






1.选题描述和分析
1.1题目名称
设计求解规模为n的有向递增序列的有效打乱算法
1.2题目背景
在算法设计和计算机科学中,随机化算法是一个重要的领域,它涉及到如何生成随机序列以模拟或解决特定问题。本题目要求设计一个算法,能够将一个有向递增序列(例如1, 2, 3, ..., n)打乱,以确保序列中的每个元素至少与序列中的其他元素相邻一次。
1.3题目要求
设计一个算法,使得给定长度为n的有向递增序列被打乱,且在打乱的过程中,序列中的任意两个不同元素i和j(1≤i,j≤n)至少有一次相邻的机会。算法需要在时间复杂度上尽可能低,并且能够处理n在50以内的所有情况。
1.4目标
开发一个高效,即时间复杂度低的算法,并通过编程实现,验证其在不同规模n下的性能和有效性。
2.算法设计
2.1问题分析
2.1.1输入输出要求
输入:
一个整数n,表示序列的长度。
一个初始的有向递增序列,例如1, 2, 3, ..., n。
输出:
一个打乱后的序列,该序列满足所有元素i和j(1≤i,j≤n, i≠j)至少有一次相邻的机会。
2.1.2时空要求
时间复杂度:
算法需要尽可能地减少时间复杂度,目标是达到O(n)或接近O(n)的时间复杂度,以便能够处理较大规模的数据。
空间复杂度:
算法应尽量使用较少的额外空间,理想情况下是O(1)或O(n)的空间复杂度,以避免占用过多的内存资源。
2.1.3问题类型
问题定义:
这是一个特定的排列生成问题,要求生成的排列满足特定的相邻条件。
问题难点:
如何确保算法能够生成所有可能的(i, j)组合,即算法的完备性。
如何证明算法的完备性,即证明算法能够覆盖所有组合。
如何在保持算法效率的同时,确保算法的正确性。
算法策略:
可能需要采用随机化算法,结合特定的随机化策略来生成排列。
需要设计一种方法来验证生成的排列是否满足所有(i, j)组合的条件。
2.2算法设计方法比较选择
2.2.1随机交换法
原理:
随机交换法是一种基于概率论和统计学原理的算法,通过一系列操作实现从有序序列到无序序列的转换,从而产生随机性。具体步骤如下:初始化一个有序序列。遍历序列,随机选择一个元素。将选中的元素与序列中另一个随机选择的元素交换位置。继续遍历序列,重复上述步骤,直到达到预期的混乱程度。
优点:
实现简单,逻辑直观,易于编程实现,不需要复杂的数据结构或算法知识。可以通过增加或减少交换次数来控制打乱的程度,适应不同的随机性需求。
缺点:
效率不高,随机交换法可能需要多次交换才能达到所有组合都被覆盖的要求,特别是当序列长度较大时。均匀性和随机性较差,可能无法保证每个排列出现的概率相等。随机交换法难以保证所有可能的(i, j)组合都被覆盖,特别是在没有额外逻辑的情况下,难以证明算法能够覆盖所有组合。
