









在本专栏的之前的博文中,已经有对常用的灰度变换和区域生长算法做具体介绍。
前言
图像分割在图像处理和计算机视觉领域中起着关键作用,能够有效地从图像中提取出目标区域,进而为目标识别、检测等下游任务提供基础。图像区域提取和分割在多个领域中具有广泛的应用,尤其是在遥感(RS)和医学影像中发挥着关键作用。在遥感领域,图像分割技术被用于从卫星或无人机图像中自动提取地物,如建筑物、道路、植被和水体等。这些提取结果有助于进行土地利用分类、灾害监测以及城市扩张分析等任务。在医学影像处理中,图像分割是识别和提取器官、肿瘤或病灶区域的核心技术,常用于CT、MRI等扫描图像的分析。通过精确分割器官或病变区域,医生可以更好地进行疾病诊断、治疗规划和手术导航。此外,分割技术还能够提高计算机辅助诊断(CAD)系统的精度,从而辅助医疗决策。因此,图像分割作为基础技术,极大地推动了多个专业领域的自动化和智能化进程。
本文提出了一种基于标准差动态调整的高斯模糊核以及KMeans聚类选取种子点的自适应边缘引导区域生长算法。该方法能够根据图像的纹理特征,自动调整模糊核大小和灰度差异阈值,结合边缘检测与聚类算法实现准确的图像分割。本文将详细介绍该算法的工作流程、相关公式及实验结果。
相关研究
目前,图像分割技术包括基于阈值、边缘检测、区域生长、聚类及深度学习的多种方法。Canny边缘检测【1】是一种常用的边缘检测算法,通过高斯模糊、双阈值筛选以及边缘连接实现图像中的重要特征检测。而区域生长算法则基于像素灰度差异来扩展区域,实现图像分割【2】。此外,KMeans聚类【3】常用于减少种子点的数量,使得区域生长算法更加高效。尽管现有方法能够在特定场景下取得较好的效果,但如何结合图像特征自适应调整分割参数,仍然是一个值得探索的问题。
方法
对于一些纹理图案较为复杂的图片,简单的根据灰度划分会有较大的误差,但过于复杂的算法又会导致运行速度过慢。故本文使用了将预处理增强后的图像使用高斯模糊核、边缘检测与动态阈值、基于KMeans的种子点筛选、并使用自适应边缘引导的区域并行化生长的方法,使得对于复杂图片区域的提取和运行效率有了折中的提高,同时结合通常的数字图像处理技术与机器学习算法中的kmeans技术,体现了学科不断融合发展的趋势。
图像预处理
将图像转为灰度图
为了简化图像处理过程,首先将彩色图像转换为灰度图。灰度图像可以保留足够的亮度信息,同时降低计算复杂度。转换公式为【4】:![]()
直方图均衡化
对灰度图进行直方图均衡化以增强对比度,增加图像的细节和可见性。直方图均衡化的目标是将图像的灰度级分布调整为更加均匀的状态,具体公式为:
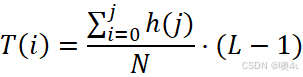
其中,![]() 是灰度级 j 处的像素个数,N 是图像的总像素数,L 是灰度级的最大值。
是灰度级 j 处的像素个数,N 是图像的总像素数,L 是灰度级的最大值。
高斯模糊核的动态调整
在图像处理和分割过程中,模糊操作是一种常用的预处理技术,旨在减少噪声、平滑纹理,并使边缘更易于检测。然而,对于不同复杂度的图像,使用固定大小的模糊核往往无法达到理想的效果。因此,本文提出了根据图像的标准差动态调整模糊核大小的方法。该方法的核心思想是:图像的标准差反映了其灰度变化的程度,即图像的纹理复杂度或噪声水平。标准差越大,意味着图像中存在更多的细节、纹理和噪声,因此需要较大的模糊核来平滑这些复杂结构。相反,如果标准差较小,则表明图像较为平滑,细节较少,使用较小的模糊核即可。动态调整模糊核大小的公式为:
