







写在前面
在《4.0机器学习模型编码》中提到one-hot独热编码时,我们提到了维度、维度爆炸和降维的概念。降维,简单来说就是c++中的稀疏矩阵变为链表等占用更小资源的形式的操作。在这一篇中,我们将重点介绍几种最常见的降维方法。
- 1.python基础;
- 2.ai模型概念+基础;
- 3.数据预处理;
- 4.机器学习模型--1.编码(嵌入);2.聚类;3.降维;4.回归(预测);5.分类;
- 5.正则化技术;
- 6.神经网络模型--1.概念+基础;2.几种常见的神经网络模型;
- 7.对回归、分类模型的评价方式;
- 8.简单强化学习概念;
- 9.几种常见的启发式算法及应用场景;
- 10.机器学习延申应用-数据分析相关内容--1.A/B Test;2.辛普森悖论;3.蒙特卡洛模拟;
- 11.数据挖掘--关联规则挖掘
- 12.数学建模--决策分析方法,评价模型
- 13.主动学习(半监督学习)
- 以及其他的与人工智能相关的学习经历,如数据挖掘、计算机视觉-OCR光学字符识别、大模型等。
目录
主成分分析(PCA, Principal Component Analysis)
最近重构性(Minimum Reconstruction Error)与最大可分性(Maximum Separability)
线性判别分析(LDA, Linear Discriminant Analysis)
独立成分分析(ICA, Independent Component Analysis)
t-分布随机邻居嵌入(t-SNE, t-Distributed Stochastic Neighbor Embedding)
多维缩放(MDS, Multidimensional Scaling)
等度量映射(Isomap, Isometric Mapping)
局部线性嵌入(LLE, Locally Linear Embedding)
主成分分析(PCA, Principal Component Analysis)
主成分分析是一种降维技术,通过线性变换将原始数据投影到新的坐标系中组合成新的不相关变量(称为主成分),从而找到数据中的主要变异方向,减少数据的维度,同时尽可能保留原始数据的方差。这些主成分按照方差大小排序,方差越大代表信息量越多。
概念
PCA的主要目标是将高维数据投影到低维空间,以减少数据维度。它通过寻找数据最大方差的方向,重新定义坐标系,并根据数据的变化方向构建新的轴。这些新轴(主成分)是相互正交的,且首个主成分方向是数据方差最大的方向,第二个主成分方向是剩余方差最大的方向,依此类推。
大白话概念
在PCA中,"特征"可以理解为数据中的“属性”或者“维度”。每一列数据往往代表某个特征,比如你在分析房价数据,特征可能是房子的面积、房间数、楼层、地段等。PCA的目的是通过主成分找出这些特征中的主要变化方向,也就是数据变化的“重要维度”。
- 特征就是数据集里不同的“方面”或“角度”,它们是用来描述你数据的东西。比如一个人的身高、体重、年龄都是特征。
- PCA做的事情相当于是找出这些特征中最重要的几个,并用它们去描述数据,同时忽略那些不太重要的特征。就好比你要描述一件事,可能你只需要抓住其中的两三个关键点,而不需要把所有细节都列出来。
- 主成分就是这些关键点,它们是根据特征组合出来的,能更好地表示数据的主要差异。
因此,PCA可以简化问题,把高维的复杂特征压缩成更少的、更核心的特征,从而减少计算量,同时保留最有价值的信息。
原理
- 去均值:将数据集的每个特征减去其均值,使数据的均值为零。
- 计算协方差矩阵:计算去均值后的数据的协方差矩阵,协方差矩阵反映了特征之间的线性相关性。
- 求解特征值和特征向量:对协方差矩阵求解特征值和特征向量,特征值反映了每个特征向量的方差大小。
- 选择主成分:按照特征值的大小排序,选择最大的一些特征值对应的特征向量,作为新的主成分。
- 降维:将原始数据投影到这些选定的主成分构成的低维空间上,实现降维。
最近重构性(Minimum Reconstruction Error)与最大可分性(Maximum Separability)
这两个概念是降维方法(如PCA)的核心优化目标,分别从数据表示和分类性能的角度出发。
- 最近重构性核心思想:降维后的数据应能尽可能准确地重构回原始数据,即重构误差最小。类似于“压缩数据但尽量不丢失信息”。
- 最大可分性核心思想:降维后的数据应最大化不同类别(或不同模式)的可区分性,通常体现为:类间方差最大化、类内方差最小化。类似于“让不同类别的数据点在低维空间尽量分开”。(数学表达详见下:LDA)
协方差矩阵 & 特征值和特征向量
协方差矩阵(Covariance Matrix)是用来衡量不同特征之间的线性相关性的一个矩阵。它反映了数据集各个特征之间的相互依赖关系。具体来说,协方差衡量两个变量的变化趋势,即如果两个变量同时增大或减小,协方差为正;如果一个增大、另一个减小,协方差为负;如果没有线性关系,协方差接近零。
通俗解释: 想象你有一堆不同的水果,每种水果有不同的特征,比如重量和甜度。协方差矩阵就是用来描述这些特征之间如何一起变化的。例如,如果重量增加时甜度也通常增加,那么重量和甜度之间的协方差就是正的;如果重量增加时甜度通常减少,协方差就是负的;如果两者之间没有明显关系,协方差接近于零。
协方差公式

对于多维数据集,协方差矩阵是所有特征协方差的组合,其元素 C(i,j) 表示第 i 个特征与第 j 个特征的协方差。对于一个 m 维数据集,协方差矩阵是一个 m×m 的矩阵。
协方差矩阵的计算

