







 论文介绍了一种名为SCConv的新方法,通过空间重构单元(SRU)和信道重构单元(CRU)来减少CNN中的冗余特征,从而提高性能和降低计算成本。实验结果显示,SCConv在图像分类和对象检测任务中表现优秀,提供了一个平衡性能与效率的轻量化模型设计策略。
论文介绍了一种名为SCConv的新方法,通过空间重构单元(SRU)和信道重构单元(CRU)来减少CNN中的冗余特征,从而提高性能和降低计算成本。实验结果显示,SCConv在图像分类和对象检测任务中表现优秀,提供了一个平衡性能与效率的轻量化模型设计策略。
目录
2.2SRU for Spatial Redundancy编辑

一、摘要
卷积神经网络(cnn)在各种计算机视觉任务中取得了显著的性能,但这是以巨大的计算资源为代价的,部分原因是卷积层提取冗余特征。最近的作品要么压缩训练有素的大型模型,要么探索设计良好的轻量级模型。在本文中,我们尝试利用特征之间的空间和通道冗余来进行CNN压缩,并提出了一种高效的卷积模块,称为SCConv (spatial and channel reconstruction convolution),以减少冗余计算并促进代表性特征的学习。提出的SCConv由空间重构单元(SRU)和信道重构单元(CRU)两个单元组成。SRU采用分离重构的方法来抑制空间冗余,CRU采用分离变换融合的策略来减少信道冗余。此外,SCConv是一种即插即用的架构单元,可直接用于替代各种卷积神经网络中的标准卷积。实验结果表明,SCConv嵌入模型能够通过减少冗余特征来获得更好的性能,并且显著降低了复杂度和计算成本。
论文贡献总结:
1. 提出了一种空间重构单元SRU,该单元根据权重分离冗余特征并进行重构,以抑制空间维度上的冗余,增强特征的表征能力。
2. 我们提出了一种信道重构单元,称为CRU,它利用分裂变换和融合策略来减少信道维度的冗余以及计算成本和存储。
3.我们设计了一种名为SCConv的即插即用操作,将SRU和CRU以顺序的方式组合在一起,以取代标准卷积,用于在各种骨干cnn上操作。结果表明,SCConv可以大大节省计算负荷,同时提高模型在挑战性任务上的性能。
二、创新点说明
2.1 Methodology
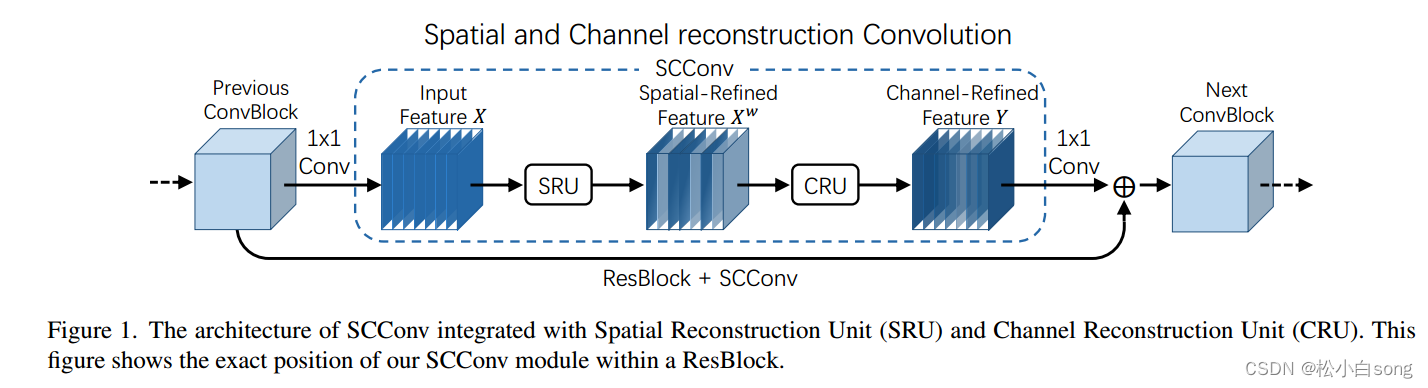
SCConv,它由两个单元组成,空间重建单元(SRU)和通道重建单元(CRU),以顺序的方式放置。具体而言,对于瓶颈残差块中的中间输入特征X,我们首先通过SRU运算获得空间细化特征Xw,然后利用CRU运算获得信道细化特征Y。我们在SCConv模块中利用了特征之间的空间冗余和通道冗余,可以无缝集成到任何CNN架构中,以减少中间特征映射之间的冗余并增强CNN的特征表示。
2.2SRU for Spatial Redundancy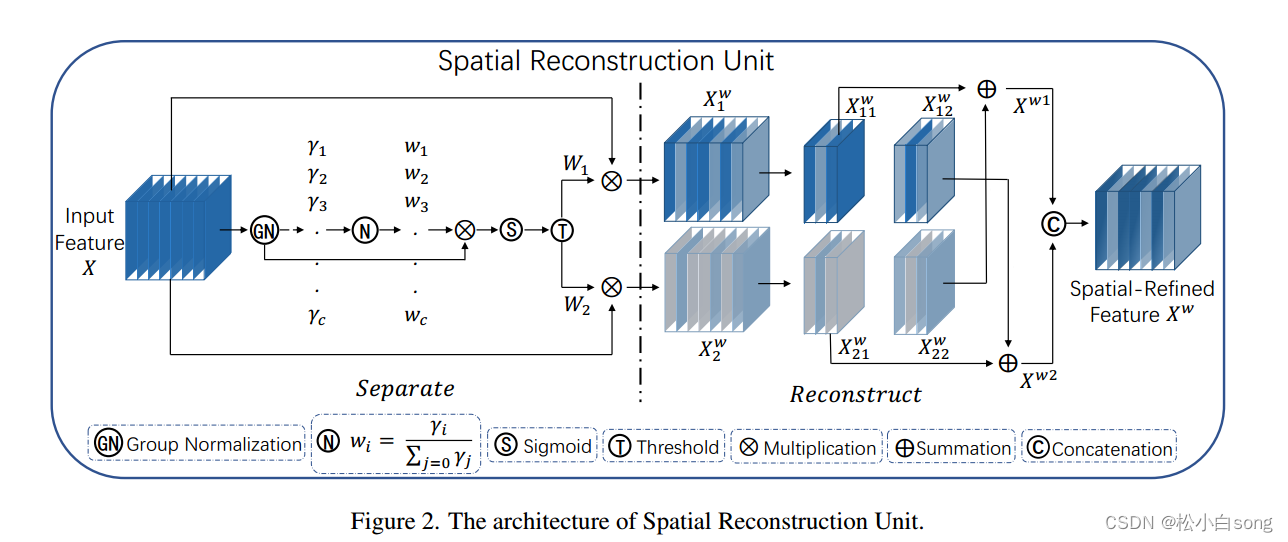