![]()
其中,![]() 是最小核大小,σ是图像的标准差,s 是缩放因子,用来动态调整模糊核的大小。为了保证核大小为奇数,若结果为偶数则加1。
是最小核大小,σ是图像的标准差,s 是缩放因子,用来动态调整模糊核的大小。为了保证核大小为奇数,若结果为偶数则加1。
这种根据标准差调整模糊核大小的方式有几个显著优势。首先,它能够自适应不同类型的图像,使得处理复杂纹理图像时能够有效平滑噪声,而在平滑图像时又不会过度模糊,保留关键边缘。其次,动态模糊核的使用能够避免手动调整核大小,增加了算法的鲁棒性和自动化程度。在图像分割任务中,合适的模糊核能够提高边缘检测的精度,使得后续的分割算法更加准确和高效。因此,这种自适应调整模糊核的方法在处理具有不同复杂度和噪声水平的图像时表现出更好的分割效果。
边缘检测与动态阈值
为了进一步提取图像中的边缘信息,采用Canny边缘检测。为了使边缘检测更加自适应,阈值根据图像灰度直方图的分布动态设定。低阈值取图像灰度的5%分位值,高阈值取95%分位值。
Harris角点检测及其在种子点选择中的应用
Harris角点检测是一种经典的图像特征检测算法【5】,用于检测图像中的角点等显著特征。角点是指图像中局部具有显著变化的像素点,通常代表着图像中的重要结构,如物体的边角或交汇点。Harris角点检测方法通过分析图像局部窗口的灰度变化,判断该窗口是否包含角点。
其核心思想是,当局部窗口沿不同方向移动时,角点区域的灰度值变化将会非常显著。因此,通过分析每个像素点的邻域窗口,能够确定角点的位置。其数学表达式如下:
![]()
其中,M 为自相关矩阵,用来描述局部窗口的灰度变化,定义为:
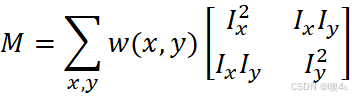
这里,![]() 和
和 ![]() 是图像在水平方向和垂直方向上的梯度,w(x,y) 是窗口函数,通常取为高斯函数。参数 k 是经验参数,通常取值在 0.04 到 0.06 之间。当 R 值较大时,表示该像素点附近是角点。
是图像在水平方向和垂直方向上的梯度,w(x,y) 是窗口函数,通常取为高斯函数。参数 k 是经验参数,通常取值在 0.04 到 0.06 之间。当 R 值较大时,表示该像素点附近是角点。
在图像区域分割中,Harris角点检测可用于自动选择初始种子点。种子点是区域生长算法的起点,通过选择图像中的角点作为种子点,可以确保区域生长过程能够从图像的关键结构区域开始。利用Harris角点检测方法可以自动从图像中检测出一组显著的角点,这些角点往往位于物体的边界或交汇点,能够有效地指导区域生长算法进行图像分割。
在本文提出的分割方法中,我们使用Harris角点检测从灰度图像中提取角点,作为区域生长的种子点。提取出的种子点经过KMeans聚类进一步筛选和精简,最终用于指导自适应的区域生长。该方法通过自动化角点检测,减少了人工选择种子点的复杂性,并提高了分割的自动化程度。
基于KMeans的种子点筛选
为了减少区域生长的计算量,本文使用Harris角点检测自动选取种子点,并结合KMeans聚类对种子点进行筛选,减少了人工选择的初始误差和影响。聚类中心作为新的种子点,数量根据标准差动态确定,公式为:
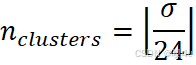
其中,σ为图像标准差。
自适应边缘引导的区域生长