python求解
在Python中可以使用numpy.cov()函数计算协方差矩阵:
import numpy as np
# 数据矩阵 X (每行是一个样本,每列是一个特征)
X = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# 计算协方差矩阵
cov_matrix = np.cov(X.T) # 需要转置,因为 np.cov() 期望每行是一个特征
print(cov_matrix)
[[9. 9. 9.]
[9. 9. 9.]
[9. 9. 9.]]
在这种情况下:
协方差矩阵中所有元素都是 9,这意味着所有特征之间的协方差都是相同的,且为正值。这种情况通常出现在以下情形:
-
完全相关的特征:
- 在你的数据矩阵 XXX 中,每个特征都是线性相关的。具体来说:
- 第二列(特征2)总是等于第一列(特征1)加 1: 2=1+1,5=4+1,8=7+1
- 第三列(特征3)总是等于第一列(特征1)加 2: 3=1+2,6=4+2,9=7+2
- 这种线性关系意味着特征之间完全相关,导致协方差矩阵中的所有协方差都是相同的。
- 在你的数据矩阵 XXX 中,每个特征都是线性相关的。具体来说:
-
数据在低维空间中完美对齐:
- 由于特征之间的完全线性相关,数据实际上只在一个维度上有变化(例如,沿着第一列的变化),而其他特征的变化完全由第一列决定。
- 因此,协方差矩阵的秩(rank)为 1,这意味着所有的特征向量都沿着同一方向,这也导致协方差矩阵中所有元素相等。
协方差矩阵全为 9 的矩阵说明以下几点:
-
特征之间完全线性相关:
- 所有特征之间存在完美的线性关系。即,知道一个特征的值,就可以准确地推断出其他特征的值。
-
数据的变异性集中在一个方向:
- 数据在特征空间中主要沿着一个方向变化。这意味着所有的数据点都位于一个直线上,数据的主要变化由一个主成分(即一个特征向量)描述。
-
冗余特征:
- 由于特征之间完全相关,实际上存在冗余信息。可以通过主成分分析(PCA)将数据降维到一个维度,而不会损失任何信息。
此时,这个矩阵的特征值和特征向量如下:
-
特征值:
- 27(对应一个特征向量)
- 0(对应两个特征向量)
-
特征向量:
- 第一个特征向量对应特征值 27,指向所有特征方向相同的方向。
- 其他两个特征向量对应特征值 0,表示在这些方向上没有变异性。
解释特征值和特征向量
-
最大特征值 27:
- 表示数据在该特征向量方向上的变异性最大。这是唯一有意义的特征值,因为其他特征值为 0,表示在其他方向上没有变异性。
-
特征向量:
- 第一个特征向量(对应特征值 27)指向数据变化的主要方向。
- 其他特征向量(对应特征值 0)表示与主要方向正交的方向,但由于数据在这些方向上没有变异性,因此这些特征向量没有实际意义。
特征值和特征向量的概念

换句话说,特征向量是经过矩阵变换后方向保持不变的向量,而特征值则表示这些向量被拉伸或压缩的比例。
求解特征值和特征向量

在PCA中,协方差矩阵的特征值表示每个主成分的方差,而特征向量则是主成分的方向。
通俗解释: 想象你有一把万能钥匙(协方差矩阵),可以打开任何锁(图像的变化模式)。特征向量就是这把钥匙上特定的凹槽形状,而特征值则表示这些凹槽的重要性或强度。一个特征向量对应的特征值越大,说明这个凹槽在解锁中越关键。
python求解
可以使用numpy库中的eig()函数来计算特征值和特征向量:
import numpy as np
# 一个 2x2 矩阵
A = np.array([[4, 2],
[1, 3]])
# 求解特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eig(A)
# 输出结果
print("特征值:", eigenvalues)
print("特征向量:\n", eigenvectors)
输出的特征值表示矩阵变换的缩放因子,而特征向量表示相应的方向。
特征值: [5. 2.]
特征向量:
[[ 0.89442719 -0.70710678]
[ 0.4472136 0.70710678]]
在PCA中,特征值和特征向量是协方差矩阵的,特征值越大,说明这个方向的方差越大,保留的信息越多。
PCA的步骤
- 标准化数据:对原始数据进行标准化。
- 计算协方差矩阵:计算标准化数据的协方差矩阵。
- 特征分解:对协方差矩阵进行特征值分解,获取特征值和特征向量。
- 选择主成分:根据特征值的大小选择前k个主成分。
- 转换数据:将数据投影到选定的主成分上,得到降维后的数据。
使用Python的sklearn库进行PCA操作:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
# 加载数据集
data = load_iris()
X = data.data
y = data.target
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# PCA降维,保留两个主成分
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
# 打印主成分解释的方差比率
print("Explained variance ratio:", pca.explained_variance_ratio_)
# 结果可视化
plt.figure(figsize=(8, 6))
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis', edgecolor='k', s=100)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA of Iris Dataset')
plt.colorbar()
plt.show()
输出:
Explained variance ratio: [0.72962445 0.22850762]
在鸢尾花数据集中,一共有150个样本,每个样本有四个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)。通过 PCA 降维,四个特征被压缩为两个主成分,这两个主成分可以用来可视化样本的分布。
- 每个点表示一个鸢尾花样本。
- 颜色表示该样本所属的类别(不同种类的鸢尾花)。
降维后的“主成分”不再对应于原始数据集中的具体特征,而是由原始特征的线性组合生成的。也就是说,主成分是基于原始特征重新计算出的方向,代表数据中最大方差的方向。这些方向(主成分)的名字通常用“主成分1(Principal Component 1)”、“主成分2(Principal Component 2)”等来表示,而不再是原始特征的名称(比如“花萼长度”、“花瓣宽度”等)。
如果想知道每个主成分是由哪些原始特征组合而来的,可以查看PCA模型的 特征向量,它们描述了每个主成分是原始特征的线性组合。可以通过pca.components_属性查看每个主成分对应原始特征的权重(即每个特征在主成分中的贡献),代码如下:
# 打印每个主成分的特征权重
print("PCA components (每个主成分对应的特征权重):")
print(pca.components_)
# 打印特征名称
print("原始特征名称:", data.feature_names)
pca.components_返回的是一个矩阵,每一行对应一个主成分,每一列对应原始特征。矩阵中的值是原始特征在该主成分中的贡献权重。data.feature_names是Iris数据集中的原始特征名称,依次为['sepal length', 'sepal width', 'petal length', 'petal width']。
输出:
PCA components (每个主成分对应的特征权重):
[[ 0.36138659 -0.08452251 0.85667061 0.3582892 ]
[ 0.65658877 0.73016143 -0.17337266 -0.07548102]]
这表示第一个主成分(PC1)是原始特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)的线性组合,其中权重分别为0.36, -0.08, 0.86, 0.36,这意味着花瓣长度对PC1的贡献最大。
核化PCA(Kernel PCA, KPCA)
核PCA(Kernel Principal Component Analysis)是传统PCA的非线性扩展,它通过核技巧(Kernel Trick)将数据隐式映射到高维特征空间,并在该空间中进行线性PCA,从而实现对非线性数据结构的降维,将问题转变为求解核矩阵的特征问题。(核函数的作用:详见本专栏《4.4分类-SVM》)。
from sklearn.decomposition import KernelPCA
import numpy as np
import matplotlib.pyplot as plt
# 生成非线性数据(半月形)
from sklearn.datasets import make_moons
X, _ = make_moons(n_samples=100, noise=0.1, random_state=42)
# 使用高斯核KPCA降维到2D
kpca = KernelPCA(n_components=2, kernel='rbf', gamma=15)
X_kpca = kpca.fit_transform(X)
# 可视化
plt.scatter(X_kpca[:, 0], X_kpca[:, 1])
plt.title("KPCA on Nonlinear Data")
plt.show()线性判别分析(LDA, Linear Discriminant Analysis)
针对有标签的数据集,LDA试图找到可以最大化类间距离和最小化类内距离的投影方向。它是分类问题中常用的降维方法。使用了Fisher判别器的思想,也可以用于分类任务。
LDA思想非常朴素:给定训练样本集,设法将样本投影到一条直线,使得:
- 同类样例的投影点尽可能的接近,
- 异类样例的投影点尽可能的远离;
在对新样本进行分类时,将其投影到同样的直线上,再根据投影点位置确定新样本类别。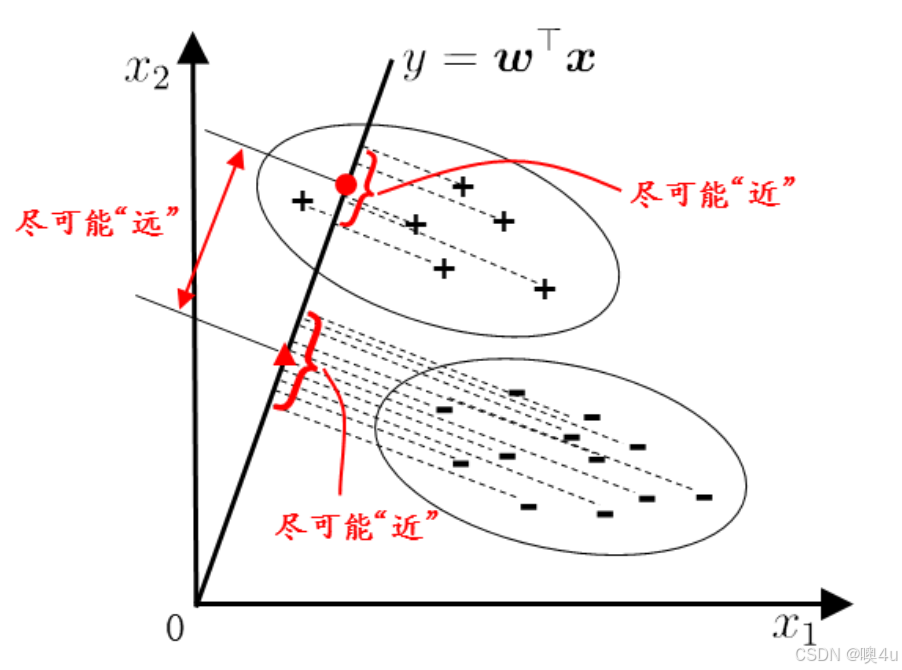
- “+”、“_”分别代表正例和反例,椭圆表示数据簇外轮廓,虚线表示投影,红色实心圆和实心三角形分别表示:两类样本投影后的中心点.