为了利用特征的空间冗余,我们引入了空间重构单元(SRU),如图2所示,它利用了分离和重构操作。分离操作的目的是将信息丰富的特征图与空间内容对应的信息较少的特征图分离开来。
2.3CRU for Channel Redundancy
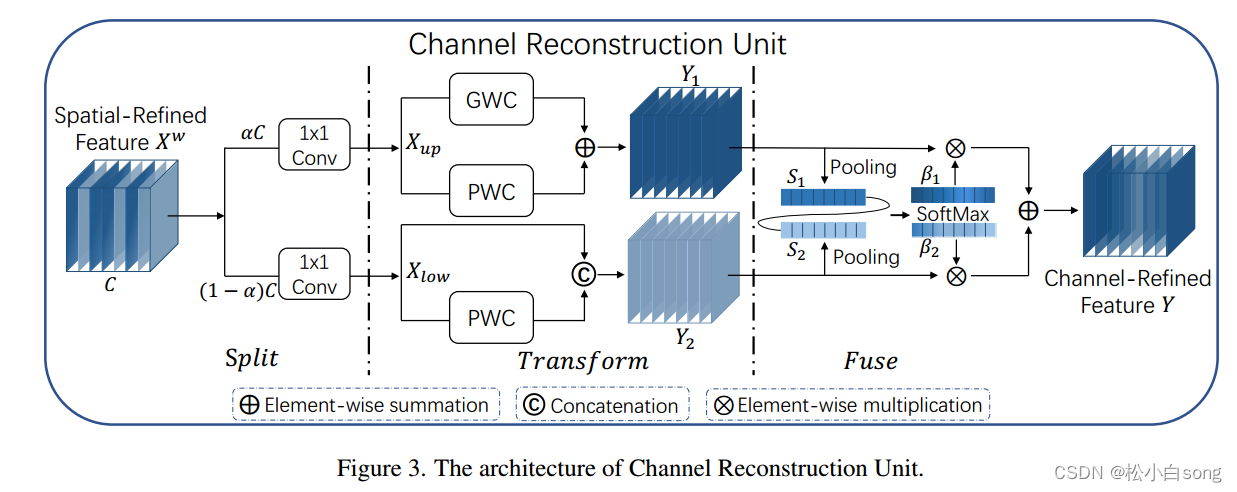
为了利用特征的信道冗余,我们引入了信道重构单元(CRU),如图3所示,它利用了分裂-转换-融合策略。
三、实验
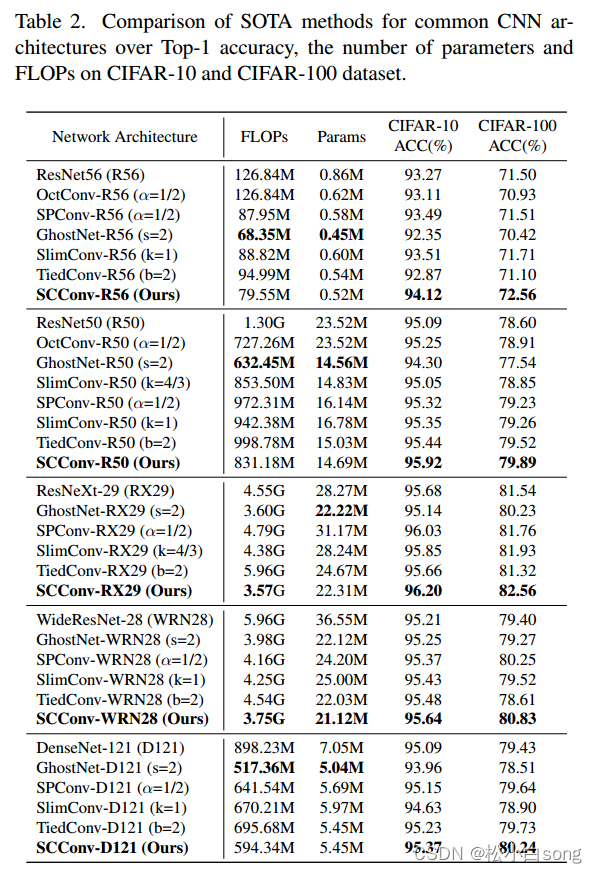
3.1基于CIFAR的图像分类
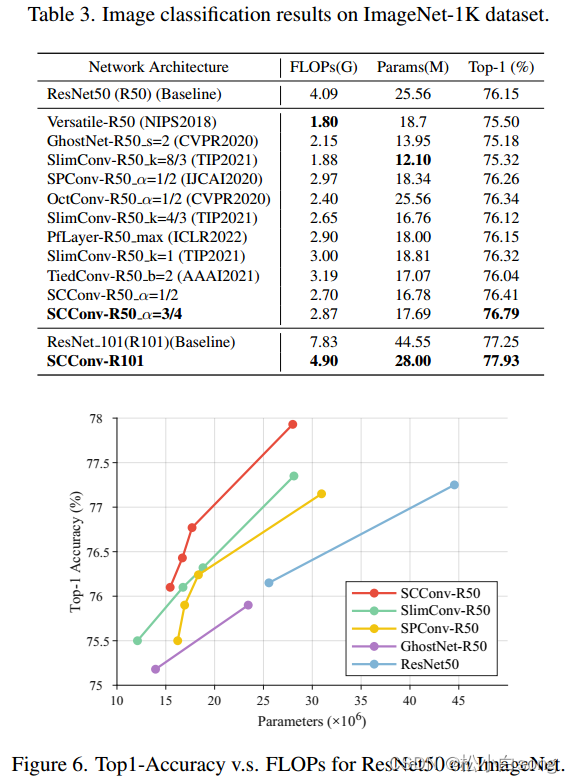
3.2基于ImageNet的图像分类
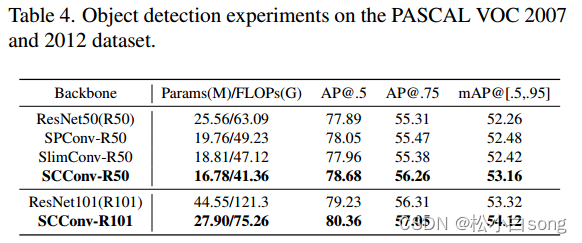
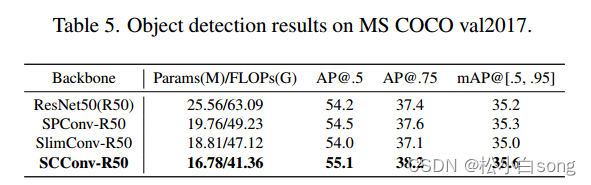
3.3对象检测
四、代码详解
import torch # 导入 PyTorch 库
import torch.nn.functional as F # 导入 PyTorch 的函数库
import torch.nn as nn # 导入 PyTorch 的神经网络模块
# 自定义 GroupBatchnorm2d 类,实现分组批量归一化
class GroupBatchnorm2d(nn.Module):
def __init__(self, c_num:int, group_num:int = 16, eps:float = 1e-10):
super(GroupBatchnorm2d,self).__init__() # 调用父类构造函数
assert c_num >= group_num # 断言 c_num 大于等于 group_num
self.group_num = group_num # 设置分组数量
self.gamma = nn.Parameter(torch.randn(c_num, 1, 1)) # 创建可训练参数 gamma
self.beta = nn.Parameter(torch.zeros(c_num, 1, 1)) # 创建可训练参数 beta
self.eps = eps # 设置小的常数 eps 用于稳定计算
def forward(self, x):
N, C, H, W = x.size() # 获取输入张量的尺寸
x = x.view(N, self.group_num, -1) # 将输入张量重新排列为指定的形状
mean = x.mean(dim=2, keepdim=True) # 计算每个组的均值
std = x.std(dim=2, keepdim=True) # 计算每个组的标准差
x = (x - mean) / (std + self.eps) # 应用批量归一化