区域生长(Region Growing)是一种经典的图像分割方法,其主要思想是通过从一个或多个种子点出发,逐步将具有相似特征的像素归入同一个区域,直到生长条件不再满足为止。区域生长基于像素之间的相似性,通常是灰度值、颜色或纹理等。通过分析像素之间的差异性,区域生长可以有效地将图像划分为若干个连通且均匀的区域。区域生长的主要优势在于,它能够自适应图像中的局部特征,从种子点扩展生成的区域可以精准地覆盖到边界复杂的物体上。
区域生长的核心在于基于灰度差异扩展区域。设初始种子点灰度值为![]() ,局部窗口内的标准差为
,局部窗口内的标准差为![]() ,则生长过程中每个像素的灰度差异阈值为:
,则生长过程中每个像素的灰度差异阈值为:
![]()
其中,![]() 是基础灰度差异阈值。对于每个种子点,若满足灰度差异小于等于该阈值且未被边缘检测标记,则加入生长队列。
是基础灰度差异阈值。对于每个种子点,若满足灰度差异小于等于该阈值且未被边缘检测标记,则加入生长队列。
在本文的方法中,所用的区域生长函数是自适应边缘引导的区域生长。这种方法结合了边缘检测与区域生长的思想,确保区域生长过程不仅依赖像素的灰度差异,还受到边缘信息的约束。具体来说,区域生长从角点检测到的种子点开始,依据每个像素与种子点像素的灰度差异决定是否将该像素加入生长区域。同时,为了提高精度,生长过程中引入了局部灰度差异的动态阈值。该阈值基于局部窗口内的灰度标准差动态调整,以确保在不同的图像区域内能够自适应调整扩展条件。例如,纹理复杂的区域阈值会自动增大,以允许更大的灰度差异,而在平滑区域,阈值会较小,从而避免过度生长。
通过这种自适应的灰度差异控制,区域生长函数能够准确分割出具有复杂边界的图像区域。此外,边缘引导的特性也避免了区域生长越过显著边缘,使得分割结果更加精准、边界更加清晰。该方法尤其适用于具有复杂背景或纹理的图像,能够有效提高分割的准确性和鲁棒性。
并行化区域生长
为了加速处理,使用线程并行化多个种子点的区域生长。每个线程负责从一个种子点开始进行生长,最后将结果合并至一个掩码图像中。
数据实验
初始参数设定
- 基础模糊核大小:5
- 灰度差异基础阈值:50
- 局部窗口大小:5-20(根据图像尺寸动态调整)
本文基于学校课程资料中所给出的“图 2 Picture1-e1461332877269.jpg (500×500) (utexas.edu)”(下图)。实验中,本文方法应用于该图像中,验证了其在复杂纹理图像上的有效性。以下是部分实验结果。

结果
以下是经过增强后的图像: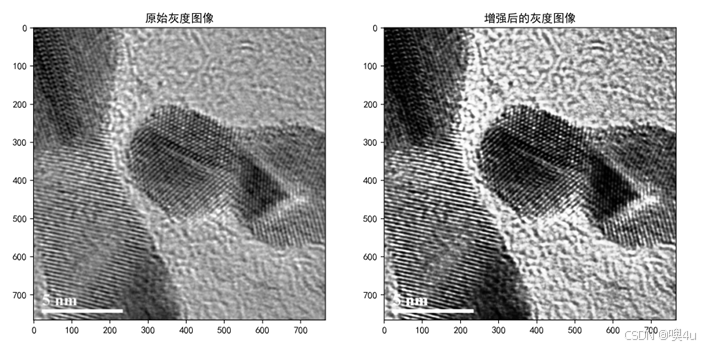
增强后的原图和直方图对比:
以下是运行过程中的参数:(图像的标准差、核大小、Canny阈值、种子点)
以下是输出的结果:
可以看到程序将肉眼可见的灰度值更大的地方与更小的地方分割开来了,且数值变化更大的地方红色越深,也可以理解为在灰度相近的地方按纹路也有所分割。
讨论
在本文提出的基于标准差自适应模糊核、KMeans聚类和边缘引导的区域生长方法中,我们成功实现了一种针对复杂图像自动进行区域分割的方案。该方法结合了图像标准差这一反映图像纹理和噪声水平的指标,动态调整模糊核的大小,从而自适应不同复杂度的图像;同时,KMeans聚类有效减少了种子点的数量,并通过Harris角点检测保证了这些种子点选取的合理性。这些创新点共同作用,使得本文方法能够在保留图像重要边界的前提下,平滑噪声、减少过度分割,并提高分割效率。
