









参考代码:SurroundDepth
介绍
在这篇文章中提出一种多视图融合实现自监督深度估计的方法。使用backbone实现多视图特征抽取之后将这些特征通过multi-scale的self-attention融合,使得多视图中具有视角交叉的图像信息得到交换和融合,特别地在融合过程中借鉴了多尺度和skip-connect的策略用于优化图像特征。对于位姿估计部分,这里采用多视图预测一个整体位姿的方式实现位姿估计,文中的实验结果也表明这样的方式在DDAD等数据集上具有涨点,但是对于对于车辆在弯道、时序不统一(天杀的软同步)的时候位姿的变化就不是那么统一了,这种位姿估计方式的好坏还需要根据实际数据场景实验下看看效果。在FSM方法中也能通过相机外参得到scale-aware的深度估计结果,但由于在训练的初期光度重构误差并不能带来很好的约束,对此需要引入额外信息作为辅助。在这里使用的是使用三角化计算稀疏深度图用作网络预监督训练过程,之后的自监督再加载它的参数继续训练。
文章的方法与FSM多视图自监督深度估计方法流程上的对比如下图:
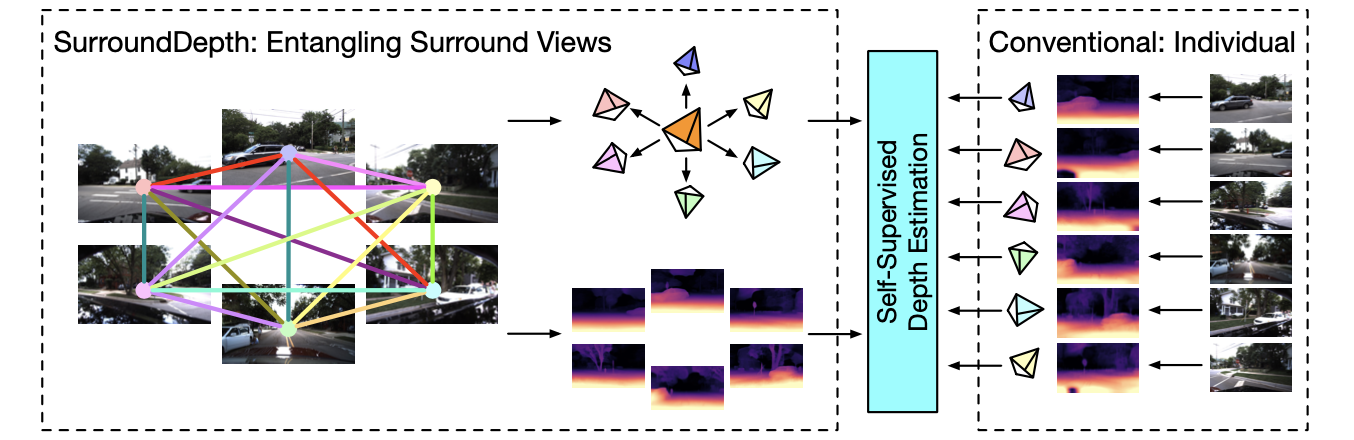
可以看到文章的方法是同时处理多张图像,并输出对应位姿和深度估计结果。
方法设计
文章方法的结构如下图:
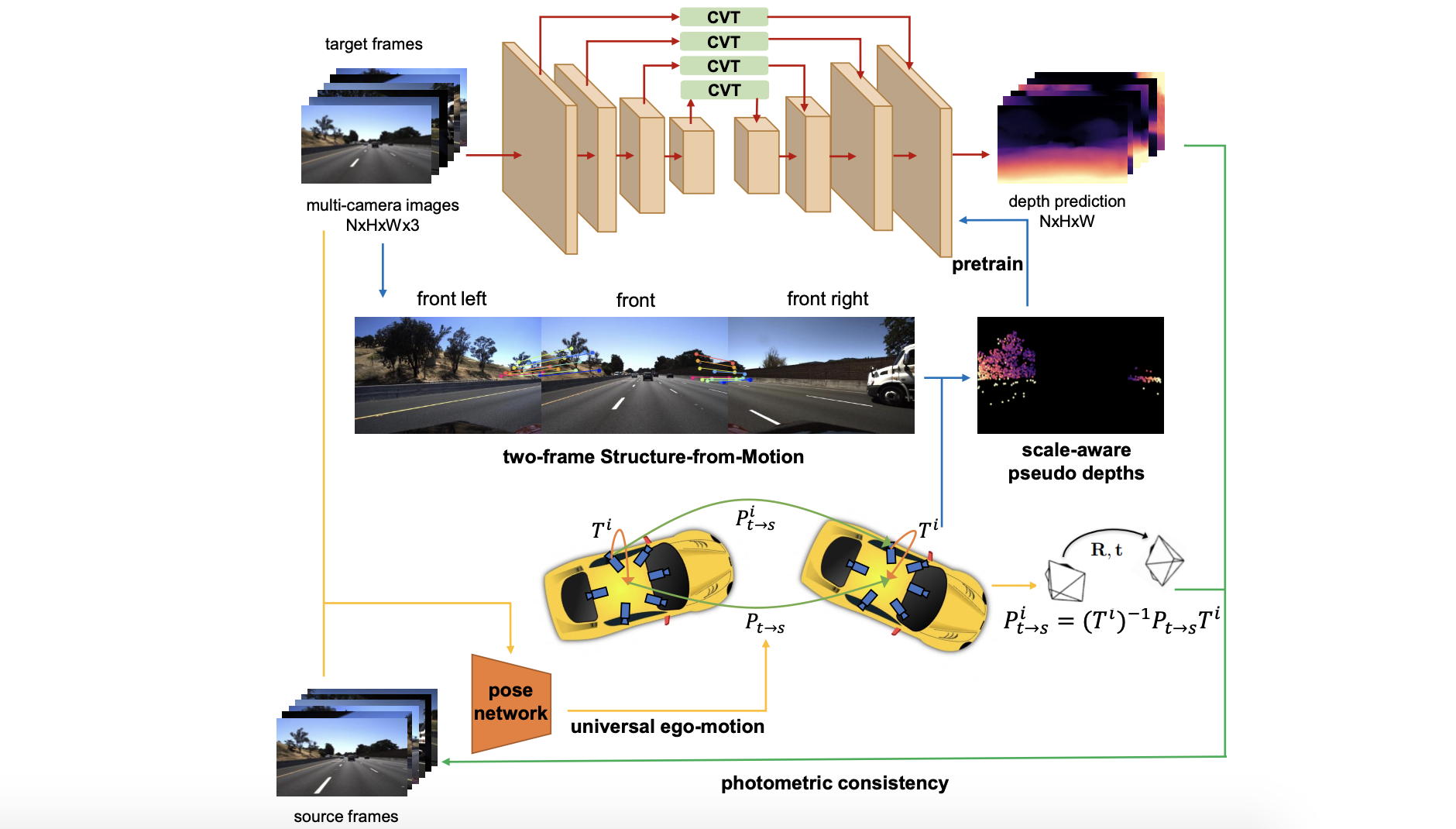
依据上图主要结构划分为3个部分:
- 1)CVT实现多视图特征融合,并得到深度估计结果。
- 2)使用多视图预测整个车辆的位姿变化。
- 3)使用三角化得到的稀疏深度估计结果做网络的预训练。
Cross-View Self Attention
为了融合并关联多视图数据,文章将多视图的特征柔和在batch维度之后通过self-attention的方式进行特征融合。由于直接使用图像特征图,其分辨率比较大会带来较大的计算量开销,这里通过维度下采样——attention——再上采样的方式进行缓解。