x = x.view(N, C, H, W) # 恢复原始形状
return x * self.gamma + self.beta # 返回归一化后的张量
# 自定义 SRU(Spatial and Reconstruct Unit)类
class SRU(nn.Module):
def __init__(self,
oup_channels:int, # 输出通道数
group_num:int = 16, # 分组数,默认为16
gate_treshold:float = 0.5, # 门控阈值,默认为0.5
torch_gn:bool = False # 是否使用PyTorch内置的GroupNorm,默认为False
):
super().__init__() # 调用父类构造函数
# 初始化 GroupNorm 层或自定义 GroupBatchnorm2d 层
self.gn = nn.GroupNorm(num_channels=oup_channels, num_groups=group_num) if torch_gn else GroupBatchnorm2d(c_num=oup_channels, group_num=group_num)
self.gate_treshold = gate_treshold # 设置门控阈值
self.sigomid = nn.Sigmoid() # 创建 sigmoid 激活函数
def forward(self, x):
gn_x = self.gn(x) # 应用分组批量归一化
w_gamma = self.gn.gamma / sum(self.gn.gamma) # 计算 gamma 权重
reweights = self.sigomid(gn_x * w_gamma) # 计算重要性权重
# 门控机制
info_mask = reweights >= self.gate_treshold # 计算信息门控掩码
noninfo_mask = reweights < self.gate_treshold # 计算非信息门控掩码
x_1 = info_mask * x # 使用信息门控掩码
x_2 = noninfo_mask * x # 使用非信息门控掩码
x = self.reconstruct(x_1, x_2) # 重构特征
return x
def reconstruct(self, x_1, x_2):
x_11, x_12 = torch.split(x_1, x_1.size(1) // 2, dim=1) # 拆分特征为两部分
x_21, x_22 = torch.split(x_2, x_2.size(1) // 2, dim=1) # 拆分特征为两部分
return torch.cat([x_11 + x_22, x_12 + x_21], dim=1) # 重构特征并连接
