







概要
【理想汽车2024智能驾驶夏季发布会】 https://www.bilibili.com/video/BV1A4421U7rW/?share_source=copy_web&vd_source=5710b01ad09d526e60983a7ed0b99971
架构演进
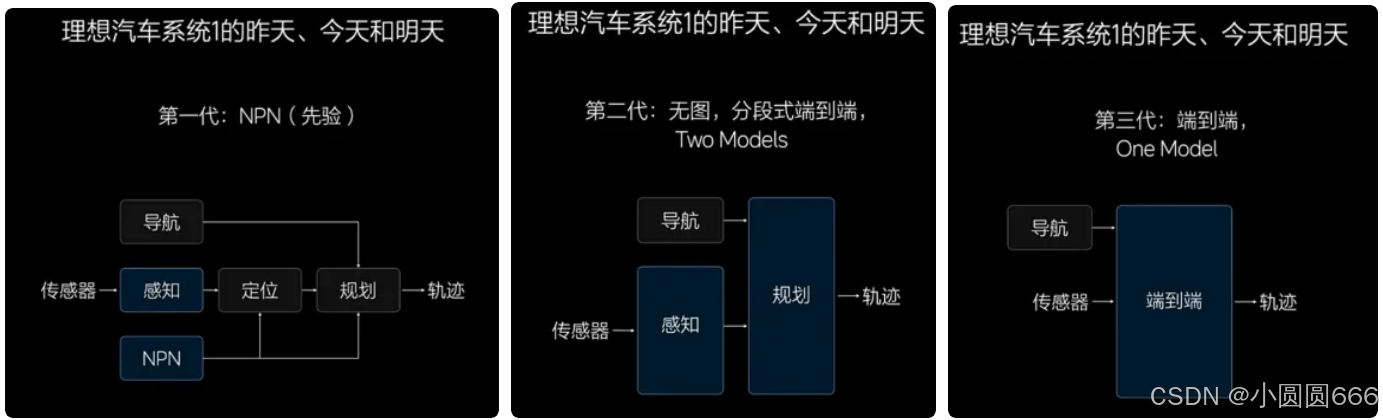
第一代是架构,理想的NPN架构,模块化,有感知、有定位、有规划、有导航、有NPN,中间拿规则串在一起。理想在全国100个城市交付了城市NOA。
第二代架构,无图NOA,只有两个模型了,感知和规划,中间也是拿规则串在一起。不用等先验信息更新,全国都可以开。
第三代架构,4D one model 端到端,只有一个模型,它的输入和传感器输出是我们的行驶轨迹。
整体架构流程
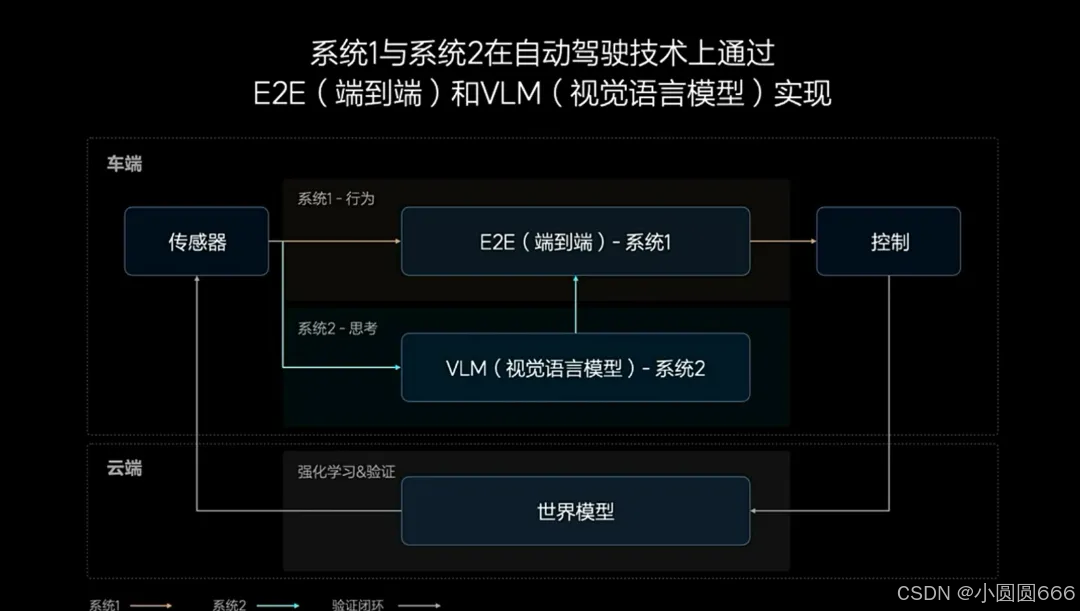
快系统,即系统1,善于处理简单任务,更像人类基于经验和习惯形成的直觉,足以应对驾驶车辆时95%的常规场景。系统1由端到端模型实现快速响应,端到端模型接收传感器输入,并直接输出行驶轨迹用于控制车辆。
慢系统,即系统2,则是人类通过更深入的理解与学习,形成的逻辑推理、复杂分析和计算能力,在驾驶车辆时用于解决复杂甚至未知的交通场景,占日常驾驶的约5%。系统2由VLM视觉语言模型实现,其接收传感器输入后,经过逻辑思考,输出决策信息给到系统1。
双系统构成的自动驾驶能力还将在云端利用世界模型进行训练和验证
系统1,端到端模型
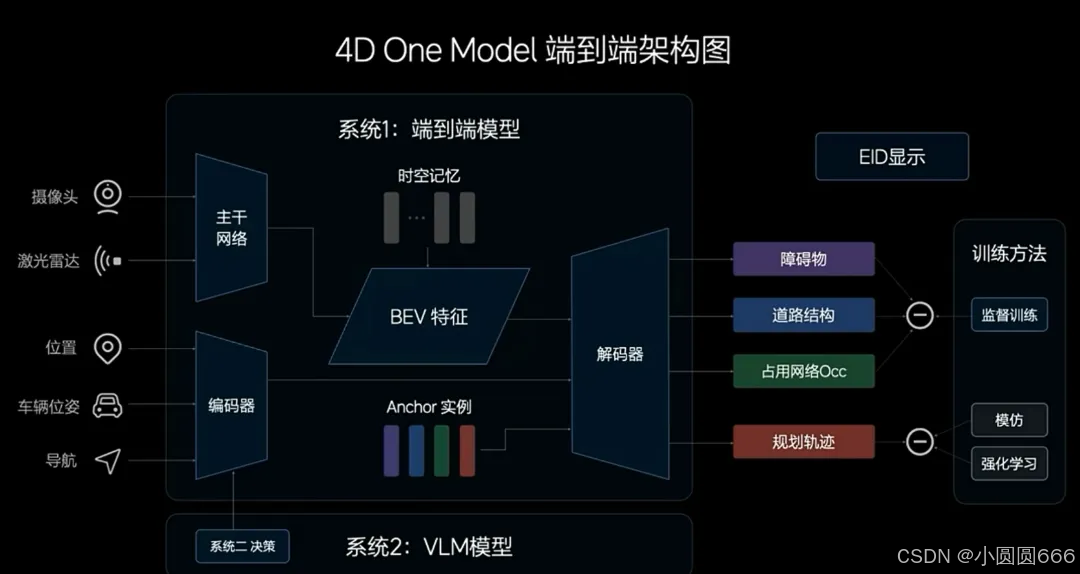
