






此篇博客仅用于对VisionBoard的开发板的学习研究记录,没有教学内容。
目录
传菜机械臂的视觉识别部分的项目报告
主要分为四部分,开发板功能,比赛(思路介绍,代码实现,注意事项)
如果是想查看关于传菜机械臂的可以直接[点击跳转到比赛部分](## 比赛部分)
如果想查看OpenMV的干货[点击跳转到OpenMV重点部分](## OpenMV重点)
一、开发板功能
关于目标识别的资料总结
1.1 物体检测
使用颜色跟踪、边缘检测和斑点检测等功能来识别和跟踪摄像头视野内的物体。例如,find_blobs()函数可以根据颜色阈值检测物体,这对于检测红色球或特定图案非常有用。
- 颜色跟踪:通过颜色阈值检测和跟踪特定颜色的物体。
- 示例代码:
import sensor, image, time sensor.reset() sensor.set_pixformat(sensor.RGB565) sensor.set_framesize(sensor.QVGA) sensor.skip_frames(time = 2000) while(True): img = sensor.snapshot() blobs = img.find_blobs([(30, 100, 15, 127, 15, 127)]) # 红色范围 for blob in blobs: img.draw_rectangle(blob.rect()) img.draw_cross(blob.cx(), blob.cy())- 参数:
sensor.RGB565: 使用RGB565格式进行图像采集。sensor.QVGA: 使用320x240分辨率进行图像采集。find_blobs([(30, 100, 15, 127, 15, 127)]): 颜色阈值(L, A, B)范围,用于检测红色物体。
- 参数:
1.2 人脸检测
OpenMV Cam支持使用Haar特征进行简单的人脸检测,可以在检测到人脸时触发某些动作。
- Haar特征检测:利用预训练的Haar特征级联分类器进行人脸检测。
import sensor, image, time, pyb sensor.reset() sensor.set_pixformat(sensor.GRAYSCALE) sensor.set_framesize(sensor.QVGA) sensor.skip_frames(time = 2000) face_cascade = image.HaarCascade("frontalface", stages=25) while(True): img = sensor.snapshot() faces = img.find_features(face_cascade, threshold=0.5, scale_factor=1.5) for face in faces: img.draw_rectangle(face)- 参数:
image.HaarCascade("frontalface", stages=25): 使用预训练的正面人脸Haar级联分类器,共25个级联阶段。find_features(face_cascade, threshold=0.5, scale_factor=1.5): 检测人脸,设置阈值和缩放因子。
- 参数:
1.3 特征匹配
可以在不同图像之间进行特征匹配,这对于识别和区分多个物体非常重要。
- ORB特征匹配:用于识别和匹配图像中的特征点。
import sensor, image, time sensor.reset() sensor.set_pixformat(sensor.GRAYSCALE) sensor.set_framesize(sensor.QVGA) sensor.skip_frames(time = 2000) template = image.Image("/example.pgm") while(True): img = sensor.snapshot() match = img.find_keypoints(max_keypoints=150, threshold=10, scale_factor=1.2, normalized=True).match(template) if match: img.draw_rectangle(match.rect())- 参数:
find_keypoints(max_keypoints=150, threshold=10, scale_factor=1.2, normalized=True): 检测图像中的关键点。match(template): 与模板图像进行匹配。
- 参数:
关于目标定位功能的资料总结
2.1 3D位置估计
结合IMU(惯性测量单元)数据和视觉数据,板子可以估计物体的3D位置。通过使用卡尔曼滤波或Madgwick滤波等传感器融合技术,可以提高精度。
- IMU数据融合:通过IMU传感器的数据进行3D位置估计。结合视觉数据,使用卡尔曼滤波等技术实现高精度定位。
from machine import I2C from mpu6050 import MPU6050 i2c = I2C(1) mpu = MPU6050(i2c) while True: accel = mpu.get_accel() gyro = mpu.get_gyro() print("Accelerometer:", accel) print("Gyroscope:", gyro)- 参数:
MPU6050(i2c): 使用MPU6050传感器获取加速度计和陀螺仪数据。get_accel(),get_gyro(): 获取加速度和陀螺仪数据。
- 参数:
2.2 物体跟踪
通过连续监控物体的位置,VisionBoard可以实时跟踪物体的移动。这对于需要精确物体跟踪的应用(如机器人导航和互动)非常有用。
- 连续跟踪:实时监控物体位置,进行物体跟踪。结合IMU和视觉数据,实现精确定位。
