







前文已经对crowdcountingp2p代码复现做了相关介绍,但是并没有完全跑通
前文链接:crowdcountingp2p代码复现_追忆苔上雪的博客-CSDN博客
书接上文,前面提到将标签图.mat格式改成.txt格式的时候,转换成的格式如图
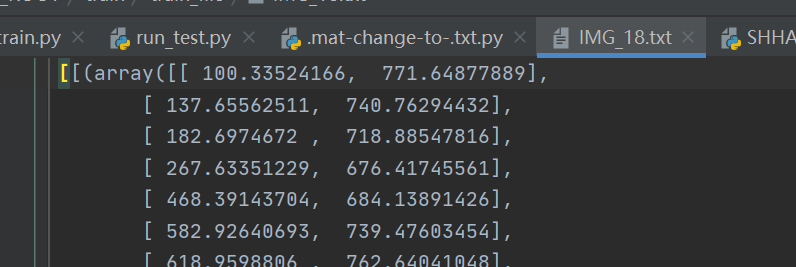
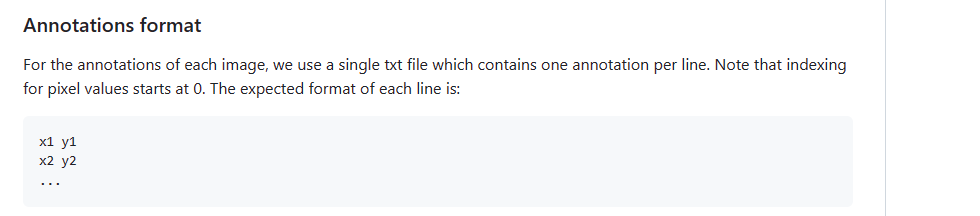
但是根据代码的readme文,txt文件中只需要坐标数据
于是需要进一步改进前面的代码
为了获取标签中的x和y数值,这里写了一个实验脚本
# 导入包
import scipy.io as sio
import numpy as np
import os
# 先读取单个mat文件来看看mat文件的长什么样
matdata = sio.loadmat("D:/P2PNET_ROOT/crowd_datasets/SHHA\DATA_ROOT/part_A_final/test_data\ground_truth/GT_IMG_1.mat")
# print(matdata, type(matdata)) # matdata是以字典的形式存在的
# 提取数据:是以字典的形式存储的,看有哪些key,确认自己需要哪部分信息
# print(matdata.keys()) # dict_keys(['__header__', '__version__', '__globals__', 'image_info'])
image_info = matdata['image_info']
# print(image_info, type(image_info), image_info.ndim, image_info.shape) # image_info是嵌套数组
array = image_info[0][0][0][0][0]
# print(array, array.ndim, type(array)) # 从image_info中提取出了想要的坐标值
for i in range(len(array)): # 利用for循环提取出坐标数值
array1 = array[i]
# print(array1, "\n")
x = array1[0] # 所需x的坐标值
y = array1[1] # 所需y的坐标值
print(x, y, '\n')可以看到已经成功获得x和y的数据

重新整理出.txt标签文档
import scipy.io as sio
import numpy as np
import os
mat_filename_list = os.listdir("D:/P2PNET_ROOT/crowd_datasets/SHHA/DATA_ROOT/part_A_final/test_data/ground_truth")
mat_filename_list2 = os.listdir("D:/P2PNET_ROOT/crowd_datasets/SHHA/DATA_ROO 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 657
657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