2.2.2 Fisher-Yates洗牌算法
原理:
Fisher-Yates洗牌算法的核心思想是从数组的末尾开始,为每个位置随机选择一个元素(包括自身),然后与该位置的元素交换。这个过程一直进行到数组的开始位置。算法步骤如下: 从数组的最后一个元素开始,向前遍历数组。对于每个位置i,生成一个从0到i(包含i)的随机数j。将位置i的元素与位置j的元素交换。重复上述步骤,直到遍历到数组的第一个元素。这个算法能够确保每个元素都有相同的概率出现在任何位置,从而生成一个均匀分布的随机排列。
优点:
Fisher-Yates洗牌算法只需要遍历数组一次,对于长度为n的数组,时间复杂度为O(n),非常高效。此外,算法只需要一个额外的变量来存储随机数,因此空间复杂度为O(1)。算法能够确保每个排列出现的概率相等,即1/n!,这是真正意义上的随机排列。
缺点:
虽然Fisher-Yates洗牌算法能够生成均匀分布的排列,但题目要求的是确保所有组合都被覆盖,这需要额外的逻辑来检查和验证。例如,可能需要在每次洗牌后检查是否所有(i, j)组合都至少出现过一次。
2.2.3递归回溯法
原理:
递归回溯法的基本思想是使用递归来生成问题的解空间树,然后逐层搜索这个树,直到找到所有可能的解。对于排列问题,解空间树的每一层代表一个位置的填充,而每个节点代表一个可能的元素选择。
算法步骤如下:
初始化:从一个空排列开始。
递归:对于每个位置i,从1到n中选择一个元素填充到位置i。
回溯:在选择一个元素后,递归地填充下一个位置。
终止条件:如果所有位置都已填充,则记录或输出当前排列。
回溯:如果当前排列不满足条件或还有位置未填充,则回溯到上一个位置,尝试下一个可能的元素。
优点:
能够确保找到所有满足条件的排列,不会遗漏任何可能的解。适用于那些需要生成所有可能排列的问题,如排列问题、组合问题等。可以根据问题的具体要求,在递归过程中添加各种约束条件。
缺点:
对于长度为n的序列,递归回溯法需要生成n!个排列,因此时间复杂度为O(n!),这对于较大的n来说是不可行的。由于递归的深度可以达到n,因此空间复杂度较高。对于大规模问题,递归回溯法的效率非常低,可能需要很长时间才能找到所有解。
2.3算法设计方法
2.3.1算法设计思路
综合上述几种算法的优缺点,同时立足此题,我们注意到,需要满足条件“随机且概率均等”,“所有相邻组合至少出现一次”,“足够高效”。不难想到,我们可以设计一个Fisher-Yates洗牌算法的变种,在原有算法保证了打乱的随机性与高效性的基础之上,创建一个集合来记录已出现的相邻元素的组合,每次洗牌后,检查并记录新的组合,直到集合中包含了所有可能的组合。至此,实现了相邻元素组合的完整性。
2.3.2具体方法
从序列的最后一个元素开始,向前遍历序列。
