






一.人工智能的三个重要概念
1.人工智能(Artificial Intelligence, AI)
AI是计算机科学的一个分支,旨在创建能够模拟人类智能行为的系统,包括基于规则的专家系统、进化算法、机器人技术等。
分类:
- 弱人工智能(Narrow AI):专注于特定任务(如语音助手、图像识别)。
- 强人工智能(General AI):具备人类水平的通用智能,目前仍处于理论阶段
应用:自动驾驶、医疗诊断、智能客服等
2. 机器学习(Machine Learning, ML)
AI的子领域,通过算法让计算机从数据中自动学习规律,无需显式编程,模型性能与数据质量和规模直接相关。
- 学习方式:
- 监督学习:使用标注数据训练模型(如分类、回归)。
- 无监督学习:发现数据隐藏模式(如聚类)。
- 依赖数据:模型性能与数据质量和规模直接相关
- 应用:推荐系统、金融风控、垃圾邮件过滤
3. 深度学习(Deep Learning, DL)
基于多层神经网络自动提取数据的层次化特征
- 卷积神经网络(CNN):擅长图像识别(如ResNet)。
- 循环神经网络(RNN/LSTM):处理时序数据(如语音识别)。
- Transformer:推动自然语言处理(如GPT、BERT)
- 应用:人脸识别、机器翻译、生成式AI(如Sora)
优势:端到端学习,减少人工特征工程;劣势:需海量数据和算力
三者的关系:AI > ML > DL,类似俄罗斯套娃结构
二.算法的学习方式
1. 基于规则的学习
通过人工预先定义明确的逻辑规则或条件,直接指导系统行为,无需从数据中学习。
典型算法:专家系统、决策树(如ID3、C4.5)、模糊逻辑规则。
2. 基于模型的学习
从数据中自动学习规律,构建预测模型,通过参数(如权重、概率分布)泛化到新数据
典型算法:
监督学习:线性回归、支持向量机(SVM)
无监督学习:K-Means聚类、主成分分析(PCA)
强化学习:Q-Learning(无模型) vs. Dyna-Q(基于模型)
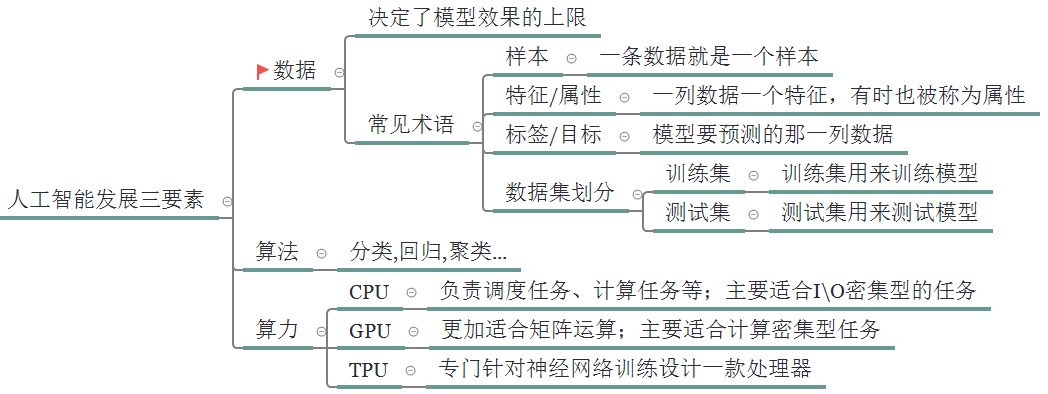
三.人工智能发展三要素
1.数据:海量、高质量的数据是训练AI模型的基础,涵盖结构化(如表格)和非结构化数据(如文本、图像)。
2.算法:从数据中提取规律的方法,包括传统机器学习(如SVM)和深度学习。
3.算力:支撑算法训练与推理的计算资源,包括GPU、TPU及云计算平台。
四.机器学习算法的分类
1.(有)监督学习:
有特征也有标签(结果驱动)
Ⅰ:分类任务:标签是离散的
Ⅱ:回归任务:标签是连续的
代表算法:决策树:通过树状规则分类(如保险续保决策)
随机森林:多棵决策树集成,提高准确性(如金融风控)
神经网络:深层结构处理复杂模式(如图像识别)
2.无监督学习
有特征无标签(数据驱动)
聚类任务
降维任务
异常检测任务
代表算法:生成对抗网络(GAN):生成逼真数据(如艺术创作)
自编码器:数据压缩与重建(如去噪图像)
3.半监督学习
有特征有部分标签
降低标注成本,提升效率
4. 强化学习
agent根据环境状态进行行动获得最多的累计奖励
有四要素:
agent
环境
行动
奖励
算法类型:值函数法:Q-Learning(离散动作)、DQN(Atari游戏)
策略梯度法:PPO(机器人控制)、SAC(连续动作空间)
五.机器学习建模流程
Ⅰ:获取数据:根据任务获取数据
Ⅱ:数据基本处理:缺失值,异常值处理
Ⅲ:特征工程:
利用专业背景知识和技巧处理数据,让机器学习算法效果更好(提升模型性能,增强可解释性,降低计算成本)
步骤:
1.特征提取:从原始数据中提取与任务相关的特征(主成分分析、线性判别分析)
2.特征预处理:将不同的特征数据转换成同一尺度,同一分布内(标准化,离散化)
3.特征降维:将原始数据的维度降低
4.特征选择:从特征中选择一些重要特征(过滤法,包裹法,嵌入法)
5.特征组合:把多个特征组合成一个特征
Ⅳ:模型训练
Ⅴ:模型评估
六.模型训练和评估
模型训练:从特征数据中学习到规律:通常是决策函数或条件概率分布
模型评估:
Ⅰ:拟合效果
欠拟合:模型在训练集上表现很差,在测试集上表现也很差
原因:模型过于简单,没有充分学习到规律
过拟合:模型在训练集上表现很好,在测试集上表现很差
原因:模型过于复杂,数据不纯,训练数据太少
合理拟合
Ⅱ:泛化: 模型在新数据集(非训练数据)上的表现好坏的能力
Ⅲ:奥卡姆剃刀原则:给定两个相同泛化误差的模型,较简单的模型比较复杂的模型更可取

















 1485
1485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









