






CNN的优化,大概分为两类,一类是在深度上做文章,一类是在宽度方面设计改进。早期的CNN优化,基本都是对深度的向下挖掘,增加深度确实可以非常有效的增加模型的效果,但同时也会带来一些非常明显的问题,如梯度消失、参数爆炸等等。2014年的ILSVRC的前两名,可以说是在两方面分别做了优化改进,并且都取得了非常好的效果。
论文链接:VGG,GoogLeNet
一、网络加深的"始作俑者",VGG
当然,这个称谓并不是很合适,但是VGG确实是在简单的深度学习网络结构下(用ResNet里面的话说,就是Plain结构,没有任何分支,只有一条pipeline),最先开始尝试进行网络的加深,并且做到了很好。
VGG加深网络的方式很简单,就是用小的卷积核(3×3),代替之前各种模型中的较大的卷积核(11×11,7×7,5×5),同时保持原有卷积操作的规模。比如用两个3×3,代替一个5×5的卷积核,这样参数数量降低到了原有的3×3×2/5×5=72%;三个3×3,代替一个7×7的卷积核,这样参数数量降低到了原有的3×3×3/7×7=55%,更大的卷积核同理可以推出来。
VGG一共提出了A~E五个模型,深度从11层到19层不等,其中VGG16和VGG19算是目前比较广泛使用的。不管多少层,结构都是三层全连接,加上上层的N-3层卷积。

其实VGG并不复杂,核心思想也是用小的卷积核代替大的卷积核,一方面可以降低参数量;一方面可以加深网络,增加网络的表达能力。另外,小的卷积核意味着小的感受野,能够识别出来的细节就会更多(跟表达能力算是一个意思吧)。
二、另辟蹊径的GoogLeNet
相较于VGG,GoogLeNet达到了更深的网络层数,但是网络相对来说也比较复杂。GoogLeNet是来自Google公司的作品,获得了ILSVRC14的冠军,不管叫Inception也好,还是GoogLeNet也好,名字都是很有深意的。Incetion是GoogLeNet中的核心模块,类似于ResNet中的残差模块。
其实从CNN出现,大家都一直在努力从单纯的深度入手,增加模型的准确度,每一层就是不停的堆叠卷积模块,就像是VGG的那种plain结构。而这篇论文分析了CNN在分类过程中出现的一些问题之后,从问题出发,对整个模型的深度和宽度都做出了一些改进,同时有效降低了参数量。
什么问题呢,传统的CNN在分类、检测等任务上,对于不同大小的相同物体,检测的准确率会有比较大的差别。同样是一只汪,在照片中占比例比较大的,和在照片中占比例比较小的,在分类和检测的准确率会有差别。这是因为CNN固定的卷积核大小造成的,固定的卷积核大小意味着固定的感受野,也就意味着卷积核对于图片中不同大小区域的处理能力不同。大的感受野意味着能更好的识别出大的物体,小的感受野意味着能识别出来更多的细节。


因此,GoogLeNet中提出了,在同一层卷积中,并行的使用多个不同大小的卷积核(1×1,3×3,5×5),来增强整个框架的特征提取能力。另外,还在同一层并行加入了一个最大池化(max pooling),这也是遵循了当前绝大多数CNN中都会在卷积后面加入一个非线性激活函数的架构,只不过在这里,最大池化与卷积的关系是平行的。下图就是这个结构的原始版本,也就是Inception模块。输入图片会并行的经过三个卷积核(1×1,3×3,5×5),和一个最大池化,最后这四个结果的输出concat到一起,形成这一层的输出。
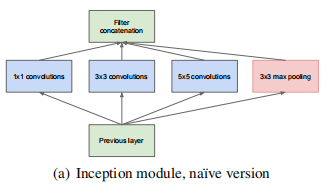
问题又来了,这个结构确实是增加了不同大小的感受野,但是在传统的CNN上,即便只有一个5×5的卷积核,计算量也是非常大的,更何况上图Inception这种包括了5×5在内的多个卷积核。这就产生了对于初始版本的优化版本,对于每一个卷积操作,在不影响输出维度的情况下,在执行卷积之前先使用一个1×1的卷积核对输入进行降维,这样可以大大降低整个网络的参数量。优化之后的Inception模块如下:
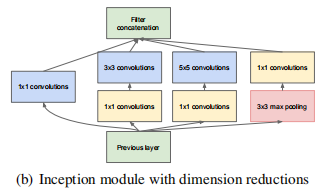
在Inception模块的输出后,有时候会跟着一个max pooling,把特征图缩小一半。GoogLeNet就是以Inception模块为基础构成的网络,浅层的网络还是直接使用卷积操作来提取特征,到了深层的网络,开始使用Inception模块。GoogLeNet一共有22层(如果计算池化层,就有27层,一般来说池化层不计入层数),网络最后一层是一个全连接层,文章表示这是为了其他任务用这个网络的预训练模型来微调自己的网络。训练过程中,在网络的中间位置,会有额外的分类器输出,这部分输出的结果,计算loss,乘以一个相对较小的权重(0.3),最后加在总的loss中,文章解释这样做的原因是因为深层网络的中间部分对于分类的任务来说也是相当重要的,所以要对网络的中间层进行一些处理,在测试时,这些从网络中间拉出来的分类器就不会用了。网络结构图如下(太长了,需要的可以直接去看论文里的图):
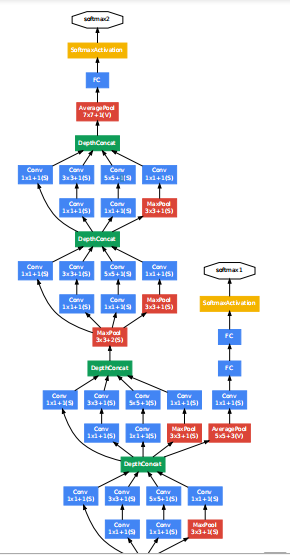
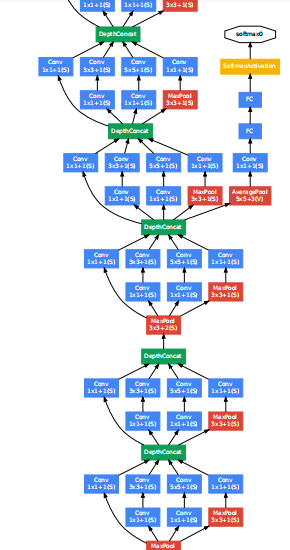
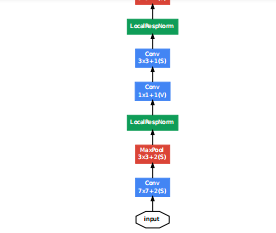

网络开始是3层传统的卷积,分别为7×7,1×1,3×3,然后下面就是9个Inception模块(9×2层),其中拉出来两个分类器,最后用了一个全连接层,总共3+9×2+1=22层。
















04-08
 1880
1880
1880
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