LDA可从贝叶斯决策论解释:两类数据同先验、满足高斯分布且协方差相等时,LDA达到最优分类。
LDA与PCA的区别
- PCA 是无监督的,它不关心数据的类别标签,只是寻找数据整体方差最大的方向。
- LDA 是有监督的,它利用类别信息,寻找可以最好地区分不同类别的投影方向。
LDA的应用场景
LDA常用于数据降维和分类任务,尤其在数据类别之间具有明显差异时效果较好。它在模式识别、图像分类、文本分类等领域广泛应用。
步骤
- 计算类内散布矩阵:衡量同一类别内数据的离散程度。
- 计算类间散布矩阵:衡量不同类别之间数据的离散程度。
- 求解特征值和特征向量:根据类内和类间散布矩阵,找出特征值和特征向量,从而确定投影方向。
- 降维和投影:将原始数据投影到低维空间,实现降维。
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
# 加载数据集
data = load_iris()
X = data.data
y = data.target
# 使用LDA降维
lda = LinearDiscriminantAnalysis(n_components=2)
X_lda = lda.fit_transform(X, y)
# 可视化结果
plt.figure(figsize=(8, 6))
plt.scatter(X_lda[:, 0], X_lda[:, 1], c=y, cmap='viridis', edgecolor='k', s=100)
plt.xlabel('LD1')
plt.ylabel('LD2')
plt.title('LDA of Iris Dataset')
plt.colorbar()
plt.show()
在此代码中,使用LDA将Iris数据集从四维空间降到二维,之后可视化LDA的结果。
输出:

LD1 和 LD2 的含义
1. LD1(第一线性判别分量):
- LD1 是 LDA 计算出的第一个投影方向,它在降维过程中最大化了类间散布与类内散布的比率。这意味着 LD1 是在能够最好地区分不同类别时所得到的第一维度。
- LD1 的值表示样本在这个投影方向上的坐标,样本在 LD1 上的分布可以反映不同类别之间的差异。
2. LD2(第二线性判别分量):
- LD2 是 LDA 计算出的第二个投影方向,它同样最大化类间差异,但在此方向上还保持与 LD1 正交(即不相关)的特性。LD2 试图进一步区分类别,尽管它可能没有 LD1 那么强的区分能力。
- LD2 的值同样表示样本在这个投影方向上的坐标,并且可以用来辅助理解数据的结构。
独立成分分析(ICA, Independent Component Analysis)
旨在将多变量信号分解为统计上独立的成分,通常用于信号处理。ICA的基本假设是多个观测信号是由若干个潜在的独立成分线性组合而成。通过分析这些观测信号,ICA试图恢复出原始的独立成分。ICA利用非高斯性特性(如峰度或负熵)来分离信号。通过对观测信号进行线性变换,最大化非高斯性,从而提取独立成分。
ICA的应用场景
- 盲源分离:例如在语音处理,ICA可以分离多个重叠的音频信号。
- 信号去噪:通过提取独立成分,可以去除噪声信号。
- 特征提取:在图像处理和生物信号分析中,ICA可用于提取有意义的特征。
ICA的步骤
- 中心化数据:将观测数据的均值归零,以消除均值的影响。
- 白化数据:将数据转化为零均值且协方差为单位矩阵的形式,以消除数据的相关性。
- 估计独立成分:使用迭代算法(如FastICA算法)来提取独立成分。通过最大化非高斯性指标,找到独立成分。
分离混合信号
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import FastICA
# 生成混合信号
np.random.seed(0)
S1 = np.sin(2 * np.pi * np.linspace(0, 1, 1000)) # 信号1
S2 = np.sign(np.sin(3 * np.pi * np.linspace(0, 1, 1000))) # 信号2
S3 = np.random.rand(1000) # 信号3
S = np.c_[S1, S2, S3]
# np.c_ 是 NumPy 中的一个函数,用于按列连接多个数组。在这里,它将 S1、S2 和 S3 这三个一维数组(每个长度为 1000)连接成一个二维数组 S,其中每一列代表一个独立信号。
# 结果是 S 是一个形状为 (1000, 3) 的二维数组,表示有 1000 个样本和 3 个独立的信号成分。
# 创建混合矩阵
A = np.array([[1, 1, 1], [0.5, 1, 2], [1, 2, 1]])
X = S.dot(A.T) # 混合信号
# 定义了一个混合矩阵 A,其形状为 (3, 3)。这个矩阵用于将独立成分(信号)组合成混合信号。
# 每一行代表一个新的信号是如何由原始独立成分线性组合而成的。具体来说:
# 第一行表示第一个混合信号是所有三个信号的简单求和。
# 第二行表示第二个混合信号是从每个信号中提取一定比例(例如,1 倍 S1 + 0.5 倍 S2 + 2 倍 S3)。
# 第三行表示第三个混合信号是按照特定权重线性组合。
# A的形状为 (3, 3),第一个3指的是有三个组合输出信号,第二个3指的是有三个原始信号。第一个3只能多不能少(相当于三元一次方程组必须有大于等于三个方程才有可能有唯一解);第二个3只能是3。
# S.dot(A.T) 表示 S 和 A 的转置矩阵的矩阵乘法。
# A.T 是将混合矩阵 A 转置,变成形状为 (3, 3) 的矩阵。
# 矩阵乘法的结果 X 形状为 (1000, 3),表示生成的混合信号
# 使用ICA分离信号
ica = FastICA(n_components=3)
S_ = ica.fit_transform(X) # 提取独立成分
A_ = ica.mixing_ # 估计的混合矩阵
# 可视化结果
plt.figure(figsize=(10, 8))
plt.subplot(3, 1, 1)
plt.title('Original Signals')
plt.plot(S)
plt.subplot(3, 1, 2)
plt.title('Mixed Signals')
plt.plot(X)
plt.subplot(3, 1, 3)
plt.title('Separated Signals (ICA)')
plt.plot(S_)
plt.tight_layout()
plt.show()
输出:

