










如标题所写,服装换模特,就是把衣服穿在模特道具上,然后拍摄成照片,通过SD处理,将模特道具替换成真人模特。这时候就有人会问,还能这样搞啊,是的,现在电商平台上已经开始通过这种方式做主图详情,不用花钱请真模特拍摄,生了一大笔运营费用。下面我们来看一下这个是怎么做的吧~
1.拍摄产品的模特道具上身照片,
要求光线对比合适,图片质感更好。背景干净,最好纯色或灰色,那样服饰颜色与背景反差大,便于AI识别拆分板块,蒙版抠图。
2.使用Segment Anything(分离图像元素)插件,将图片中的衣服抠出来,作为蒙版,也可以在PS中将它抠出来做成蒙版。
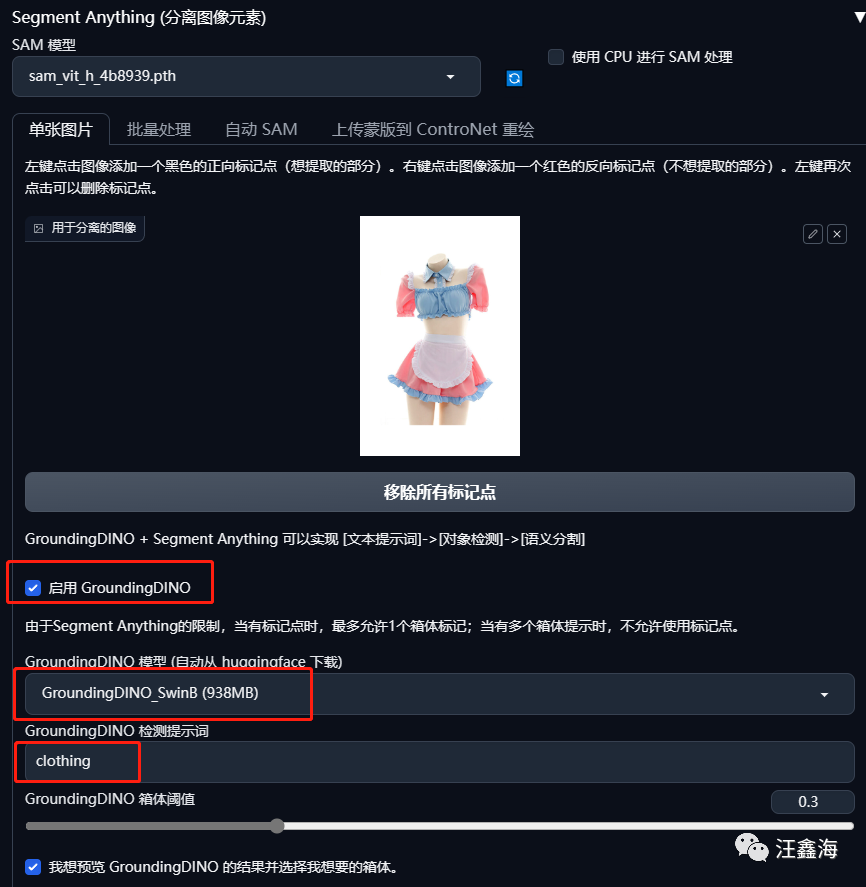
操作步骤:
-
设置好图片尺寸为:512x768px,上传图片;
-
启用 GroundingDINO;
-
选择GroundingDINO 模型(电脑配置好就用938M的);