import sensor, image, time sensor.reset() sensor.set_pixformat(sensor.RGB565) sensor.set_framesize(sensor.QVGA) sensor.skip_frames(time = 2000) clock = time.clock() while(True): clock.tick() img = sensor.snapshot() blobs = img.find_blobs([(30, 100, 15, 127, 15, 127)]) for blob in blobs: img.draw_rectangle(blob.rect()) img.draw_cross(blob.cx(), blob.cy()) print("Tracking object at: x=", blob.cx(), " y=", blob.cy())- 参数:
find_blobs([(30, 100, 15, 127, 15, 127)]): 颜色阈值(L, A, B)范围,用于检测和跟踪物体。
- 参数:
OpenMV重点
1. OpenMV IDE:支持MicroPython脚本,简化开发过程。提供图像数据可视化、调试工具和摄像头设置配置。
2. 简单的来说,OpenMV是一个可编程的摄像头,通过MicroPython语言,可以实现你的逻辑。而且摄像头本身内置了一些图像处理算法,很容易使用。
3. OpenMV的识别距离:标配镜头:乒乓球大小的物体可识别范围在0.5m~1m;人脸识别范围在1m。
4. OpenMV的算法概括
- 追踪颜色、二维码识别、人脸识别、机器人巡线、模版匹配、特征点检测、人眼追踪、HAAR,LBP,HOG算法、保存图像、录制视频、边缘检测、瞳孔识别、直线检测、光流人脸分辨、AprilTag。
5. OpenMV图像处理的方法
6. MicroPython的函数文档
- MicroPython 和 OpenMV Cam 中文文档 、MicroPython 和 pyboard 中文文档 、MicroPython 和 ESP32 中文文档 、MicroPython 和 moxing-stm32 中文文档 。
7. 寻找色块函数
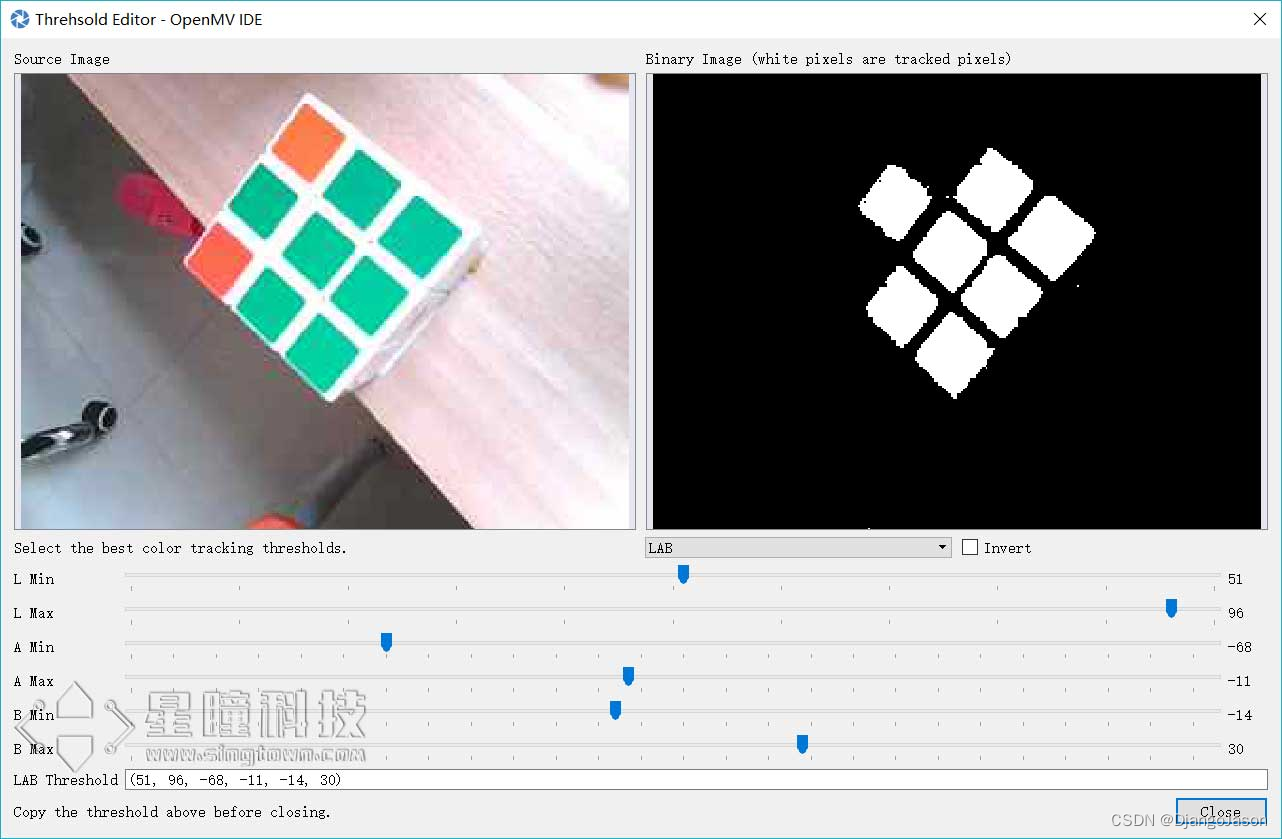
- OpenMV 的IDE里加入了阈值选择工具,极大的方便了对于颜色阈值的调试。
拖动六个滑块,可以实时的看到阈值的结果,我们想要的结果就是,将我们的目标颜色变成白色,其他颜色全变为黑色。
- AprilTag是一个视觉基准系统,可用于各种任务,包括AR,机器人和相机校准。这个tag可以直接用打印机打印出来,而AprilTag检测程序可以计算相对于相机的精确3D位置,方向和 id。

简单来说,只要把这个tag贴到目标上,就可以在OpenMV上识别出这个标签的3D位置,id。
