







LLM-Transformer:经典与前沿方法详解
前言
大规模语言模型(LLM)是当前自然语言处理(NLP)领域的核心技术,而Transformer架构作为LLM的基础,极大地推动了这一领域的发展。本文将详细介绍LLM-Transformer的经典方法和最新进展,并提供相关论文的链接以便深入学习。
Transformer的基础概念
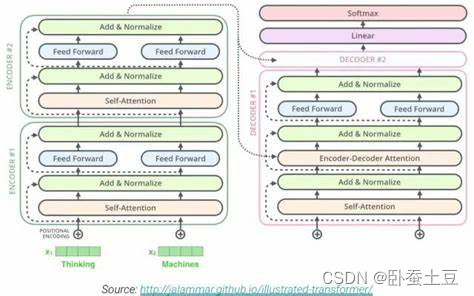
Transformer模型由Vaswani等人在2017年的论文《Attention is All You Need》中首次提出 。该模型引入了自注意力机制(Self-Attention),使得模型能够并行处理输入数据,从而显著提高了训练速度和效果。
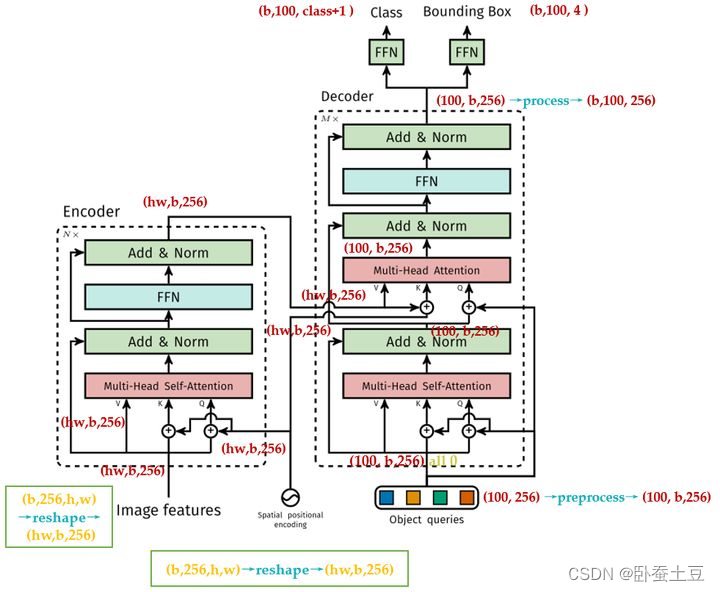
关键组件
- 多头自注意力机制(Multi-Head Self-Attention):通过多个注意力头,模型能够捕捉不同位置之间的依赖关系。
- 前馈神经网络(Feed-Forward Neural Networks):在每个注意力层后,使用前馈神经网络进行非线性变换。
- 位置编码(Positional Encoding):由于Transformer不具备内置的顺序信息,通过位置编码来保留输入序列的位置信息。
经典方法
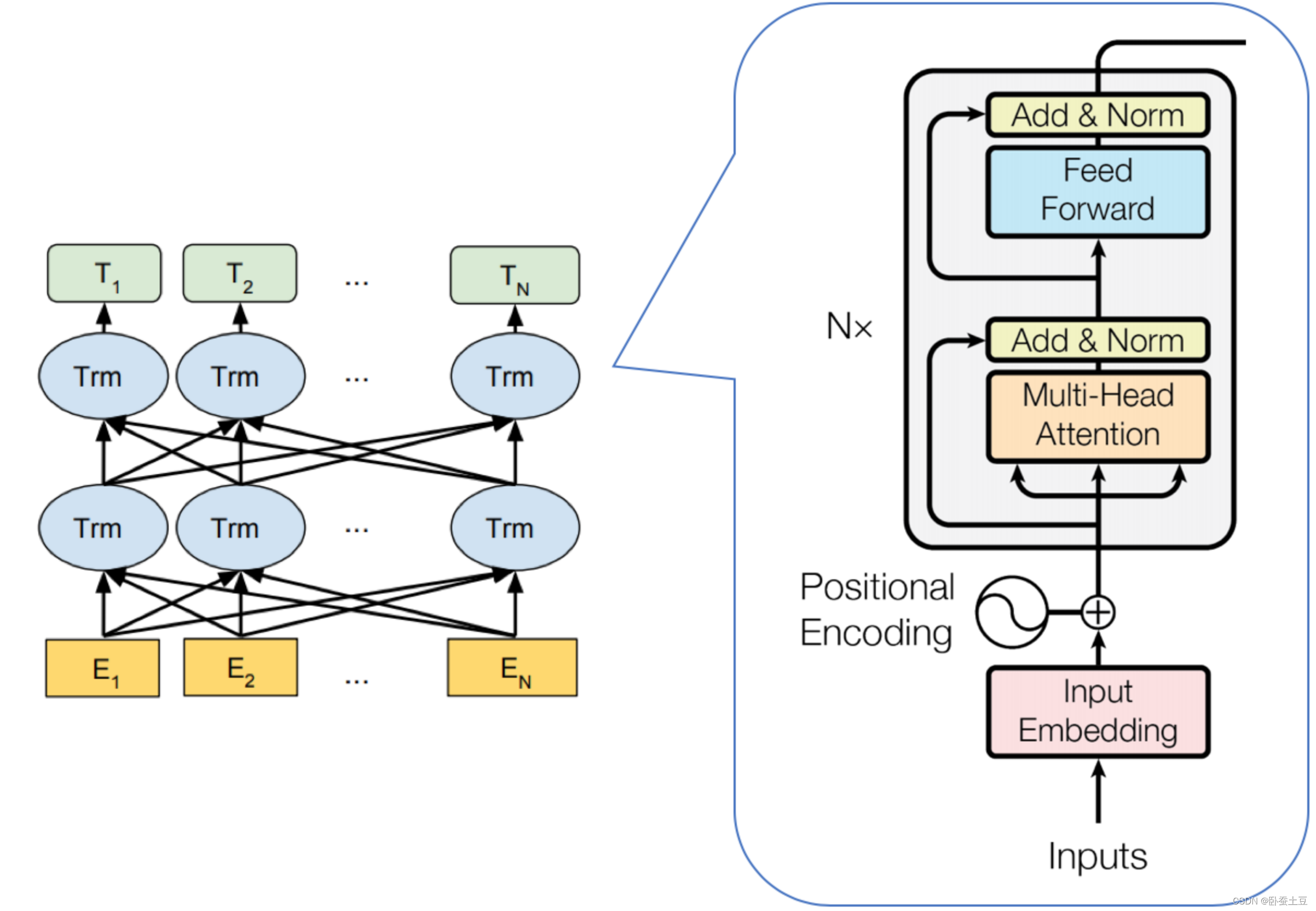
1. BERT(Bidirectional Encoder Representations from Transformers)
BERT由Devlin等人在2018年提出 。BERT通过双向编码器捕捉上下文信息,革新了多项NLP任务的效果。
- 预训练任务:
- 掩码语言模型(Masked Language Model, MLM):随机掩盖输入的一部分词语,要求模型预测被掩盖的词语。
- 下一句预测(Next Sentence Prediction, NSP):预测两段文本是否相邻。
2. GPT(Generative Pre-trained Transformer)
GPT系列模型由OpenAI开发,其中GPT-3在2020年发布,具有1750亿参数 。GPT模型主要基于解码器结构,侧重于生成任务。
- 预训练任务:
- 自回归语言模型(Autoregressive Language Model):通过前向传递依次生成序列中的下一个词语。
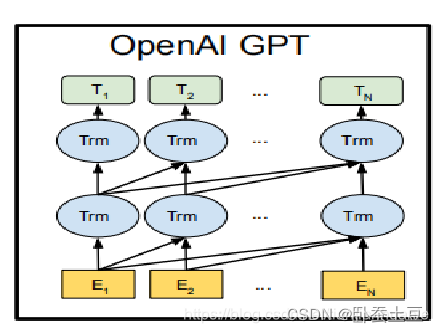
- 自回归语言模型(Autoregressive Language Model):通过前向传递依次生成序列中的下一个词语。
最新方法
1. T5(Text-To-Text Transfer Transformer)