-
填入GroundingDINO 检测提示词:clothing;
-
想预览的话可以勾选:我想预览 GroundingDINO 的结果并选择我想要的箱体。
-
点击按钮:Generate bounding box;
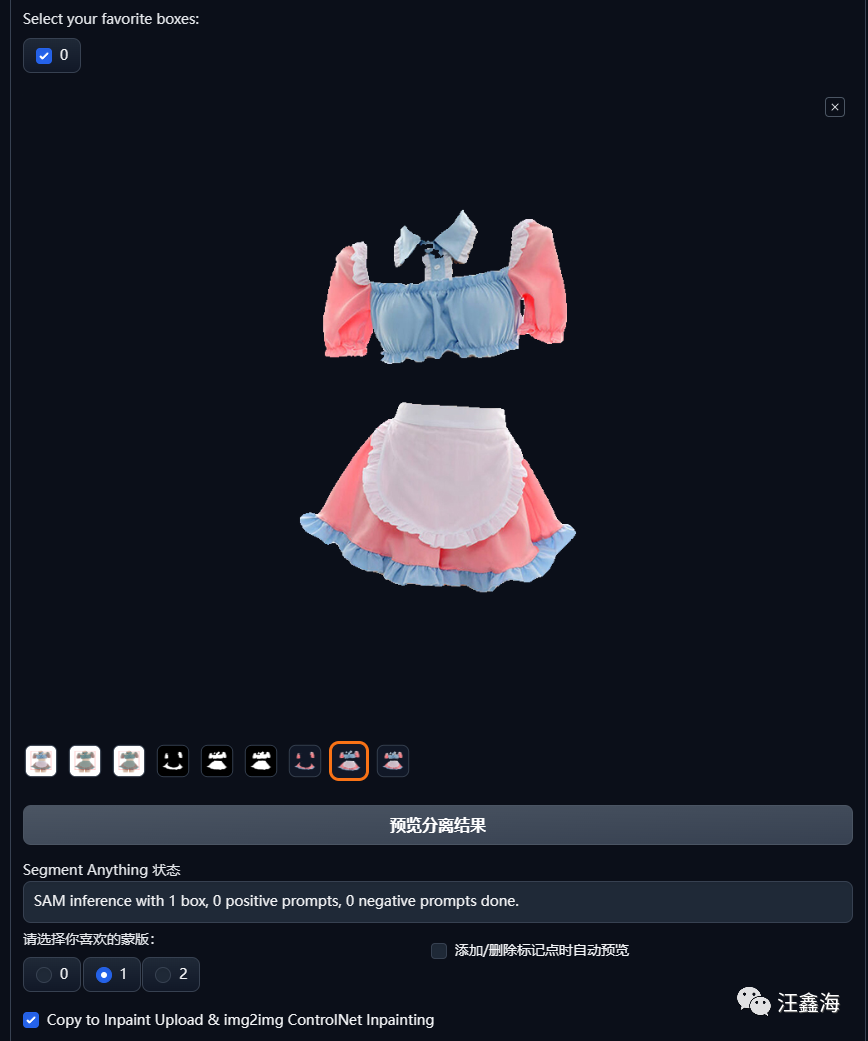
-
选择效果比较好的图,下载下来,或者选择喜欢蒙版的序号1(选择代表第二个),然后勾选:copy to inpaint upload选项,最后点击按钮:发送到 重绘蒙版。
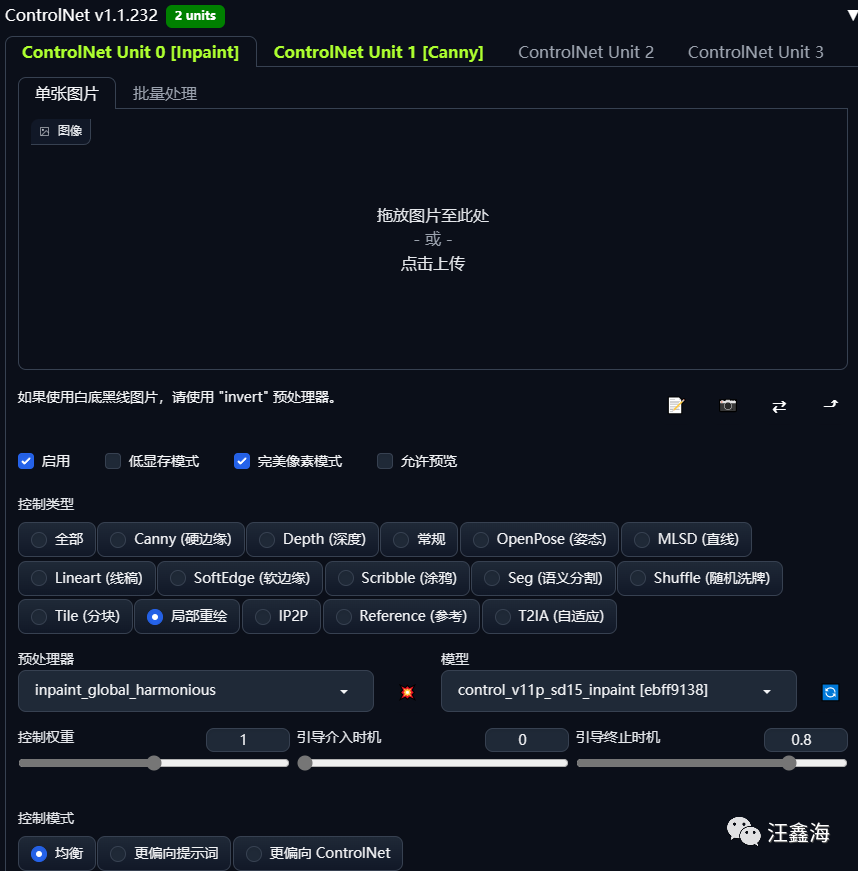
3.ControlNet图片处理,与下一步的openpose骨架图结合,控制要生成模特的姿势动作。
标签ControlNet Unit 0:选择控制模型:局部重绘,预处理器选择:inpaint_global_harmonious.