AprilTag最神奇的是3D定位的功能,它可以得知Tag的空间位置,一共有6个自由度,三个位置,三个角度。 在串口输出为6个变量,Tx, Ty, Tz为空间的3个位置量,Rx,Ry,Rz为三个旋转量。
9. 模板匹配
- 模板匹配(
find_temolate)采用的是ncc算法,只能匹配与模板图片大小和角度基本一致的图案。局限性相对来说比较大,视野中的目标图案稍微比模板图片大一些或者小一些就可能匹配不成功。
模板匹配适应于摄像头与目标物体之间距离确定,不需要动态移动的情况。 比如适应于流水线上特定物体的检测,而不适应于小车追踪一个运动的排球(因为运动的排球与摄像头的距离是动态的,摄像头看到的排球大小会变化,不会与模板图片完全一样)。
多角度多大小匹配可以尝试保存多个模板,采用多模板匹配。
10. 特征点检测
- 特征点检测(
find_keypoint): 如果是刚开始运行程序,例程提取最开始的图像作为目标物体特征,kpts1保存目标物体的特征。默认会匹配目标特征的多种比例大小和角度,而不仅仅是保存目标特征时的大小角度,比模版匹配灵活,也不需要像多模板匹配一样保存多个模板图像。
特征点检测,也可以提前保存目标特征,之前是不推荐这么做的,因为环境光线等原因的干扰,可能导致每次运行程序光线不同特征不同,匹配度会降低。但是最新版本的固件中,增加了对曝光度、白平衡、自动增益值的调节,可以人为的定义曝光值和白平衡值,相对来说会减弱光线的干扰。也可以尝试提前保存目标特征。
11. 扫码识别
12. 颜色形状同时识别、颜色与模板匹配同时识别
13. 分辨不同人脸
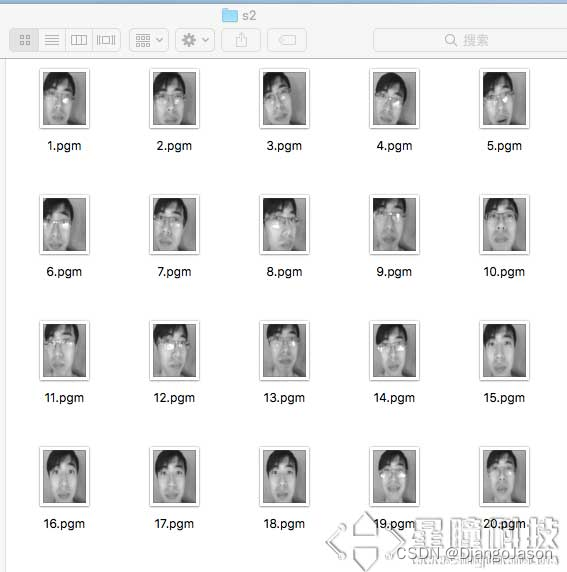
- 使用LBP特征分辨不同的人脸。需要先建立自己的图像库,然后运行以下代码来采集不同的人脸样本。注意采集时尽量让背景均匀,并且让人脸尽量充满整个画面。人脸可以微笑,不笑,正脸,歪头,戴眼镜,不戴眼镜等。可以选择每人10-20张图片。
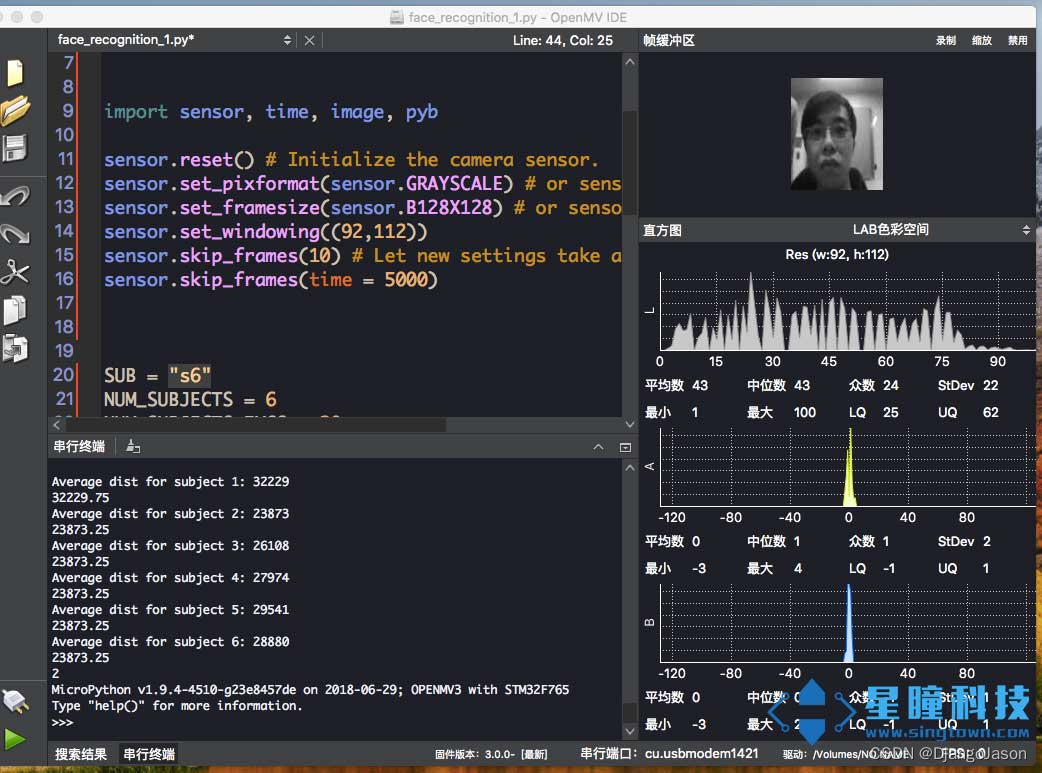
运行以下代码,来识别当前摄像头视野内的人脸,并输出与当前对象最匹配的人。
# Face recognition with LBP descriptors.
# See Timo Ahonen's "Face Recognition with Local Binary Patterns".
#
# Before running the example:
# 1) Download the AT&T faces database http://www.cl.cam.ac.uk/Research/DTG/attarchive/pub/data/att_faces.zip
# 2) Exract and copy the orl_faces directory to the SD card root.
import sensor, time, image
sensor.reset() # Initialize the camera sensor.