具体来说,利用图像标准差动态调整模糊核大小的策略极大地增强了该算法的鲁棒性。在图像分割任务中,传统的固定核大小的高斯模糊方法往往无法兼顾复杂纹理和简单背景。在复杂图像中,较小的模糊核会导致噪声无法平滑,而过大的核则可能模糊掉边界细节。而本文的自适应调整方法能够针对不同复杂度的区域,动态生成合适的模糊核大小,从而有效地平衡了噪声抑制与边缘保留的需求。这种自适应策略不仅减少了人工调参的复杂性,还大幅提高了算法的自动化水平,使其能够广泛应用于多种图像场景。
此外,KMeans聚类对种子点进行筛选和聚合的过程,也对区域生长的有效性起到了至关重要的作用。传统区域生长方法中,种子点的选择往往是一个人为或随机的过程,容易导致分割结果的不可控性。而通过角点检测和聚类技术的结合,本文方法在确保初始种子点选取合理性的同时,进一步通过聚类减少了种子点数量,从而使得生长区域更加均匀且能更有效地覆盖图像的关键结构。这不仅提高了分割精度,也减少了计算成本,使得该方法能够处理较大规模和复杂的图像。
然而,尽管本文提出的算法在实验中表现出较好的效果,但仍存在一些局限性和挑战需要在未来工作中进一步探讨。首先,虽然基于标准差动态调整模糊核大小能够较好地适应图像复杂度,但在某些极端场景下(例如,高度不均匀的噪声或强光干扰的图像),标准差可能不足以完全反映出图像的真实复杂性。因此,未来的研究可以考虑引入更多的图像特征指标(如局部纹理复杂度、颜色信息等)来进一步优化模糊核的调整策略。其次,该方法尤其依赖于种子点的初始化选择。尽管KMeans聚类有效减少了种子点数量、保障了其质量,但聚类中心可能并不总是落在具有最重要意义的区域。为此,可以考虑再结合其他相关技术,以进一步提升分割的准确性。此外,应尽可能不使用预设的初始参数,而是修改为普适性的自适应参数,或使用有严格依据的预设值,而非肉眼结果相对较好的值。
本方法在处理具有复杂纹理和噪声的图像时,能够自适应调整模糊核和阈值,提高分割的准确性。然而,由于该方法依赖于标准差,在图像对比度极低或过高时,可能会导致分割效果不佳。
结论
本文提出了一种基于标准差自适应调整模糊核大小、KMeans聚类种子点筛选、以及边缘引导区域生长的图像分割方法,成功实现了对复杂图像的高效分割。在图像处理领域,区域分割是许多高层次任务(如目标检测、图像识别)的基础,因此能够设计出自适应性强、分割精确的算法具有重要意义。本方法通过结合图像的局部统计特征(如标准差)以及角点检测与聚类技术,有效提高了分割的鲁棒性和自动化水平。
未来的工作可以围绕几个方向展开。一是引入更多的图像特征指标,进一步提升模糊核调整策略的灵活性和适应性。二是通过引入深度学习模型,实现更具理解能力的种子点选择,以提升分割效果。三是探索多线程并行计算的进一步优化,尤其是在处理超大规模图像时,使得算法能够在保证精度的前提下提升计算效率。此外,结合该方法与其他现代图像处理技术,如超分辨率重建、GAN生成图像增强等,可以为许多实际应用场景(如医学影像分析、卫星遥感图像处理、工业检测等)提供新的解决方案。
总的来说,本文的研究展示了传统图像分割方法与现代自适应技术结合的巨大潜力,尤其是在处理复杂场景和多样化图像时,本文方法展示了显著的优势和应用前景。随着未来更多先进技术的引入和优化,该方法有望在图像分割及其相关领域中发挥更大的作用,为智能图像分析的进一步发展提供坚实的技术基础。
参考文献
- [1] Canny, J. "A Computational Approach to Edge Detection." IEEE Transactions on Pattern Analysis and Machine Intelligence, 1986.