标签ControlNet Unit 1:上传刚刚抠出来的衣服图片,选择控制模型:canny(硬边缘),点击爆炸图标,这样衣服的图片就以线条的形式勾勒出来了。
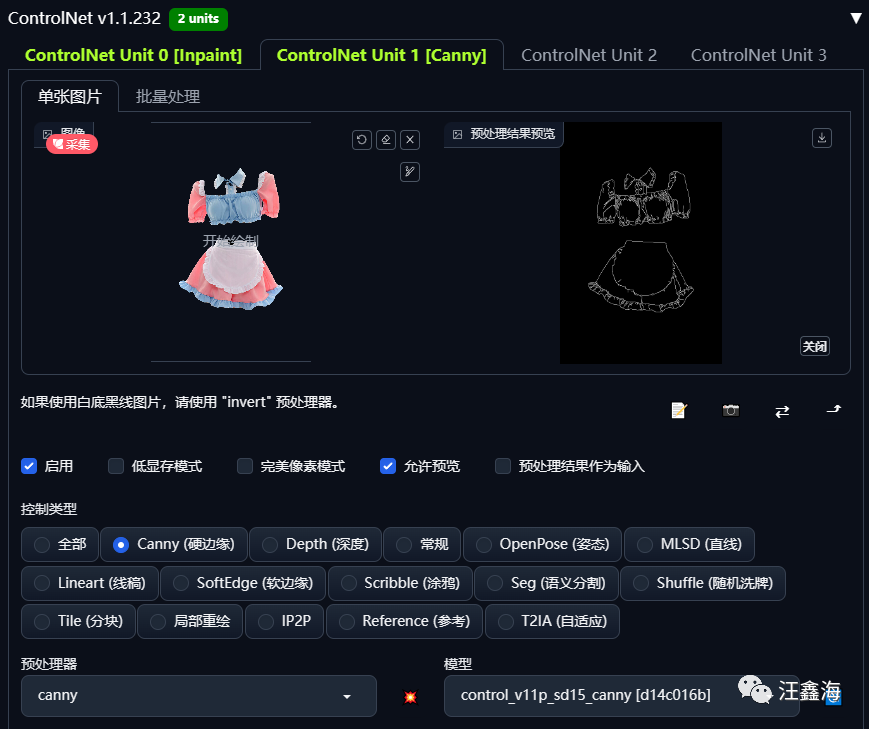
如果我们展示的是中长袖服饰,模特姿势是基本固定的,那么我们可以用canny直接生成线稿生成即可,不需要Openpose识别。

如果是完整模特模型人台或者真人,就算衣服(短裤,短裙等)遮挡不多,我们也可以直接用Openpose识别,自动生成骨架图,然后进行重绘。

我们这次用的是非完整的模特道具,衣服遮挡少,模特的姿势发挥空间不固定,需要配合3D Openpose识别,生成骨架图重绘。

4.打开3D Openpose插件。
a.先根据抠出来的衣服图片在右侧标签栏设置好宽高尺寸(512x768px)。
b.女模特骨骼偏小,设置骨骼厚度为0.5。
c.对骨架做一个简单的调整,然后生成。
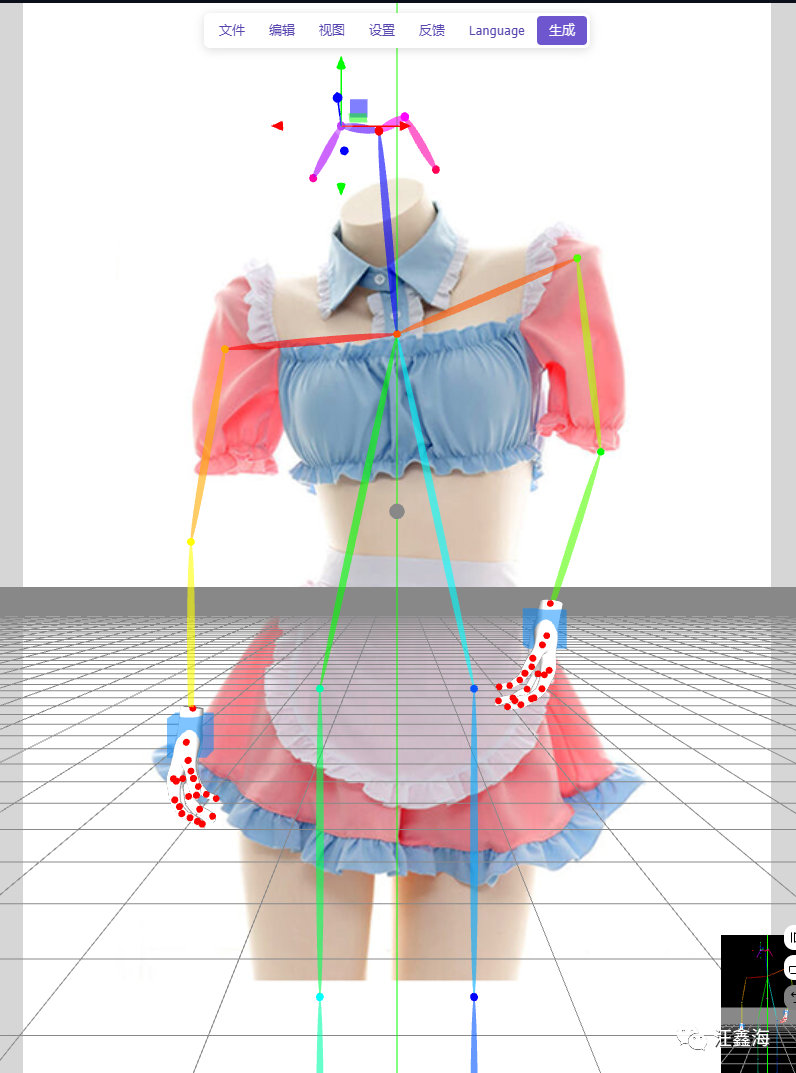
d.选择需要的骨架,设置Control model number数值为2(即发送到:标签ControlNet Unit 2中),其余不要的都选择横杠-,点击按钮:发送到图生图。

e.来到标签ControlNet Unit 2,点击启用+完美像素模式+OpenPose(姿态)+预处理为none,然后为了避免AI生成的模特姿势比较扭曲不自然,可以设置终止实际为0.8,剩下0.2让AI自由发挥。
5.设置局部重绘窗口参数。
-
蒙版模式:重绘非蒙版内容。
-
蒙版内容处理:潜空间噪声
-
采样方式:DPM++SDE Karras,
-
打开面部修复,
-
设置尺寸与图片一致(512x768px),
-
提示词引导系数(CFG scale)为10,
-
重绘幅度为0.9,
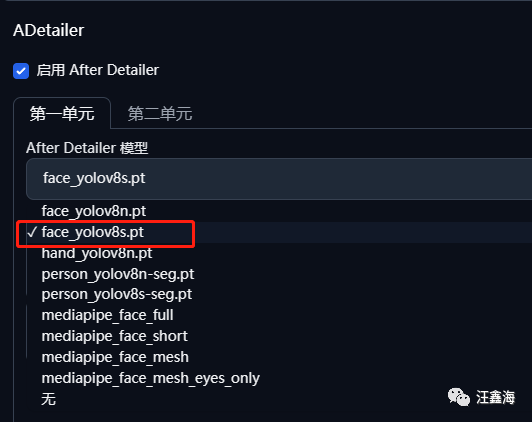
6.选择脸部和手部修复插件ADetailer。
启用,选择真人脸部修复模型:face_yolov8s.pt
7.输入提示词Prompt,这里直接用之前预设好的模板。点击生图。
Prompt
(completely nude:1.4),masterpiece,best quality,raw photo,best quality,photorealistic,simple background,ultra high res,(RAW photo),
1girl,solo,thin female,(half body:1.2),medium shot,high detail face,smile,white light,(create a polished look:0.3),(white background:1.1),
Negative prompt
((nsfw)),sketches,tattoo, (beard:1.3),(EasyNegative),badhandv4, lowres,(worst quality:2),(low quality:2),(normal quality:2),lowers,normal quality,facing away,looking away,text,error,extra digit,fewer digits,cropped,jpeg artifacts,signature,watermark,username,blurry,skin spots,acnes,skin blemishes,bad anatomy,fat,bad feet,cropped,poorly drawn hands,poorly drawn face,mutation,deformed,tilted head.bad anatomy.bad hands,extra fingers,fewer digits.,extra limbs.extra arms,extra legs,malformed limbs.fused fingers.too many fingers,long neck,cross-eyed,mutated hands,bad body,bad proportions,gross proportions,text,error,missing fingers,missing arms,missing legs,extra digit,extra arms,extra leg,extra foot,missing fingers,
lora自定义搭配即可。

关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 3038
3038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