自编码器(Autoencoder)
一种神经网络结构,通过将数据压缩成一个低维表示,然后重建回原始数据。适用于非线性降维。(会在第六篇《几种神经网络模型》中具体涉及)
t-分布随机邻居嵌入(t-SNE, t-Distributed Stochastic Neighbor Embedding)
用于非线性降维,特别适合于高维数据的可视化。它通过将数据点映射到低维空间,使得相似数据点在低维空间中也尽可能接近。
t-SNE的特点
- 保留局部结构:t-SNE非常擅长保留数据中的局部结构,能够使得相似的样本在可视化中聚集在一起。
- 处理非线性关系:与PCA不同,t-SNE能够捕捉数据中复杂的非线性关系,因此在处理高度非线性的高维数据时效果更佳。
t-SNE的应用场景
t-SNE广泛应用于数据可视化、图像处理、文本数据分析等领域,特别是在处理复杂数据集(如图像、文本、基因组数据)时。
t-SNE的步骤
- 计算相似度:首先,t-SNE为高维空间中的每对数据点计算条件概率,表示一个点在给定另一个点的情况下作为邻居的概率。这通常是通过高斯分布来实现。
- 构建低维空间:然后,在低维空间中,t-SNE使用t分布(概率论与数理统计概念)来计算点之间的相似度。t分布在低维空间中比高斯分布更为平坦,这使得t-SNE能够更好地处理聚类。
- 优化:t-SNE使用梯度下降等优化算法(运筹学概念)来最小化高维空间与低维空间中点的相似度之间的差异,从而找出最佳的低维表示。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
from sklearn.datasets import load_iris
# 加载数据集
data = load_iris()
X = data.data
y = data.target
# 使用t-SNE降维
tsne = TSNE(n_components=2, random_state=42)
X_tsne = tsne.fit_transform(X)
# 可视化结果
plt.figure(figsize=(8, 6))
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y, cmap='viridis', edgecolor='k', s=100)
plt.xlabel('t-SNE Component 1')
plt.ylabel('t-SNE Component 2')
plt.title('t-SNE of Iris Dataset')
plt.colorbar()
plt.show()
输出:

