







ConvNets Typical Architecture与VGGNet
ConvNets Typical Architecture-卷积神经网络经典结构
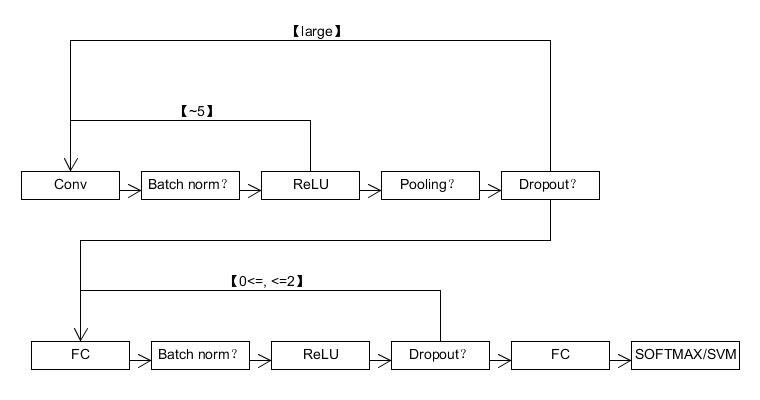
写到这里,小编已经大体覆盖了构建一个大型卷积神经网络所需要的知识点。下面是小编在上课是总结的卷积神经网络的结构。
读者是不是觉得上面的图的那些英文都似曾相识,是的,小编在之前的学习笔记中都有介绍,为了方便读者阅读,下面小编给出相应的链接
Conv与Pooling:http://blog.csdn.net/u012767526/article/details/51418288
Batch norm:http://blog.csdn.net/u012767526/article/details/51405701
FC与ReLU:http://blog.csdn.net/u012767526/article/details/51399596
Dropout:http://blog.csdn.net/u012767526/article/details/51407443
SOFTMAX/SVM:http://blog.csdn.net/u012767526/article/details/51396196
一个深度神经网络一般有以下两部分构成:
- 卷积部分
- 全连接部分
卷积部分
我们这里称Conv-Batch norm-ReLU为一个Conv Layer。一般这一部分是由大量的Conv Layer级联构成,其中掺杂如Pooling也Dropout这些层。一般大约5个Conv Layer之后会有一个Pooling层,然后Dropout层必须放在Pooling层之后,当然这两个层都是可选的。
全连接部分
全连接层的要求一般不高,而且现在的趋势是尽可能的去掉全连接层(ResNet和GoogLeNet里面都已经很难看到全连接层的身影了…)。全连接部分典型的结构是FC-Batch norm-ReLU-Dropout的组合,这种组合一般不会超过两个,然后再最后通过一层FC就算结果,再把结果传递给LOSS Function(这里根据需要可以有相应的选择,多数情况下是SOFTMAX)。
深度学习网络结构发展趋势
- 展度更小的过滤器(比如1*1, 3*3, 1*3, 3*1之类的)
- 更深的网络(AlexNet, ILSVRC 2012,8层->VGG, ILSVRC 2014, 19层->ResNet, ILSVRC 2015, 152层!)
- 摆脱Pooling和FC层,只保留Conv
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1049
1049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