对于每个元素,随机选择一个从当前位置到序列开始位置之间的元素作为交换对象。 然后交换这两个元素。
使用一个集合来存储已经出现过的相邻元素组合。
洗牌后,检查序列中每对相邻元素的组合,如果这个组合不在集合中,则添加到集合中。
继续向前移动到下一个元素,直到遍历完整个序列。
重复洗牌和检查的过程,直到集合包含了所有可能的n(n-1)/ 2个不同的相邻元素组合。
2.3.3伪代码
| procedure shuffle(n: integer)->list: 创建数组arr,包含从1到n的整数 创建集合all_combinations,用于存储不同的组合 当all_combinations的长度小于n * (n - 1) / 2时 对于i从n - 1到1(包括1),步长为-1 j是一个随机整数,范围从0到i(包括i) 交换arr[i]和arr[j]的值 如果i不等于n - 1 创建一个组合,包含arr[i]和arr[i+1]中的较小值和较大值 将这个组合添加到all_combinations集合中 return arr end |
2.3.4流程图
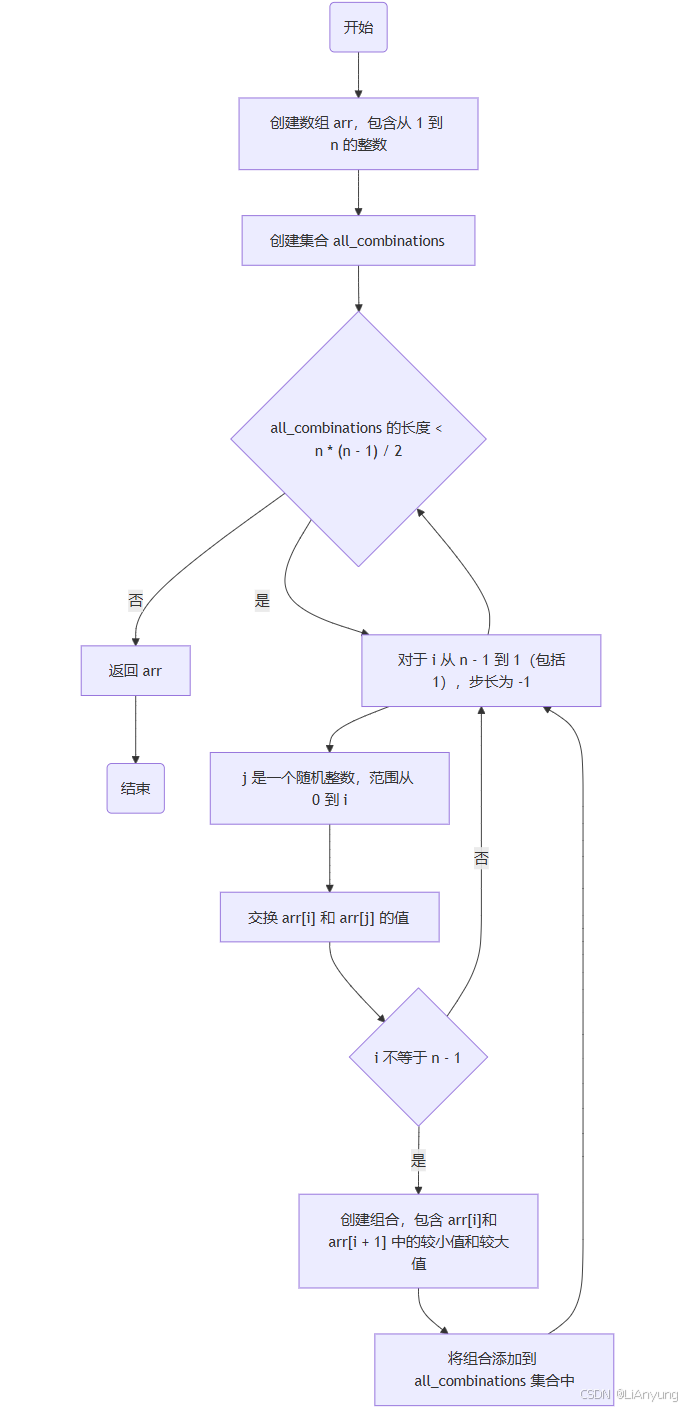
2.3.5证明
随机性证明:
对于一个长度为n的序列,算法从最后一个元素开始,对于每个位置i(从n−1到1),随机选择一个位置j(从0到i),然后交换位置i 和j的元素。
对于每个位置i,选择位置j的概率是 1/ i+1。这意味着每个元素都有相同的机会被选中并与位置i的元素交换。
由于每个元素在每一步都有相同的机会被选中,因此每个元素最终出现在任何位置的概率是相同的。具体来说,对于任意元素x和任意位置k,元素x最终出现在位置k的概率是1/ n。
组合覆盖证明:
每次执行Fisher-Yates洗牌算法都是独立的,且每次洗牌都能生成一个均匀随机的排列。
对于任意两个不同的元素i和j,它们在一次洗牌中成为相邻元素的概率是2/ n−1,因为有n−1对相邻位置,而每对位置被选中的概率是相同的。
由于每次洗牌都是独立的,且每个组合出现的概率是相同的,因此在多次执行洗牌算法后,所有可能的相邻元素组合(i,j)都至少出现一次的概率趋近于1。
时间复杂度:
Fisher-Yates洗牌算法的时间复杂度为O(n),其中n是序列的长度。在洗牌的同时,完成对组合的记录,因此,多次执行算法的时间复杂度为O(k⋅n),其中k是执行洗牌的次数。实际可能达到O(n^2)到O(n^3)。
空间复杂度:
我们需要额外的空间来存储所有相邻元素的组合来说,设置一个集合来存储这些组合,而集合的大小最多为n(n-1)/ 2,算法的空间复杂度为O(n^2)。
3.算法实现
3.1数据结构设计及表示
| 整数n | 输入值,确定有序增数列的上限 |