- [2] Adams, R., & Bischof, L. "Seeded Region Growing." IEEE Transactions on Pattern Analysis and Machine Intelligence, 1994.
- [3] MacQueen, J. "Some Methods for Classification and Analysis of Multivariate Observations." Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, 1967.
- [4] Gonzalez, R. C., & Woods, R. E. "Digital Image Processing." Pearson, 2008.
- [5] Mikolajczyk, K. & Schmid, C. "Scale & affine invariant interest point detectors." International Journal of Computer Vision, 2004, 60(1), 63-86.
代码附录
import cv2
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import threading
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
# 加载输入图像
input_image_path = r"\DIP\exp2\q2.png"
input_image = cv2.imread(input_image_path)
# 转换为灰度图像
gray_image = cv2.cvtColor(input_image, cv2.COLOR_BGR2GRAY)
# 绘制对比度增强前的直方图
hist_before_equalization = cv2.calcHist([gray_image], [0], None, [256], [0, 256])
# 直方图均衡化以增强对比度
equalized_image = cv2.equalizeHist(gray_image)
# 绘制对比度增强后的直方图
hist_after_equalization = cv2.calcHist([equalized_image], [0], None, [256], [0, 256])
# 计算图像的标准差来判断图像的纹理和噪声
mean, stddev = cv2.meanStdDev(equalized_image)
# 根据标准差动态调整模糊核大小,标准差越大,图像越复杂,需要较大的模糊核
def calculate_kernel_based_on_stddev(stddev):
base_kernel_size = 5 # 最小核大小
scale_factor = 1.2 # 调整因子
print("stddev",stddev[0][0])
kernel_size = base_kernel_size + int(stddev[0][0] * scale_factor)
# 核大小必须是奇数
if kernel_size % 2 == 0:
kernel_size += 1
return (kernel_size, kernel_size)
# 动态计算高斯模糊核大小
kernel_size = calculate_kernel_based_on_stddev(stddev)
print("gauseblur_kernel_size",kernel_size)
# 应用高斯模糊
blurred_image = cv2.GaussianBlur(equalized_image, kernel_size, 0)
# 直方图信息用于Canny阈值的动态调整
histogram = cv2.calcHist([gray_image], [0], None, [256], [0, 256])
low_threshold = np.percentile(histogram, 5) # 低阈值取较低的5%灰度 计算给定数据集(在这里是 histogram)的第 5 百分位数
high_threshold = np.percentile(histogram, 95) # 高阈值取较高的95%灰度
print("Canny_low;high",low_threshold, high_threshold)
# 使用自适应Canny边缘检测
edges = cv2.Canny(blurred_image, low_threshold, high_threshold)
# 自动选择种子点(使用Harris角点检测)
harris_corners = cv2.cornerHarris(gray_image, 2, 3, 0.04)
harris_corners = cv2.dilate(harris_corners, None)
threshold = 0.01 * harris_corners.max()
seed_points = np.argwhere(harris_corners > threshold) # 提取角点作为种子点
seed_points = [(y, x) for x, y in seed_points] # 格式转换为 (x, y)
# 基于KMeans聚类筛选种子点
def cluster_seed_points(seed_points, n_clusters=int(stddev[0][0]/24)):
# 将种子点转换为 numpy 数组
seed_points_array = np.array(seed_points)
# 使用 KMeans 聚类
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
kmeans.fit(seed_points_array)
# 聚类中心作为新的种子点
clustered_seed_points = kmeans.cluster_centers_.astype(int)
# 转换为 (x, y) 格式的种子点
return [tuple(point) for point in clustered_seed_points]
# 使用 KMeans 进行聚类,减少种子点的数量
filtered_seed_points = cluster_seed_points(seed_points, n_clusters=int(stddev[0][0]/24))
print("filtered_seed_points",filtered_seed_points)