- t-SNE的坐标轴并不反映原始特征的意义。它们是算法生成的特征,并不对应于原始数据集中具体的特征。
- 散点图的主要目的是为了观察样本之间的相对位置和聚类关系,而不是分析坐标轴的具体数值。因此,t-SNE主要用于可视化和探索数据的潜在结构。
-
t-SNE Component 1:
- 这个坐标轴代表t-SNE算法生成的第一个维度。它是通过t-SNE算法对原始高维数据进行处理后,生成的第一主成分。
- 这个轴上的值并没有直接的物理意义,主要用于区分数据的不同特征和结构。其值的大小和方向没有具体的解释,而是代表数据在这个降维后的空间中的位置。
-
t-SNE Component 2:
- 同样,这个坐标轴代表t-SNE生成的第二个维度。它是经过优化的,旨在最大化在低维空间中保留高维数据的局部结构。
- 该轴的值也没有直接的物理意义,而是表示样本在降维后的空间中的另一位置。
降维美团外卖评价词条
数据
数据来源于学校提供的上机课实验数据,由于太多,只罗列展示部分。
raw.txt(部分)
味道
可口
递给
力
味道
很棒
送餐
及时
今天
师傅
是不是
手抖
微辣
格外
送餐
态度
特别
辛苦
啦
谢谢
超级
送到
这么
冷
天气
骑士
辛苦
谢谢你们
麻辣
香锅
依然
好吃
经过
上次
小时
这次
超级
分钟
送到
最后
五分钟
卖家
特别
接单
谢谢
好吃
每次
够吃
两次
挺辣
可以
味道
送餐
分量
足
量足
好吃
送餐
特别
好吃
特大
而且
送餐
特别
特别
特别
棒
口感
速度
相当
好吃
香锅
分量
够
足
味道
好吃
速度
包装
品质
家门
餐厅
味道
味道
好极
啦data.txt(部分)
label,review
1,很快,好吃,味道足,量大
1,没有送水没有送水没有送水
1,非常快,态度好。
1,方便,快捷,味道可口,快递给力
1,菜味道很棒!送餐很及时!
1,今天师傅是不是手抖了,微辣格外辣!
1,"送餐快,态度也特别好,辛苦啦谢谢"
1,超级快就送到了,这么冷的天气骑士们辛苦了。谢谢你们。麻辣香锅依然很好吃。
1,经过上次晚了2小时,这次超级快,20分钟就送到了……
1,最后五分钟订的,卖家特别好接单了,谢谢。
1,量大,好吃,每次点的都够吃两次
1,挺辣的,吃着还可以吧
1,味道好,送餐快,分量足
1,量足,好吃,送餐也快
1,特别好吃,量特大,而且送餐特别快,特别特别棒
1,口感好的很,速度快!
1,相当好吃的香锅,分量够足,味道也没的说。
1,好吃!速度!包装也有品质,不出家门就能吃到餐厅的味道!
1,味道好极啦,送餐很快师傅辛苦啦
1,量大味道好,送餐师傅都很好
1,送餐师傅很好,味道好极啦
1,送货速度很快,一直定这家,赞
1,很方便,很快就送到了。棒
1,好吃,总点,这么多够五个人吃。送的很快。
1,"很香很美味,下次还会光顾"
1,"送餐特别快,态度也好,辛苦啦"
1,服务很不错,送到的很快,半小时不到就送来了
1,速度很快,大雾霾天外卖骑士态度都很好,赞赞赞!
1,味道正宗,量大内容多
1,"送餐非常快,态度特别好,谢谢"
1,又快又好,量足,经常吃
1,好大一盆点了7个小份量足
1,配送人员态度好,速度快!
1,"在这种天气里感谢送餐员的辛苦服务,谢谢啦"
1,"送餐特别快,态度好,非常感谢"
1,送的非常快,包装好!谢谢师傅!
1,附近最好吃的麻辣香锅,不开玩笑的
1,味道不错,份量很足,建议都点小份。红薯超好吃就是太烂了容易碎
1,还不错,就是稍微咸了点
1,这么晚辛苦外卖小哥了
1,超级快就送到了,谢谢骑士很快,感谢骑士这种天气还在工作!
1,非常好吃,味道也很香,推荐!
1,"很好吃,速递快,下次继续选择"
1,很快,特别好
1,太麻了,青笋有点小,米饭给的也不多,土豆片都碎了,找不到了
1,点了太多次了,味道很香
1,"态度很好,地址填错了还是给我跑了一趟,没有表现出不愿意的样子,为了这个快递员,我写了评论"
1,快递小哥很快就送到了!赞!水煮牛肉肉质鲜嫩,辣的恰到好处,也很入味。不错,挺好吃的!
1,"口味,不错,干净味道好,送货员服务非常好!"
1,"送餐特别快,态度好,辛苦啦,谢谢"
1,"送餐快,送餐大哥态度好,辛苦啦"
1,"送餐很快,态度也很好,谢谢"
1,挺不错的!
1,快递大叔人特别好。就是百度外卖现在连个优惠都那个少,真要投奔饿了么了。。。。
1,感觉没有在店里的好吃,感谢送餐师傅我们家六楼没电梯还得爬楼梯
1,菜场好,挺好吃的
1,快递小哥辛苦了!下雨天的真是辛苦您了!给你点赞!
1,相当好!送餐快,一大盒子超好吃!
1,"送餐特别快,送餐员态度也特别好"
1,速度快,量多,很香
1,味道很正点!餐具很好用!送餐速度快!
1,鱼豆腐有异味儿,有点腻。
1,非常好!第一次用百度外卖,送餐很快,快递小哥也很礼貌。菜品量足,味道不错,下次再来。
1,味道不错!
1,东西还可以,但是没有在店里吃的好吃
1,锅底怎么是13?
1,"很香,很好吃"
1,"很好,送餐员也很好"
1,菜量给的挺足的,很满意,就是墨鱼丸不太好,有股臭味,其他都很好吃。
0,虽然我定的很便宜,但是能不能菜多点,90的米饭,10的菜,我也是醉了。
0,点过好几次宇宙卷饼了~这次送的是最快的,本来很开森,但是送餐小哥打电话那个态度~我也是醉了
0,送餐太慢。不是一般的慢。11:04下的单,最后13:20才给送到!客户端催单三次没反应,打电话给商家打了两次,光送餐员(177xxxx0056)打电话就打了三次,最开始地点还给送错了!我又告诉他了地点在哪最后才给送到。这时候给送来了都开始上班了,没时间吃饭。强烈不满!!!看在送餐员岁数不大,一直在说对不起的份上,我还是把中间几位数字隐藏了。
0,上次到了打电话,这次送到了不打电话,害我一直等!!
0,肘子的那个吃后拉肚子了,孜然肌肉的还不错
0,送餐少送了粥隔了俩小时给我打电话说再送来
0,这送的也太慢了,来了之后基本都是凉的,学校离着五道口几百米,还这么慢,1个多小时啊!感觉不会再爱了。
0,再也不要点这家店了。。点的粥没有送到,但是把钱拿走了,送餐员说稍后给打电话解决,可是也没联系我,电话也不接。。。必须差评
0,"慢的不行,就是慢,绝对不黑,贼难吃,等了将近2小时,好吃也行啊"
0,一个字,慢
0,这是从宇宙送来的,快递太慢,6点39下单,马上八点才到
0,太他妈的慢了
0,太TM慢了
0,两个小时还不送过来,最后也不通知我就不送了,没有碰见这么不负责任的商家
0,"很慢,肉不少,饼不好吃"
0,等太久了,而且漏送了一瓶王老吉~~
0,一般,除了包装好看真的没什么了
0,送的挺快,半小时吧就到了,但是味道不太好吃
0,偶尔吃一次还可以
0,送饭速度太慢
0,"差劲的很啊,少送不说,,还强制消费。。。想退款,很麻烦的"
0,第一次在百度外卖上给差评。两个小时左右才送到。而且不好吃。
0,一点酱汁都没有,鸡肉还有浓浓的焦糊味!
0,差评,接单两个多小时没有送餐,打电话也没人接听,更无法取消订单,至今没有给予回复,这是订宵夜的节奏,送来带着锡纸都凉透了,你们都是只上夜班的吗?骗子!!!
0,卷饼和粥送到都已经凉透了
0,"口感一般,卷饼有些硬"
0,等了2个多小时才送来,送来还都是凉的,差评
0,"中分饼根本吃不饱,何况不好吃……,送餐太慢……"
0,等了2个小时15,让我去一楼取,等了10分钟,也打不通电话,看不见人,都一点半了送过来,还让我下楼去取!以后坚决不定
0,服务态度太差了,找不到地方还骂人,挂我电话。建议换一个靠谱点的小哥
0,"卷饼两端面太厚了,盖饭米饭太软了,配送员明知道我在6层,要求我去4层取餐"
0,这破天气我也理解,但是这速度真的都凉了。。。味道一般
0,"太差劲了,等了一晚上也没送到,期间打了四个电话,店家承诺取消订单,最终也没取消,最后店家居然确认订单完成了,太差劲了"
0,菜难吃,送餐员态度极差,送不好餐回家种田去,别在这丢人
0,等了2个多小时,打电话取消了两次,后来又送来了,真是无语了!饼是粘的,不好吃
0,要了粥,没勺子怎么喝?
0,卷饼味道一般,粥难吃
0,不好吃还是不好吃,都是肥肉
0,"皮蛋瘦肉粥不咋地。,送餐大叔虽然很热情,但是跟他说从六七号电梯上来,说半天也说不明白"
0,饼都泡的都裂开馅儿全部出来了,两个半小时才送到,
0,尼玛,送了三个小时
0,送餐速度慢,口味一般!
0,又贵又不好吃,送的还慢,一个半小时,真是够了~…