# 自定义 CRU(Channel Reduction Unit)类
class CRU(nn.Module):
def __init__(self, op_channel:int, alpha:float = 1/2, squeeze_radio:int = 2, group_size:int = 2, group_kernel_size:int = 3):
super().__init__() # 调用父类构造函数
self.up_channel = up_channel = int(alpha * op_channel) # 计算上层通道数
self.low_channel = low_channel = op_channel - up_channel # 计算下层通道数
self.squeeze1 = nn.Conv2d(up_channel, up_channel // squeeze_radio, kernel_size=1, bias=False) # 创建卷积层
self.squeeze2 = nn.Conv2d(low_channel, low_channel // squeeze_radio, kernel_size=1, bias=False) # 创建卷积层
# 上层特征转换
self.GWC = nn.Conv2d(up_channel // squeeze_radio, op_channel, kernel_size=group_kernel_size, stride=1, padding=group_kernel_size // 2, groups=group_size) # 创建卷积层
self.PWC1 = nn.Conv2d(up_channel // squeeze_radio, op_channel, kernel_size=1, bias=False) # 创建卷积层
# 下层特征转换
self.PWC2 = nn.Conv2d(low_channel // squeeze_radio, op_channel - low_channel // squeeze_radio, kernel_size=1, bias=False) # 创建卷积层
self.advavg = nn.AdaptiveAvgPool2d(1) # 创建自适应平均池化层
def forward(self, x):
# 分割输入特征
up, low = torch.split(x, [self.up_channel, self.low_channel], dim=1)
up, low = self.squeeze1(up), self.squeeze2(low)
# 上层特征转换
Y1 = self.GWC(up) + self.PWC1(up)
# 下层特征转换
Y2 = torch.cat([self.PWC2(low), low], dim=1)
# 特征融合
out = torch.cat([Y1, Y2], dim=1)
