






- 论文链接: https://arxiv.org/pdf/1409.1556.pdf
- 论文题目:VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
VGG-2014
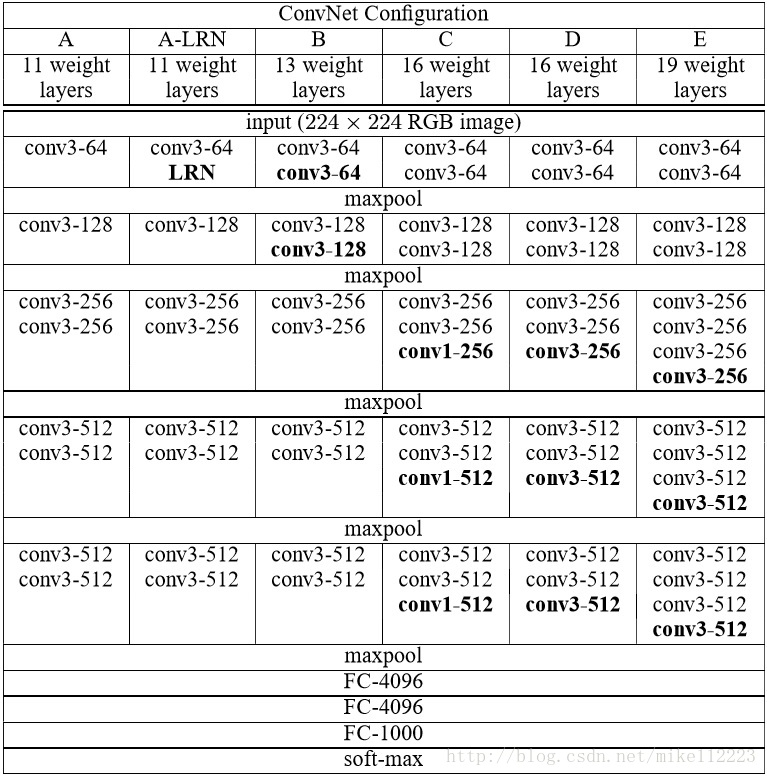
ConvNet configurations
Architecture
输入图像大小224x224。
唯一的数据预处理,是图像均值化(subtract the mean RGB value)。
图像经过一堆卷积层,使用3x3的卷积核(最小规格的卷积核来表征所谓左右,上下,中间)。只有一种网络配置会使用到1x1的卷积核,可以被视为输入通道的线性变换。卷积步长固定为1,通过padding使得图像大小得以不变。一共设置5个最大值池化层,跟在一些卷积层的后面,2x2的窗口,2的步长。
一堆卷积层后跟着3层全连接层,前两层4096,最后一层由于分类目标为1000,所以是1000。输出层运用softmax。
所有的隐藏层使用ReLU,五个网络中四个不使用LRN(只有一个使用),发现LRN的使用,并没有提高performance,反而增加memory和计算时间的消耗。
Configurations
一共给出了5个模型配置分别为A-E,所有的配置都基于上面的Architecture,唯一的区别就是深度,从A网络的11层(8层卷积+3FC)到E网络的19层(16层卷积+3FC)。卷积通道由一开始的64每经过一个池化层就翻倍,最后到512。

Discussion
这个ConvNet的配置和AlexNet-2012以及ZFNet-2013的网络配置有很大不同,在第一层卷积没有使用相对较大的感受野(AlexNet,11x11,4的步长,ZFNet,7x7,2的步长),而是在整个网络使用3x3的感受野进行卷积,而且步长为1。很容易可以发现2层3x3卷积的堆叠(没有池化在中间)就会拥有5x5的感受野,3层堆叠就有7x7的感受野。那么这样做和直接使用7x7卷积核的区别是什么呢?第一,使用了3次ReLU而并非一次,使得网络的决策更加精细有更强的区分性。第二,减少了参数个数,假设每层输入输出都拥有C个通道,3层3x3就有
3
(
3
)
2
C
2
=
27
C
2
3(3)^2C^2=27C^2
3(3)2C2=27C2个参数,而7x7单层会有
7
2
C
2
=
49
C
2
7^2C^2=49C^2
72C2=49C2个参数,整整多了81%,这同时也可以看作对于7x7单层卷积施加了正则化。
运用1x1的卷积核是一种在不影响卷积层感受野情况下增加决策函数非线性的一种方式。尽管在本网络中,1x1卷积只是同维度空间上的线性映射(输入输出通道数相同),但同时它还经过了一次ReLU,增加了非线性,使网络拥有更强的表达能力。
网络的深度非常有必要,小卷积核之前有研究者使用过,不过由于网络深度不够,并没有取得很好的成果。
Classification Framework
Training
采用带momentum的mini_batch梯度下降算法,batch_size为256,momentum为0.9。
采用了weight decay,L2惩罚算子为0.0005。
采用了dropout在前两层全连接层中,ratio为0.5。
learning rate初始值为0.01,当valid error停住,lr衰减10倍。
最终lr衰减了三次,算法总共跑了370K的循环(74个epochs),相比较于AlexNet,尽管有着更多的参数和更深的网络,但是却更快的完成了收敛,原因:
- 由更深的网络和更小的卷积核带来的隐式的泛化效果。
- 对于相应层的预初始化。
网络权重的初始化非常重要,因为糟糕的初始值会减缓学习,因为梯度在深度网络中的不稳定性。为了解决这个问题,我们从网络A开始,因为它足够浅,所以完全可以使用随机初始化。然后当训练更深的网络的时候,将网络的前四层卷积层和最后三层FC层用相应的网络A的权值来初始化(额外的中间层采用随机初始化),随机初始化采用0均值,0.01方差的高斯分布,biases都初始化为0。在论文已经提交之后,发现可能可以使用下面论文中的随机初始化方式来代替本篇的预训练。
https://www.researchgate.net/publication/215616968_Understanding_the_difficulty_of_training_deep_feedforward_neural_networks
同样地为了获得224x224的ConvNet输入图像,进行随机裁取。为了增广数据集,进行随机水平翻转,RGB通道调节。
总结
相较于AlexNet,VGG没有使用LRN和overlap pooling,而是强调了网络深度以及小卷积核带来的网络更好的表达能力以及泛化效果,同样也使用了带weight decay和momentum的mini_batch下降算法。还引入了预训练来完成参数初始化。















 939
939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