不过这里self-attention的计算方式其实不是最优的,self-attention需要在众多视图中寻找到合适的信息比较难,其实对于当前是视图与其相关的也就是左右俩相机的数据,从这个思路思考下去能减少不少计算量。
其计算的过程可以参考下图:
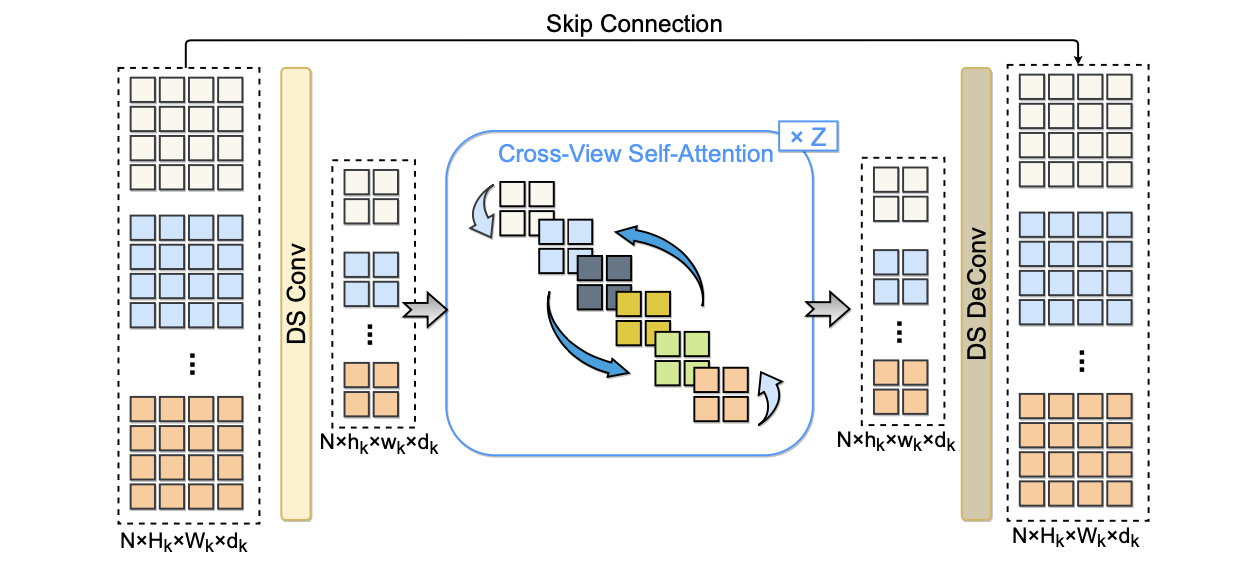
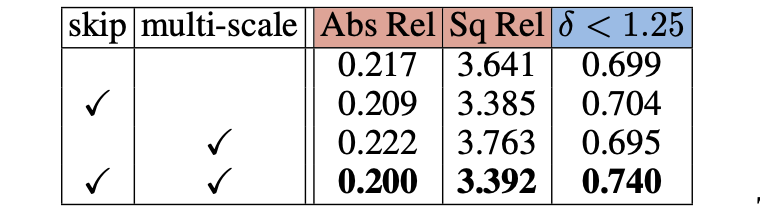
为了提升性能这里在各个多尺度特征维度上都做了self-attention和skip-connection操作,这俩操作确实也能带来一些涨点:
统一地位姿估计和深度监督预训练
在这篇文章中假定了自车是类似于质点的存在,不会因为传感器安装位置导致实际位姿不一样的情况。这里直接使用多视图图像作为输入得到车辆的位姿变化,之后再由车辆上装载的不同相机实现视角warp,从而实现自监督过程。
