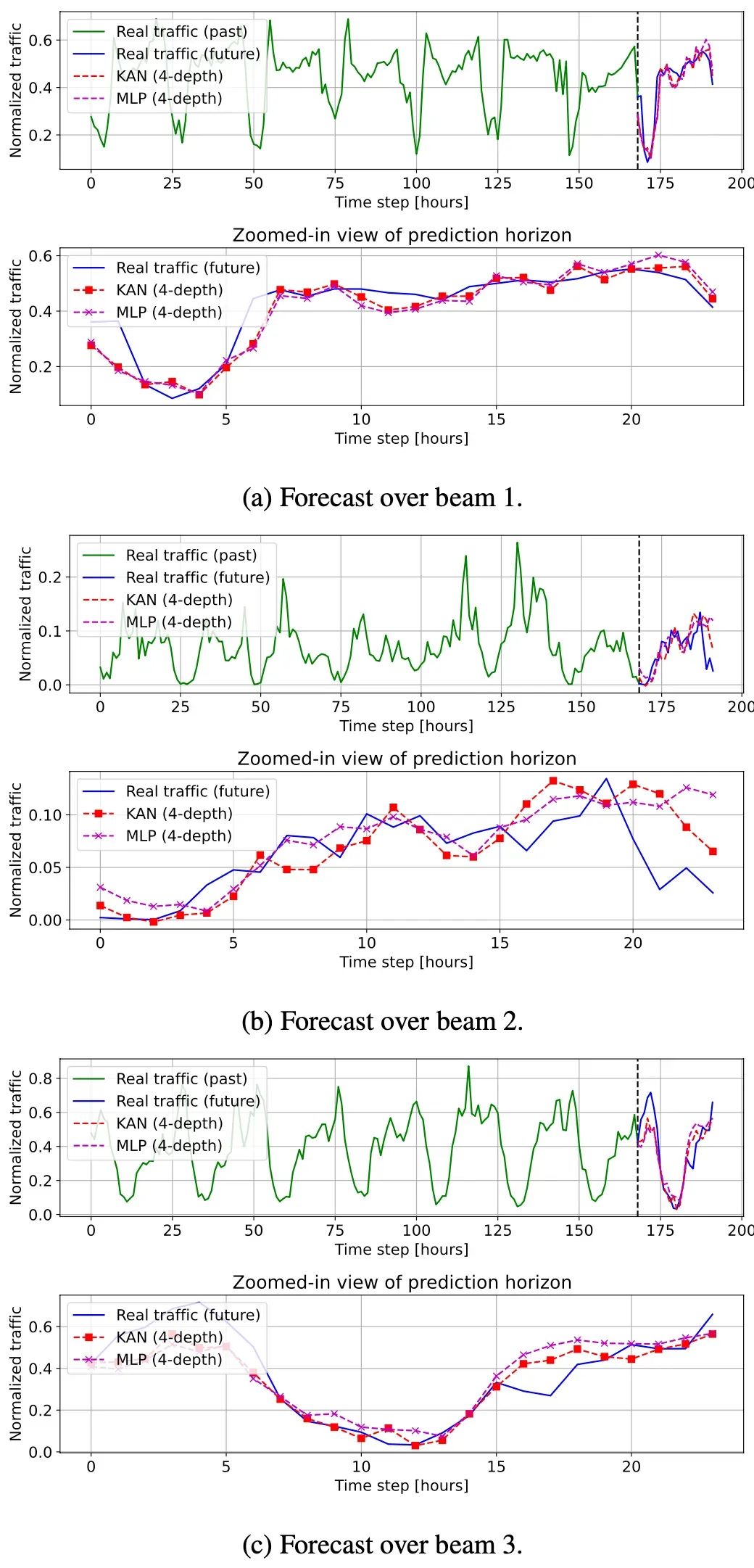
3.通过实际的卫星流量预测任务验证了KANs相比于传统MLPs在预测精度上的提升。KANs能够更准确地预测未来的时间序列值,这对于需要高精度预测的领域如金融市场分析、气象预测等具有显著的应用价值。
需要的同学添加公众号【沃的顶会】 回复 KAN 即可全部领取















 1576
1576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