0,这确定还是以前大美女老板开的那家店麽?饼没完全熟,和以前的饼也不一样,肉就更别提了,块儿大的要死,还很难吃,从前的飘香肘子相当好吃啊~给一星是因为没有办法给零星,真的,差到爆!!!!!
0,太慢了,再也不会订了
0,"快两个小时收到,定的牛肉的,牛肉没有给其他的,以后不定了,不好吃"
0,第一,11点下单12点半送到,偏慢。快递一个劲儿道歉,让我有愧疚感。第二,卷饼味道不错,但是漏油啦,要的鱼香肉丝的,吃完才意识到送的手套是干啥用的。怪我。
0,等了两小时,都饿过头了
0,皮蛋瘦肉粥里没有皮蛋和瘦肉
0,预计配送时间是九十分钟,实际两个小时
0,以后送饭的能不能到了再打电话?特么每次接到电话下去得等5分钟以上是什么意思?
0,这是我吃过的全宇宙最难吃的卷饼,没有之一,而且送餐很慢,后会无期了您呐
0,"肥肉太多!送餐太慢,不会订了"
0,不管口味如何,送了两个多小时,不骂街我已经是素质好了
0,垃圾,接单配送慢的要死
0,连取消都取消不了,电话也不接,是店家垃圾还是百度服务跟不上?人家美团投诉了还有个回复,你们呢?垃圾啊店家更是垃圾中的垃圾,大家不要订了,等待不起啊
0,送货超慢,已经都凉透了,饼硬的不行。
0,晕了都,让12点送过来,你这10.50多就送过来了,让我情何以堪
0,不是肘子肉吧,而且送来的都是凉
0,很一般,卷饼是死面的,较厚,吃不惯
0,今天定的这个纯素的口味不太好,里头放了豆瓣酱还是什么的太浓了,有点发苦。。送餐时间太长,一共用了1个半小时多。皮蛋粥还不错。
0,等了100多分钟,送来的时候我都快饿晕了。。。。。
0,送餐特别特的慢!
0,等到快8点,南瓜粥是凉的,卷饼也是凉的!
0,配送竟然只送到1层,什么服务。。。太差了,以后不会再点了
0,"坦白说没什么味道,就是肉和饼"
0,送的有点慢,味道很好!
0,味道很不好,都凉了,饼都没有熟,肉也没有味道,跟在店里吃的差远了
0,皮蛋瘦肉粥和汇源果汁没送,投诉了也没用哈,然后让我跑18层楼下去拿外卖,是你送还是我送?要不剩下的我都帮你送了吧!
0,"完全不值这个价,一个素菜卷饼15,里面就两根土豆几块洋葱,饼倒是挺大。,再也不来了"
0,宇宙最慢的卷饼
0,有点咸,包装好于食物
0,下楼自己取,每次都是自己去拿,我要是有那时间就不叫外卖了代码
word2vec.py
# -*- coding: utf-8 -*-
import jieba
import re
import numpy as np
from gensim.models import word2vec
from collections import Counter
lines =[]
words =[]
counter = Counter()
target = open(r'./raw.txt', 'w+', encoding='utf-8')
for line in open(r'./data.txt', encoding='utf-8', errors='ignore'):
sentence = line
for x in jieba.cut(sentence):
words.append(x)
counter.update(x)
for word in words:
fl=0
for char in word:
if not '\u4e00' <= char <= '\u9fff':
fl = 1
if counter[word] < 300 and fl == 0:
print(word, file=target)
target.close()
# 用于存储分词结果
segments = []
print("前20行分词结果")
for line_num, line in enumerate(open(r'./data.txt', 'r', encoding='utf-8', errors='ignore')):
label, data = line.split()
data = jieba.lcut(data)
segments.append(data)
print(data)
if line_num == 9:
break
counter = Counter()
for seg in segments:
seg = [re.sub(r'[^\w\s]', '', word) for word in seg] # 去除标点符号
seg = [word for word in seg if word.strip()] # 去除空格
counter.update(seg)
print("前20最高频词频统计及其对应的特征向量")
for i, (word, count) in enumerate(counter.most_common(20)):
array = np.zeros(20, dtype=int)
array[i] = 1
print(f"{word}: {count}: {array}")
num_features = 20 # Word vector dimensionality
min_word_count = 100 # Minimum word count
num_workers = 16 # Number of threads to run in parallel
context = 10 # Context window size
downsampling = 1e-3 # Downsample setting for frequent words
sentences = word2vec.Text8Corpus(r'./raw.txt')
EMBEDDING_FILENAME = r"./embeddings_allcorpous.emb"
EMBEDDING_MODEL_FILENAME = r'./embeddings.model'
model = word2vec.Word2Vec(sentences, workers=num_workers,
vector_size=num_features, min_count=min_word_count,
window=context, sg=1, sample=downsampling)
# Save embeddings for later use
model.wv.save_word2vec_format(EMBEDDING_FILENAME)
# Save model for later use
model.save(EMBEDDING_MODEL_FILENAME)visual+tsne.py
# -*- coding: utf-8 -*-
import numpy as np
from matplotlib import pyplot
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
path = "./embeddings_allcorpous.emb"
label_list = []
vec_list = []
with open(path, encoding="utf-8") as file:
for line in file.readlines():
line = line.strip()
line = line.split()
label_list.append(line[0])
vec_list.append(list(map(float, line[1:])))
label_array = np.array(label_list)
vec_array = np.array(vec_list)
tsne = TSNE()
X_embedded = tsne.fit_transform(vec_array)
# 可视化展示
pyplot.scatter(X_embedded[:, 0], X_embedded[:, 1])
for i, word in enumerate(label_array):
pyplot.annotate(word, xy=(X_embedded[i, 0], X_embedded[i, 1]))
pyplot.show() 结果
分词结果、词频统计、词向量
在词频统计时,去除了标点符号。