sensor.set_pixformat(sensor.GRAYSCALE) # or sensor.GRAYSCALE
sensor.set_framesize(sensor.B128X128) # or sensor.QQVGA (or others)
sensor.set_windowing((92,112))
sensor.skip_frames(10) # Let new settings take affect.
sensor.skip_frames(time = 5000) #等待5s
#SUB = "s1"
NUM_SUBJECTS = 6 #图像库中不同人数,一共6人
NUM_SUBJECTS_IMGS = 20 #每人有20张样本图片
# 拍摄当前人脸。
img = sensor.snapshot()
#img = image.Image("singtown/%s/1.pgm"%(SUB))
d0 = img.find_lbp((0, 0, img.width(), img.height()))
#d0为当前人脸的lbp特征
img = None
pmin = 999999
num=0
def min(pmin, a, s):
global num
if a<pmin:
pmin=a
num=s
return pmin
for s in range(1, NUM_SUBJECTS+1):
dist = 0
for i in range(2, NUM_SUBJECTS_IMGS+1):
img = image.Image("singtown/s%d/%d.pgm"%(s, i))
d1 = img.find_lbp((0, 0, img.width(), img.height()))
#d1为第s文件夹中的第i张图片的lbp特征
dist += image.match_descriptor(d0, d1)#计算d0 d1即样本图像与被检测人脸的特征差异度。
print("Average dist for subject %d: %d"%(s, dist/NUM_SUBJECTS_IMGS))
pmin = min(pmin, dist/NUM_SUBJECTS_IMGS, s)#特征差异度越小,被检测人脸与此样本更相似更匹配。
print(pmin)
print(num) # num为当前最匹配的人的编号。
运行结果如图:
比赛部分
二、思路介绍
1. 需求
- 需要在获得用户的订单之后,准确的识别出所需的菜品。
- 针对要拿取的菜品给出准确的位置信息,帮助机械臂的运动。
- 如果有必要,还需要实时传送菜品的位置信息,实现菜品的追踪
2. 对标VisionBoard的功能
- 需要一个特征匹配功能——来识别不同的物体以及想要的物体
- 定位能力:3D位置估计(可能还需要一些物体追踪的能力)
- 与机械臂的配合:需要将位置参数传给主控板——因此目标就是
1. 识别多个物体,判断哪个物体是所想要的(符合主控板给出的信息)
2. 计算目标物体和camera的距离。
3. 将参数(X,Y,Z坐标)传回给主控板 - 参数:测距可以使用Apriltag进行3D定位 运用IMU(惯性测量单元)数据
3. 目标识别功能
-
通过图像进行特征点识别并进行训练,可以使用基于机器学习的方法。OpenMV 支持使用 TensorFlow Lite 进行图像分类和对象检测。使用一个预训练的模型,并进行特征点识别,需要一个包含特征点标记的图像数据集,并使用这些数据训练模型。
-
数据准备:
收集包含特征点的图像数据,并标注这些图像。将这些图像和标签保存到一个目录中,比如 /sd/。 -
特征点识别:
训练模型使用的是edge impulse,在Vision Board上部署,将下载下来的压缩文件解压(”trained.tflite”、”labels.txt”、”ei_image_classification.py”),将ei_image_classification.py改名为main.py,随后将3个文件全部复制到sd卡中去(确保sd卡无其他文件)。用type-c线连接Vision Board USB-OTG口,随后将sd卡中的main.py拖入OpenMV IDE中,打开并运行即可 -
通过这种方式,就可以在 OpenMV 上实现基于特征点的图像识别。需要注意的是,特征点识别模型的准确性和性能取决于训练数据的质量和模型的复杂性。
4. 目标定位功能
-
获取食物的实时位置:用 OpenMV IDE 内置的串行通信功能将食物的坐标实时发送到PC,并通过Python脚本在PC上显示这些信息。
-
这个脚本会接收从OpenMV板发送过来的数据,并在控制台上显示检测到的食物及其坐标。确保将 COM3 替换为实际连接OpenMV板的串行端口。
5. 注意事项
代码实现中使用已知物体尺寸推算距离法,大致的可以输出摄像头与物体的三维距离
- 利用OpenMV进行测距
第一种方法:
利用apriltag,Apriltag可以进行3D定位。
第二种方法:
OpenMV采用的是单目摄像头,想要实现测距,就需要选参照物,利用参照物的大小比例来计算距离。
计算公式:距离 = 一个常数/直径的像素