这篇文章中在FSM算法的训练开始阶段,光度重构误差并不能很好约束深度估计出来的scale属性,对此这里对于存在视场交叠的不同相机使用三角化方法得到稀疏深度表达,并用这个稀疏深度去预训练网络。
对于这俩策略带来的性能改善见如下消融实现,对于DDAD数据集:
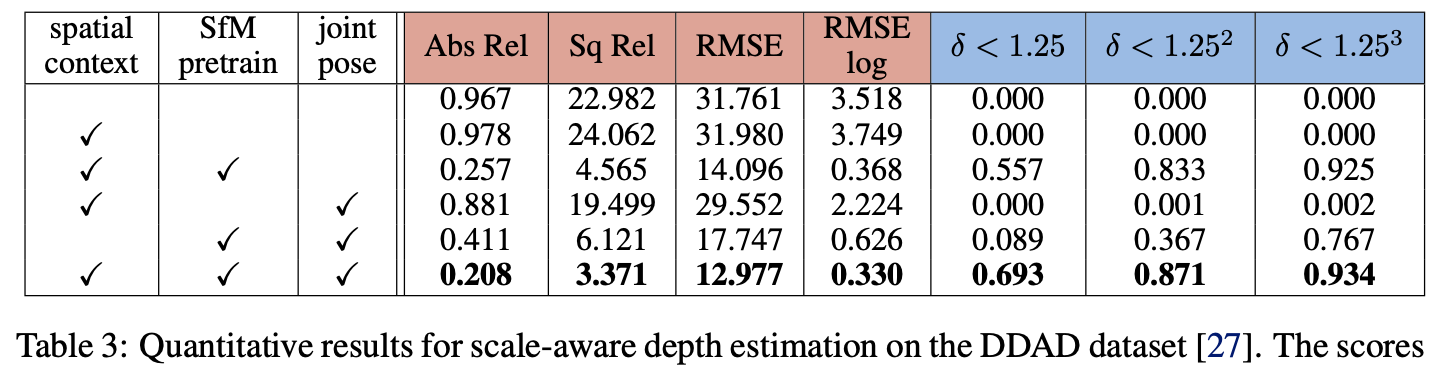
对于nuScenes数据集:
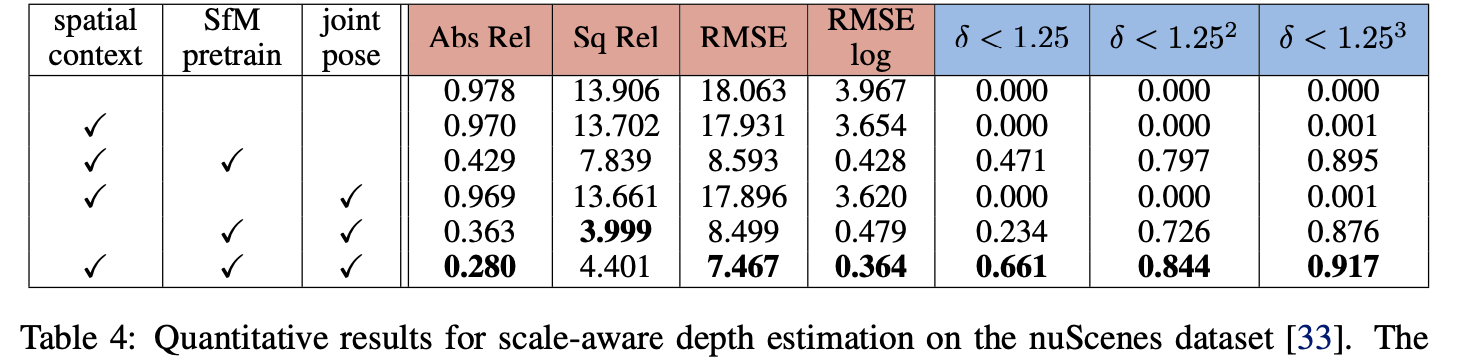
实验结果
DDAD数据集下于其它方法的性能比较:
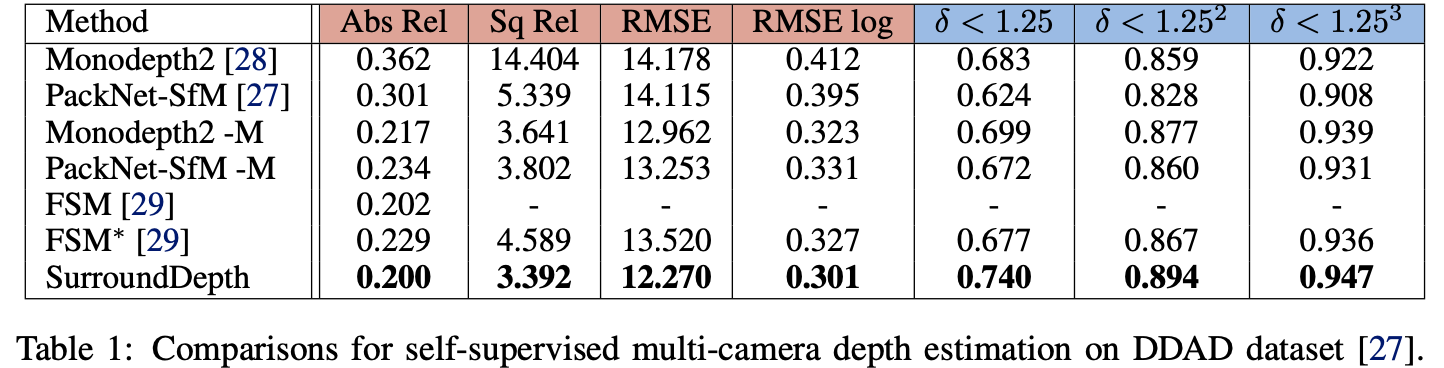
nuScenes数据集下:
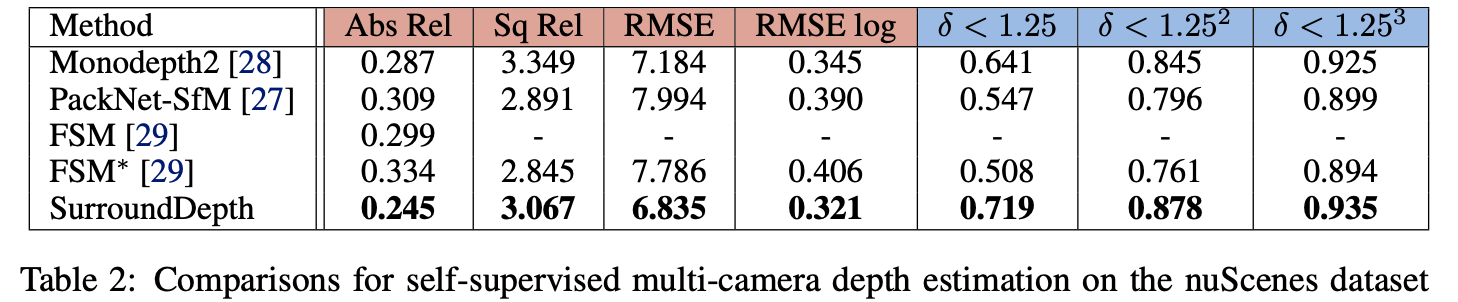















 2084
2084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