embedding.emb

t-sne可视化

原始数据太多了,已经能看出t-sne降维后的数据是有原先数据集中的结构特征(即可理解为聚类效果)的,接下来选取一部分数据再次实验,可得下图:

可以明显看到左上角是差评区域,右下角是好评区域。
降维微博账号关系(图节点)
数据
数据来源于学校提供的上机课实验数据,由于太多,只罗列展示部分。
NLPIR微博关注关系语料库.xml(部分)
<?xml version="1.0" standalone="yes"?>
<RECORDS>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>10029</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>10318</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>1003716184</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>1005991591</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>1007343817</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>1013487233</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>1015954874</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>1032026532</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>1037697440</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>1044454315</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>1049723185</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>1052813963</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>1053799747</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>1055384231</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>1058676987</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>1059500987</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>1062596504</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>1066559153</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>1072186511</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>1074474512</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>1075216644</guanzhu_id>
</RECORD>
<RECORD>
<person_id>10145</person_id>
<guanzhu_id>1087475905</guanzhu_id>
</RECORD>代码
node2vec+tsne+visual.py
# -*- coding: utf-8 -*-
import networkx as nx
from node2vec import Node2Vec
import numpy as np
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import networkx as nx
import xml.etree.ElementTree as ET
# 读取 XML 文件
tree = ET.parse(r"./NLPIR微博关注关系语料库.xml")
root = tree.getroot()
G = nx.DiGraph() # 创建一个新的有向图
for record in root.findall('RECORD'):
person_id = record.find('person_id').text
guanzhu_id = record.find('guanzhu_id').text
G.add_edge(person_id, guanzhu_id) # 遍历 XML 数据并添加边到图中
node2vec = Node2Vec(G, dimensions=64, walk_length=30, num_walks=200, workers=4) # 初始化Node2Vec模型
model = node2vec.fit(window=10, min_count=1, batch_words=4) # 训练模型
# 获取结点表示
node_representations = np.array([model.wv[node] for node in G.nodes()])
tsne = TSNE(n_components=2, perplexity=30, random_state=42)
node_embeddings_2d = tsne.fit_transform(node_representations)
# 绘制可视化图形
plt.figure(figsize=(10, 8))
plt.scatter(node_embeddings_2d[:, 0], node_embeddings_2d[:, 1])
plt.show()以 XML 格式存储的,而不是常规的图的边列表格式。为了处理这样的数据,要首先解析 XML 文件,然后将其转换为图的边列表格式,然后再用 NetworkX 创建图数据结构。
流形学习(Manifold Learning)
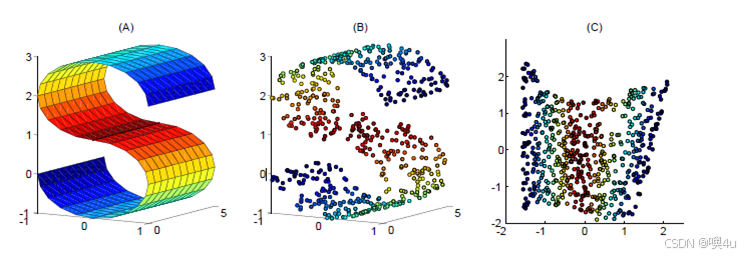
流形学习是一类非线性降维技术,目的是发现高维数据中的低维结构。它的核心思想是:许多高维数据(比如图像、文本)实际是由少数几个隐含变量控制的,这些变量构成一个低维流形嵌入在高维空间中。
- 流形是“局部平直”的抽象空间,而流形学习旨在解开高维数据中隐藏的低维流形结构。它弥补了线性方法的不足,更适合处理现实中的复杂非线性数据。
- 流形是数学中的一个概念,可以简单理解为“局部看起来像欧几里得空间(如平面、三维空间)的复杂形状”。举个例子:
- 地球表面:虽然地球是一个球体(整体弯曲),但如果你站在地面上,周围的一小片区域看起来就像平面(局部像二维空间)。这就是一个二维流形。
- 瑞士卷:一种卷曲的三维形状,但实际可以用二维参数描述(类似展开的纸)。
- 流形的核心特点是:在局部范围内,可以用简单的坐标系(如直线、平面)来描述,但全局可能是弯曲或缠绕的。
PCA不属于流形学习,但可视为流形学习的一个特例(如果数据的流形是一个线性子空间)。
多维缩放(MDS, Multidimensional Scaling)
多维缩放(MDS)是一种降维技术,其核心目标是:将高维空间中的数据点映射到低维(如2D或3D),同时尽量保持数据点之间的“距离”关系。
- 低维空间中的点间距离 ≈ 原始高维空间中的点间距离
这样,我们就能在平面上或三维空间中直观地观察数据的结构(如聚类、分布等)。它适用于数据可视化、模式识别和探索性数据分析。
- 输入:一个距离矩阵 D,其中 Dij 表示点 i 和点 j 的距离(如欧氏距离)。
- 目标:找到低维坐标 X,使得 ∥xi−xj∥≈Dij。
关键步骤:
- 计算距离矩阵 D(如果原始数据是特征向量,先计算欧氏距离)。
- 计算双中心化矩阵 B(使得距离信息转化为内积信息)。
- 对 B 进行特征分解,取前 k 个最大特征值及其特征向量,得到低维坐标 X。
适用场景:数据距离是欧氏距离,且希望保持全局结构。
from sklearn.manifold import MDS
import numpy as np
# 假设我们有4个样本,计算它们的欧氏距离矩阵
distance_matrix = np.array([
[0, 1, 2, 3],
[1, 0, 1, 2],
[2, 1, 0, 1],
[3, 2, 1, 0]
])
# 使用 MDS 降维到 2D
mds = MDS(n_components=2, dissimilarity='precomputed')
low_dim_data = mds.fit_transform(distance_matrix)
print("2D 坐标:\n", low_dim_data)等度量映射(Isomap, Isometric Mapping)
核心思想是:在高维数据中,保持数据点之间的“测地距离”(Geodesic Distance,即流形上的真实距离),而不是欧氏距离(直线距离),从而在低维空间中更准确地反映数据的本质结构。
Isomap的改进:
- 假设数据位于一个低维流形上,计算流形上的真实距离(测地距离)。
- 通过保持测地距离,将数据映射到低维空间。

局部线性嵌入(LLE, Locally Linear Embedding)
其核心假设是:数据在局部邻域内是线性的,即每个数据点可以由其近邻点的线性组合重构。降维时,保持这种局部线性关系不变,从而在低维空间中反映数据的全局非线性结构。
关键特点:
- 保持局部几何:不依赖全局距离(如Isomap的测地距离),而是通过局部线性拼接表示流形。
- 高效计算:仅需求解稀疏矩阵的特征问题,适合中等规模数据。