常数获取步骤:先让球距离摄像头10cm,打印出摄像头里直径的像素值,然后相乘,就得到了k的值! - 后期如果想获得更精准的深度信息,可以更换一颗能获得深度值的摄像头
三、代码实现
import sensor, image, time, os, tf, math, uos, gc, pyb
# sensor用于控制摄像头设置和图像捕获; os、uos、gc:用于文件操作、内存管理等系统功能;
# tf:TensorFlow Lite模块,用于加载和执行神经网络模型; pyb:提供硬件控制接口,如UART通信
#用于计算深度的变量
KNOWN_WIDTH = 3.5 # 已知物体的宽度(厘米)
FOCAL_LENGTH = 308.57 # 摄像头的焦距,需校准(像素)
#摄像头的初始化与配置
sensor.reset() # 重置并初始化传感器。
sensor.set_pixformat(sensor.RGB565) # 设置像素格式为RGB565(或灰度)。
sensor.set_framesize(sensor.QVGA) # 设置帧大小为QVGA(320x240)。
sensor.set_windowing((240, 240)) # 设置窗口大小为240x240。
sensor.skip_frames(time=2000) # 让摄像头进行调整。
net = None
labels = None
min_confidence = 0.5
name=['SMZ','HBH','BQL','BMH','DRG','XST']
#Edge Impulse提供的两个安全加载模型和标签的判断结构
try:
# 加载模型,如果加载后剩余至少64K内存,则在堆上分配模型文件。
net = tf.load("trained.tflite", load_to_fb=uos.stat('trained.tflite')[6] > (gc.mem_free() - (64*1024)))
except Exception as e:
raise Exception('加载"trained.tflite"失败,请确保将.tflite和labels.txt文件复制到存储设备上。 (' + str(e) + ')')
try:
labels = [line.rstrip('\n') for line in open("labels.txt")]
except Exception as e:
raise Exception('加载"labels.txt"失败,请确保将.tflite和labels.txt文件复制到存储设备上。 (' + str(e) + ')')
uart = pyb.UART(2, 115200, timeout_char=1000) # 初始化UART,波特率为115200
def calculate_depth(w, known_width=KNOWN_WIDTH, focal_length=FOCAL_LENGTH):
# 使用已知物体的宽度和摄像头的焦距计算深度信息
return math.floor((known_width * focal_length) / w) # 取整数作为深度值
while(True):
img = sensor.snapshot() # 获取摄像头图像。
# detect()返回图像中找到的所有对象(已按类别分割),我们跳过类别索引0(背景)。
for i, detection_list in enumerate(net.detect(img, thresholds=[(math.ceil(min_confidence * 255), 255)])):
if (i == 0): continue # 跳过背景类别。
if (len(detection_list) == 0): continue # 跳过空检测列表
for d in detection_list:
[x, y, w, h] = d.rect() # 获取对象的边界框坐标。
# 计算中心坐标
cx = x + w // 2
cy = y + h // 2
# 计算深度信息
depth = calculate_depth(w)
# 构建输出格式:XST,100,100,100
output = "{},{:03},{:03},{:03}".format(name[i-1], cx, cy, depth)
print(output) # 打印发送的数据,用于调试
# 通过UART发送数据到主控板
uart.write(output + '\n')
# 绘制识别到的目标的边界和中心点
img.draw_rectangle(d.rect())
img.draw_cross(cx, cy)
time.sleep(0.1) # 适当延时,避免过快发送数据导致缓冲区溢出
使用这个函数可以让摄像头实现上下左右颠倒。
sensor.set_hmirror(True)
sensor.set_vflip(True)

















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