| 数组arr:list | 包含从1到n的整数,参与后续洗牌。 |
| 集合all_combinations:set | 用于存储不同的组合,元素为长度2的一维元组 |
3.2关键算法代码说明
def shuffle(n)->list: # 定义一个函数,接受整数n并返回列表
arr = list(range(1, n + 1)) # 创建一个从1到n的整数列表
all_combinations = set() # 初始化一个空集合,用于存储唯一的相邻元素组合
iterations = 0 # 初始化迭代次数计数器
while len(all_combinations) < n * (n - 1) // 2: # 当集合中的组合数量小于可能的组合总数时
for i in range(n - 1, 0, -1): # 从最后一个元素向前遍历
j = random.randint(0, i) # 生成一个从0到i的随机数j
arr[i], arr[j] = arr[j], arr[i] # 交换位置i和j的元素
if i != (n - 1): # 如果不是最后一个元素
combination = (min(arr[i], arr[i+1]),max(arr[i], arr[i+1]))
# 生成相邻元素的组合
all_combinations.add(combination) # 将组合添加到集合中
iterations += 1 # 增加迭代次数
print(f"Iterations: {iterations}") # 打印迭代次数
return arr # 返回打乱后的数组
3.3代码测试
import random
def shuffle(n):
arr = list(range(1, n + 1))
global all_combinations # 声明全局变量,方便后续调用
all_combinations = set()
iterations = 0
while len(all_combinations) < n * (n - 1) // 2:
for i in range(n - 1, 0, -1):
j = random.randint(0, i)
arr[i], arr[j] = arr[j], arr[i]
if i != (n - 1):
combination = (min(arr[i], arr[i+1]), max(arr[i], arr[i+1]))
all_combinations.add(combination)
iterations += 1
print(f"Iterations: {iterations}")
return arr
# 测试函数
def test_shuffle(n):
result = shuffle(n)