变体方法
- Hessian LLE:适用于具有孔洞的流形。
- Modified LLE:改进权重计算,增强稳定性。
- LTSA(Local Tangent Space Alignment):基于局部切空间对齐。
选择建议
- 数据局部线性明显 → LLE
- 需保持全局距离 → Isomap
- 侧重可视化聚类 → t-SNE
from sklearn.manifold import Isomap, TSNE, LocallyLinearEmbedding
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
from sklearn.datasets import make_swiss_roll
from mpl_toolkits.mplot3d import Axes3D
import time
import numpy as np
# 生成瑞士卷数据(为LDA生成伪标签,模拟分类场景)
X, color = make_swiss_roll(n_samples=1000, noise=0.1, random_state=42)
y = np.floor(color / 10).astype(int) # 创建4个伪类别
# 创建画布(2行3列)
fig = plt.figure(figsize=(18, 12))
# 子图1:原始3D数据
ax1 = fig.add_subplot(231, projection='3d')
sc1 = ax1.scatter(X[:, 0], X[:, 1], X[:, 2], c=color, cmap='viridis', s=10)
ax1.set_title("Original Swiss Roll (3D)")
ax1.set_xlabel("X")
ax1.set_ylabel("Y")
ax1.set_zlabel("Z")
plt.colorbar(sc1, ax=ax1, label='Manifold Parameter')
# 使用PCA降维到2D
start_time = time.time()
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
pca_time = time.time() - start_time
# 子图2:PCA降维结果
ax2 = fig.add_subplot(233)
sc2 = ax2.scatter(X_pca[:, 0], X_pca[:, 1], c=color, cmap='viridis')
ax2.set_title(f"PCA Projection\n(time: {pca_time:.2f}s)")
ax2.set_xlabel("PC1")
ax2.set_ylabel("PC2")
# 使用Isomap降维到2D
start_time = time.time()
isomap = Isomap(n_neighbors=10, n_components=2)
X_isomap = isomap.fit_transform(X)
isomap_time = time.time() - start_time
# 子图4:Isomap降维结果
ax4 = fig.add_subplot(234)
sc4 = ax4.scatter(X_isomap[:, 0], X_isomap[:, 1], c=color, cmap='viridis')
ax4.set_title(f"Isomap Projection\n(time: {isomap_time:.2f}s)")
ax4.set_xlabel("Component 1")
ax4.set_ylabel("Component 2")
# 使用LLE降维到2D
start_time = time.time()
lle = LocallyLinearEmbedding(n_neighbors=12, n_components=2, method='standard')
X_lle = lle.fit_transform(X)
lle_time = time.time() - start_time
# 子图5:LLE降维结果
ax5 = fig.add_subplot(235)
sc5 = ax5.scatter(X_lle[:, 0], X_lle[:, 1], c=color, cmap='viridis')
ax5.set_title(f"LLE Projection\n(time: {lle_time:.2f}s)")
ax5.set_xlabel("LLE1")
ax5.set_ylabel("LLE2")
# 使用t-SNE降维到2D
start_time = time.time()
tsne = TSNE(n_components=2, perplexity=30, random_state=42)
X_tsne = tsne.fit_transform(X)
tsne_time = time.time() - start_time
# 子图6:t-SNE降维结果
ax6 = fig.add_subplot(236)
sc6 = ax6.scatter(X_tsne[:, 0], X_tsne[:, 1], c=color, cmap='viridis')
ax6.set_title(f"t-SNE Projection\n(time: {tsne_time:.2f}s)")
ax6.set_xlabel("t-SNE1")
ax6.set_ylabel("t-SNE2")
plt.tight_layout()
plt.show()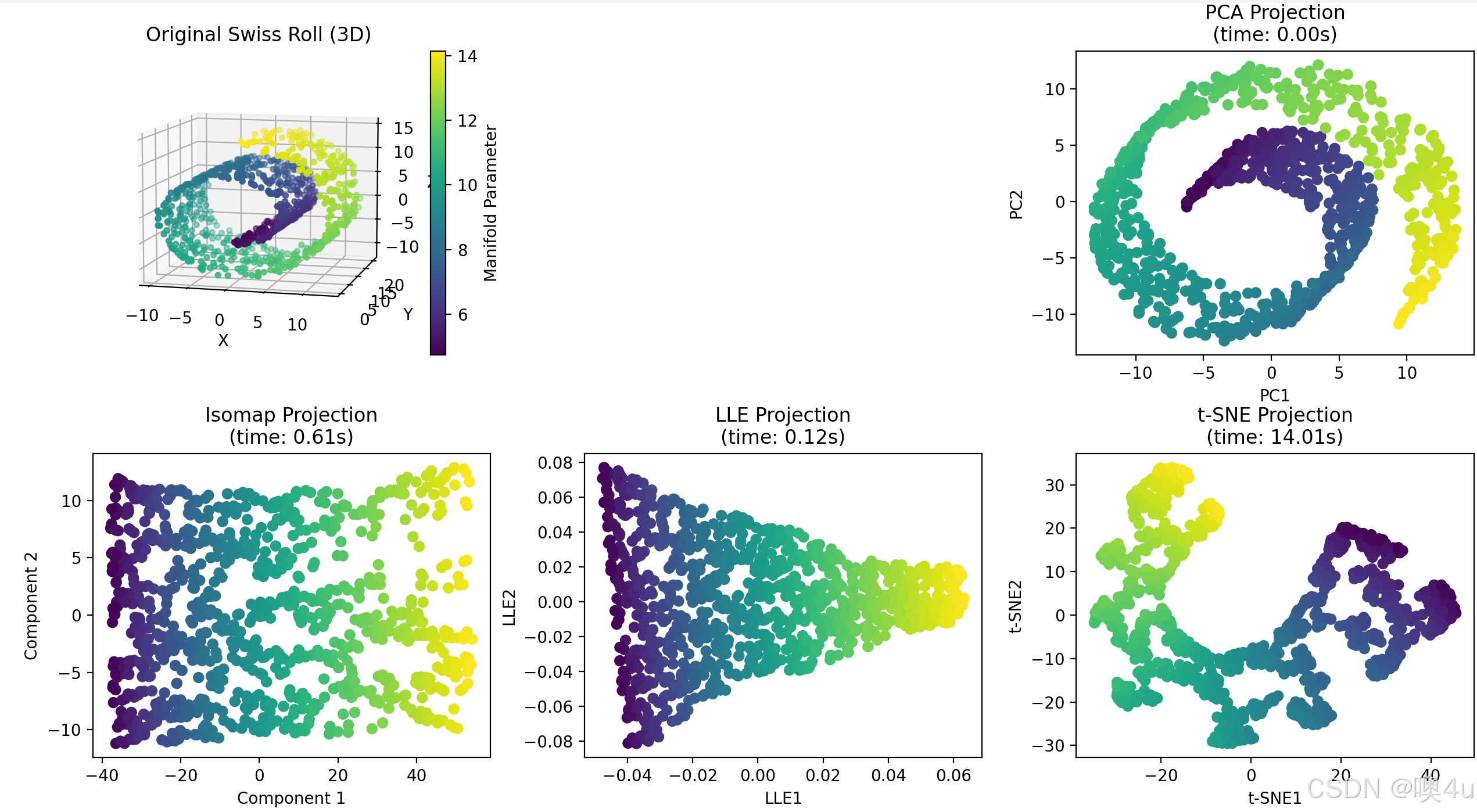
总结
这篇文章简要介绍了几种常见的降维方法,包括主成分分析(PCA)、线性判别分析(LDA)、t-SNE和独立成分分析(ICA)。这些技术在数据科学和机器学习中广泛应用,旨在降低数据维度的同时保留关键信息。通过不同的算法,它们各自适用于不同的场景,帮助我们在复杂的高维数据中提取有用的特征,简化数据处理和可视化过程。

















 1401
1401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