# 初始化用于标记大区域的空掩码
region_mask = np.zeros_like(blurred_image, dtype=np.uint8)
# 根据图像尺寸自适应调整局部窗口大小
image_size = gray_image.shape[0] * gray_image.shape[1]
local_window_size = max(5, min(20, image_size // 50000)) # 根据图像大小调整窗口大小
# 设置基础灰度差异的阈值
base_gray_diff_threshold = 50
# 区域生长函数
def adaptive_edge_guided_region_grow(img, edges, seed, base_threshold, local_window_size, result_mask):
seed_value = img[seed]
queue = [seed]
while queue:
x, y = queue.pop(0)
if x < 0 or y < 0 or x >= img.shape[1] or y >= img.shape[0]:
continue
x_min, x_max = max(0, x - local_window_size), min(img.shape[1], x + local_window_size)
y_min, y_max = max(0, y - local_window_size), min(img.shape[0], y + local_window_size)
local_region = img[y_min:y_max, x_min:x_max]
local_std = np.std(local_region)
adaptive_threshold = base_threshold + local_std
if abs(int(img[y, x]) - int(seed_value)) <= adaptive_threshold and result_mask[y, x] == 0 and edges[y, x] == 0:
result_mask[y, x] = 255
queue.extend([(x+1, y), (x-1, y), (x, y+1), (x, y-1)])
# 并行处理多个种子点的区域生长
def parallel_region_growing(filtered_seed_points, blurred_image, edges, base_gray_diff_threshold, local_window_size, region_mask):
threads = []
for seed in filtered_seed_points:
thread = threading.Thread(target=adaptive_edge_guided_region_grow,
args=(blurred_image, edges, seed, base_gray_diff_threshold, local_window_size, region_mask))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
parallel_region_growing(filtered_seed_points, blurred_image, edges, base_gray_diff_threshold, local_window_size, region_mask)
# 查找区域的轮廓
contours, _ = cv2.findContours(region_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 创建用于绘制轮廓的图像
colored_contour_image = np.copy(input_image)
# 基于灰度差异的动态颜色映射
def calculate_color_based_on_stddev(stddev):
color_intensity = int(min(255, max(0, stddev * 5)))
return (255 - color_intensity, 0, color_intensity) # 蓝-红-深红
for contour in contours:
mask = np.zeros_like(gray_image)
cv2.drawContours(mask, [contour], -1, 255, thickness=-1)
mean_val, stddev_val = cv2.meanStdDev(gray_image, mask=mask)
contour_color = calculate_color_based_on_stddev(stddev_val[0][0])
cv2.drawContours(colored_contour_image, [contour], -1, contour_color, 2)
# 显示结果
# 显示原始图像和增强图像
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.imshow(cv2.cvtColor(gray_image, cv2.COLOR_BGR2RGB), cmap='gray')
plt.title("原始灰度图像")
plt.subplot(1, 2, 2)
plt.imshow(cv2.cvtColor(equalized_image, cv2.COLOR_BGR2RGB), cmap='gray')
plt.title("增强后的灰度图像")
plt.show()
# 显示直方图对比
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.plot(hist_before_equalization)
plt.title("增强前的直方图")
plt.subplot(1, 2, 2)
plt.plot(hist_after_equalization)
plt.title("增强后的直方图")
plt.show()
# 显示分割后的结果
plt.figure(figsize=(8, 8))
plt.imshow(cv2.cvtColor(colored_contour_image, cv2.COLOR_BGR2RGB))
plt.title("基于灰度变化的动态颜色区域分割")
plt.show()

















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