T5由Google于2019年提出 。T5模型将所有NLP任务统一为文本到文本的格式,显著简化了模型设计。
- 预训练任务:
- 填空(Span Corruption):随机移除输入中的连续片段,并要求模型填补这些空白。
- 填空(Span Corruption):随机移除输入中的连续片段,并要求模型填补这些空白。
2. GPT-4
GPT-4是OpenAI最新发布的模型,具有更强的语言理解和生成能力。虽然具体的架构细节和参数量未公开,但其效果已经在多个领域得到了验证 。
3. Switch Transformer
Switch Transformer由Google在2021年提出,是一种高效的专家模型(Mixture of Experts, MoE),通过动态路由机制显著提高了模型的参数利用率 。
- 关键特性:
- 专家路由(Expert Routing):每个输入仅激活部分专家,从而大幅减少计算开销。
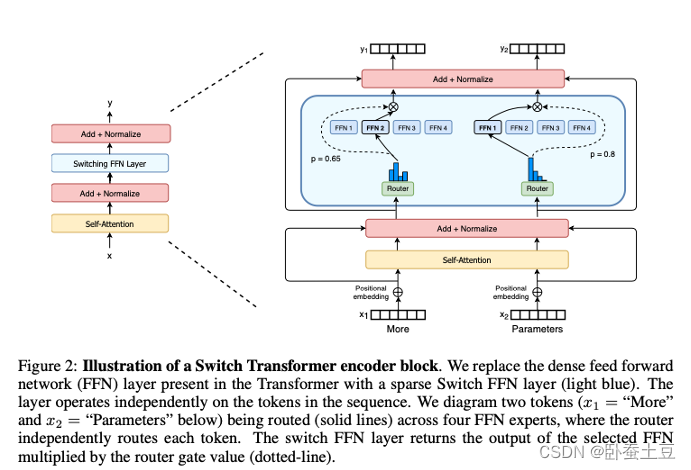
- 专家路由(Expert Routing):每个输入仅激活部分专家,从而大幅减少计算开销。
结论
Transformer架构及其衍生模型在NLP领域取得了卓越的成绩,从经典的BERT、GPT到最新的T5、Switch Transformer,这些模型不断推动着技术前沿。未来,随着模型结构和训练方法的进一步创新,LLM-Transformer将继续在更多应用场景中发挥重要作用。
参考文献
- Vaswani, A., et al. (2017). Attention is All You Need. 论文链接
- Devlin, J., et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. 论文链接
- Brown, T., et al. (2020). Language Models are Few-Shot Learners. 论文链接
- Raffel, C., et al. (2019). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. 论文链接
- OpenAI. (2023). GPT-4 Technical Report. 论文链接
- Fedus, W., et al. (2021). Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. 论文链接
希望这篇文章能帮助你更好地理解LLM-Transformer的经典方法和最新进展!















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