out = F.softmax(self.advavg(out), dim=1) * out
out1, out2 = torch.split(out, out.size(1) // 2, dim=1)
return out1 + out2
# 自定义 ScConv(Squeeze and Channel Reduction Convolution)模型
class ScConv(nn.Module):
def __init__(self, op_channel:int, group_num:int = 16, gate_treshold:float = 0.5, alpha:float = 1/2, squeeze_radio:int = 2, group_size:int = 2, group_kernel_size:int = 3):
super().__init__() # 调用父类构造函数
self.SRU = SRU(op_channel, group_num=group_num, gate_treshold=gate_treshold) # 创建 SRU 层
self.CRU = CRU(op_channel, alpha=alpha, squeeze_radio=squeeze_radio, group_size=group_size, group_kernel_size=group_kernel_size) # 创建 CRU 层
def forward(self, x):
x = self.SRU(x) # 应用 SRU 层
x = self.CRU(x) # 应用 CRU 层
return x
if __name__ == '__main__':
x = torch.randn(1, 32, 16, 16) # 创建随机输入张量
model = ScConv(32) # 创建 ScConv 模型
print(model(x).shape) # 打印模型输出的形状五、总结
在本文中,我们提出了一种新的空间和信道重构模块(SCConv),这是一种有效的架构单元,可以降低计算成本和模型存储,同时通过减少标准卷积中广泛存在的空间和信道冗余来提高CNN模型的性能。我们使用两个不同的模块SRU和CRU来减少特征映射中的冗余,在减少大量计算负载的同时实现了相当大的性能改进。此外,SCConv是一个即插即用的模块,可以替代标准的卷积,不需要任何模型架构的调整。此外,各种SOTA方法在图像分类和目标检测方面的大量实验表明,scconvn嵌入模型在性能和模型效率之间取得了更好的平衡。最后,我们希望所提出的方法可以启发研究更有效的建筑设计。
参考:大佬

















 310
310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