expected_combinations = n * (n - 1) // 2
print(f"测试输入 n = {n}, 预期组合数: {expected_combinations}")
print(f"实际组合数: {len(all_combinations)}, 结果: {result}")
# 运行测试
test_shuffle(10) # 可以更改测试的n值
在原有代码基础上,声明all_combinations为全局变量,同时,编辑了test_shuffle函数实现对算法的测试与检验,这里以n=10进行测试,运行得到输出结果如下:
| Iterations: 37 测试输入 n = 10, 预期组合数: 45 实际组合数: 45, 结果: [8, 7, 10, 3, 4, 9, 1, 2, 5, 6] |
3.4代码优化
在原始代码中,我们在每次迭代中都检查了所有可能的组合。实际上,我们可以在数组完全打乱后只检查一次。一次性添加所有组合到集合中,而不是在每次交换后都添加。
在每次迭代中,我们复制了原始数组。这可以通过在原地修改数组来避免。
优化随机数生成:我们可以将random.randint(0,i)的调用提取到循环外部,以减少函数调用次数。
以下是优化后的代码:
def shuffle(n):
arr = list(range(1, n + 1))
all_combinations = set()
iterations = 0
while len(all_combinations) < n * (n - 1) // 2:
iterations += 1
for i in range(n - 1, 0, -1):
j = random.randint(0, i) # 提取随机数生成到循环外部
arr[i], arr[j] = arr[j], arr[i] # 原地交换元素
# 一次性添加所有组合到集合中
for i in range(n - 1):
combination = (min(arr[i], arr[i + 1]), max(arr[i], arr[i + 1]))
all_combinations.add(combination)
print(f"Iterations: {iterations}") # 打印迭代次数
return arr # 返回打乱后的数组
4.算法效率分析
4.1时间复杂度分析
洗牌过程:
每次洗牌操作涉及一个从n-1到1的循环,每次循环中有一个常数时间的随机数生成和元素交换操作。因此,单次洗牌的时间复杂度为O(n)。
组合生成:
在洗牌完成后,我们有一个从0到n-2的循环来生成所有相邻元素组合,这个循环的时间复杂度为O(n)。
迭代次数:
最坏情况下,我们需要迭代O(n^2)次来确保所有组合都被覆盖,因为每次迭代至少增加一个新组合,而总共需要O(n^2)个组合,但迭代次数又具有很强的不确定性。
绘制散点图:
编写程序运行代码并计时,依次输入n=10,20,30,40,50,…,100,每次运行50遍,运行3次,共计150遍取平均耗时,单位为秒。记录数据并绘制出如下点状图:
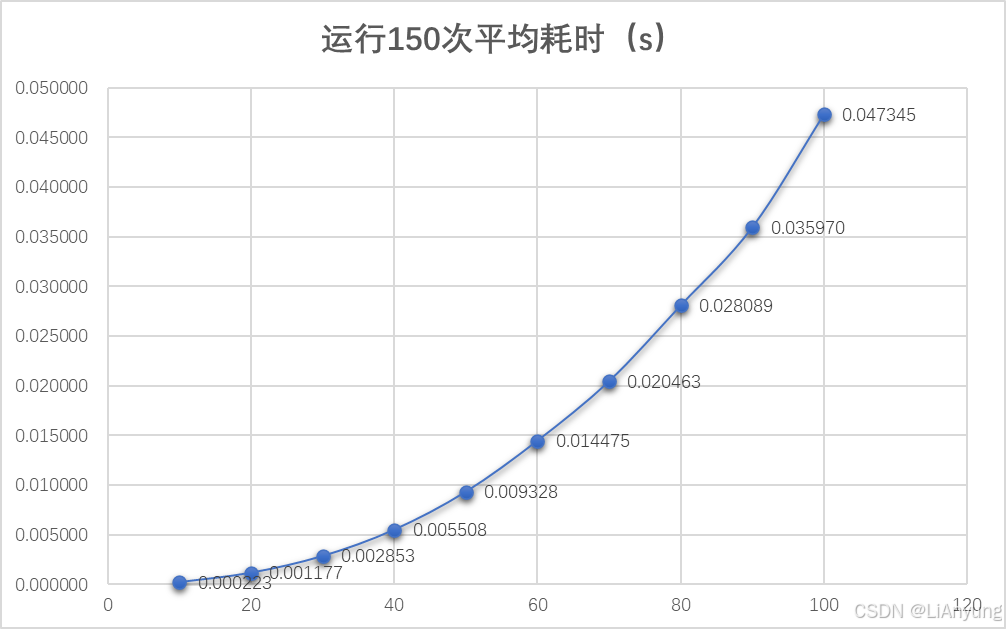
在散点图中,运行时间散点图经过拟合,在O(n^2)时拟合度为0.997,在O(n^3)时拟合度达到0.999。
4.2空间复杂度分析
数组存储:
我们需要一个大小为n的数组来存储序列,因此空间复杂度为O(n)。
组合集合:
我们需要一个集合来存储所有唯一的相邻元素组合。在最坏情况下,这个集合的大小可以达到O(n^2),因为对于长度为n的序列,有n(n−1)/2个可能的组合。
综合以上,空间复杂度为O(n^2)。
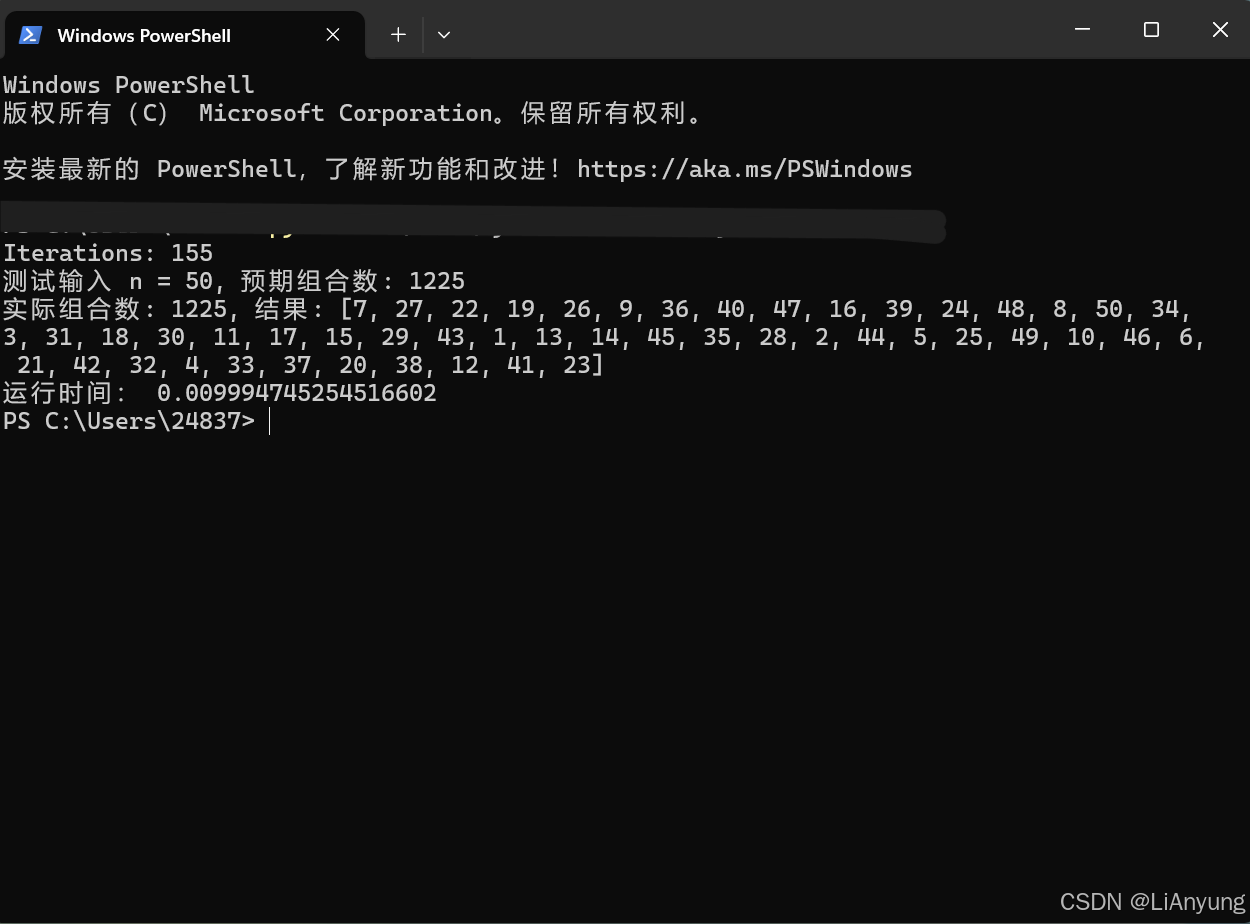
5.运行结果
下图为程序运行结果截图,图中展示了输入值n,组合数、洗牌结果以及运行时间:
6.分析与总结
起初,面对题目要求设计一个能够有效打乱序列并确保所有相邻元素组合至少出现一次的算法时,我首先想到的有遍历求解、递归求全排列、随机数排列等等最基础的解法。后来查阅相关资料,我偶然发现了Fisher-Yates洗牌算法,一种生成随机排列的经典算法。我花了时间去深入理解这个算法的随机性和为什么它能够保证每个元素等概率地出现在任何位置。只有完全深入理解了算法的原理,在后续的设计和优化中才能更加灵活的应用这个算法。
在设计阶段,我将Fisher-Yates洗牌算法与题目要求结合起来,在原来算法的随机性与高效性基础上,我设计了一个变种算法能够保证组合的完备性。这个过程中,我意识到要尽可能保证算法的可行性和效率
在后续分析算法的时间和空间复杂度时,尽管我不能保证自己的分析过程和结果一定准确,我还是进行了尝试。同时,我通过大量进行实验模拟并记录所需时间,绘制得到了散点图,帮助我更深入的认识算法。
在处理大规模数据时,长时间的等待使我深刻认识到算法时间复杂度对于一个算法的意义,以及优化算法、降低时间复杂度是多么的重要。
这个算法的最大痛点在于,只能通过多次迭代无限趋近于100%可能得到满足要求的打乱序列,但并等于100%,即在理论上一定可以返回得到结果。这样看来,生成全排列的思路可以保证一定有输出结果,但直接生成面临n!个序列,实际运行起来效率也不高。(正在学习算法中,以后有什么更好的思路再回来补充)

















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