左上半部分,输入是常规的传感器,包括摄像头和激光雷达。进入到了专门为Orin-X优化过CNN主干网络,然后提取他们的特征并融合在一起。为了增强BEV空间这个特征的表达能力,我们加入了一些记忆模块,它不仅仅有时序上的记忆,还有空间上的记忆。
左下半部分,额外设计了另外两个输入。第一个是自车的这个状态信息,第二个是导航信息。前方有2公里的这个导航信息,包括我们听到的一些语言文字,比如说前方300米左转,类似这样的都会输入,拿到数据比较远。
那这个时候信息进入到我们我们的一个Transformer的编码器之后,和我刚才提到加强后的BEV特征一起解码出了四个东西,动态障碍物、道路结构,OCC,规划出我们的行驶轨迹。
除了行驶轨迹的另外三个感知任务,把我周边的环境描绘出来,然后通过EID呈现给用户,让用户能看到。另外,作为整个端的模型的辅助监督任务。这样可以加速我的行驶轨迹的收敛,可以在更短的时间内训出一个更好的模型。
系统2,VLM视觉语言模型
统一的transformer解码器,里面的参数量是非常大。将文本的prompt进行Tokenizer编码,然后输给这个解码器。然后同时把30度相机,120度相机的图片以及导航地图的图像进行视觉编码。
然后送给这个模态对齐模块,对齐后的信息也交给这个解码器,最后一起自回归的输出。
系统二的输出包含:对环境的理解、驾驶的决策建议、驾驶的参考轨迹,这些都是可以给到系统一帮助辅助驾驶策略的。
大模型部署提升
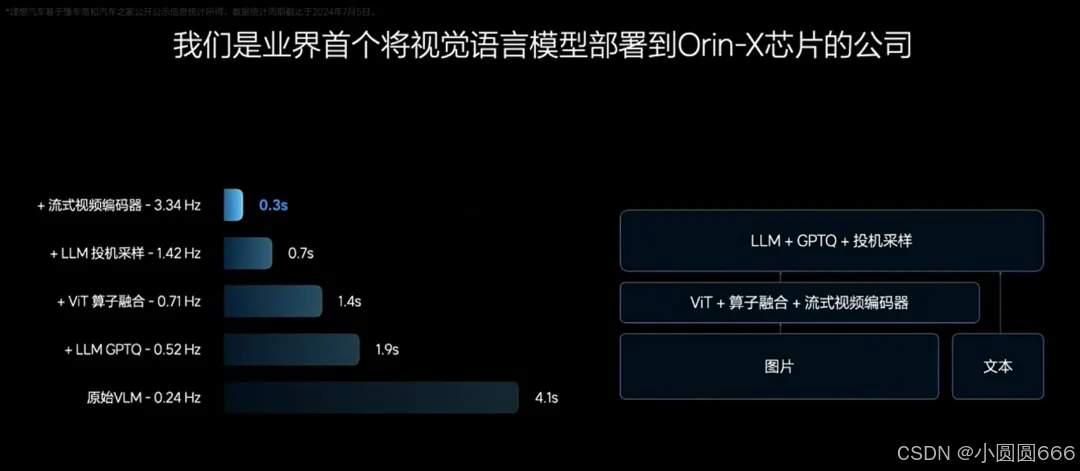
22亿的参数部署到车端芯片的措施:
- 开始把大模型放在Orin-X部署,推理时间长达4秒
- 把大模型先进行量化,减少带宽的一个瓶颈,魔改了GPTQ,在Orin-X上实现了性能的提升,推理时间从4秒钟降到了1.9秒
- 视觉ViT的推理,和英伟达在最新的DriveOS上,实现了更好的Tensor的算子融合,对attention算子进行了深度优化,从1.9秒提升到了1.4秒。
- 自回归的推理,采用投机采样(大模型在一次推理过程中能连续输出多个token),从1.4秒降到了0.7秒。
- 流式的视频流推理,这样使重复的视觉计算得到大大的缓解。我们最后达到0.3秒的一个推理性能
仿真测试
闭环仿真系统三种路线
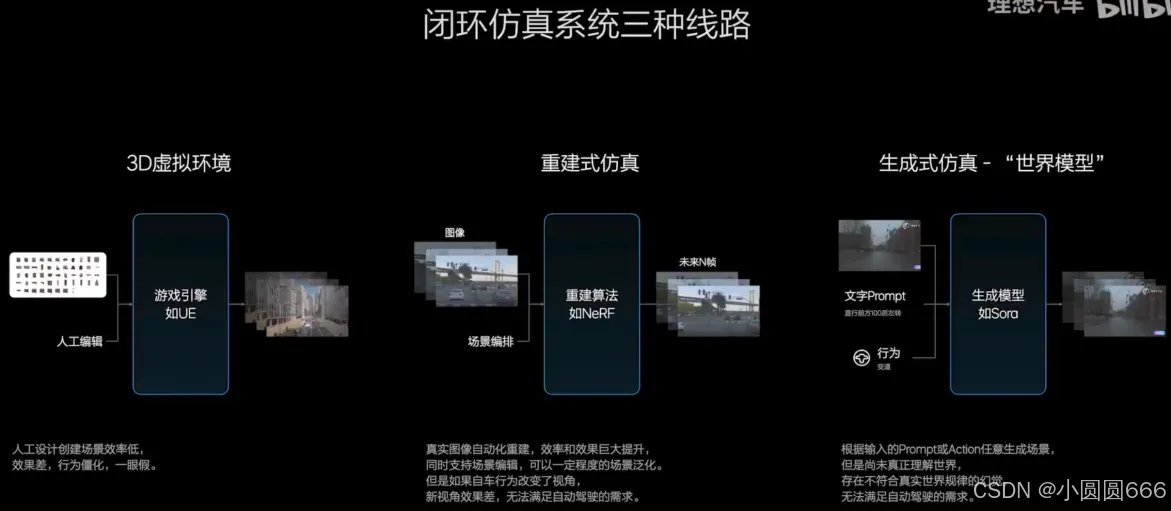
第一种就是3D仿真,把3D的资产或者3D的模板,人工编辑排版,然后生成场景,最后通过游戏引擎渲染出来了。缺点:场景一眼假、效率低。
第二个是真实数据的重建,把大量的真实数据通过NeRF或者3DGS这样的技术,自动化的重建出来。优点:整体效率,比3D仿真这种要快的多。光照材质,然后行为这些都会真实的。缺点:把自动驾驶的系统接入进去作为闭环仿真的时候,如果本车跟原来的车的这个行为差异比较大,视角变化很大。那新视角下重建的时候场景会出现模糊拖影这样的现象,也没办法完全满足自动驾驶的需求。
第三种生成式,利用diffusion技术然后加上prompt,形成这种各种各样的场景。缺点:世界模型或者生成模型,它最大的问题是它没有真正的理解世界。所以它存在很多不符合规律的这种幻觉的问题,也没办法完全满足自动驾驶的需求。
理想方案提升
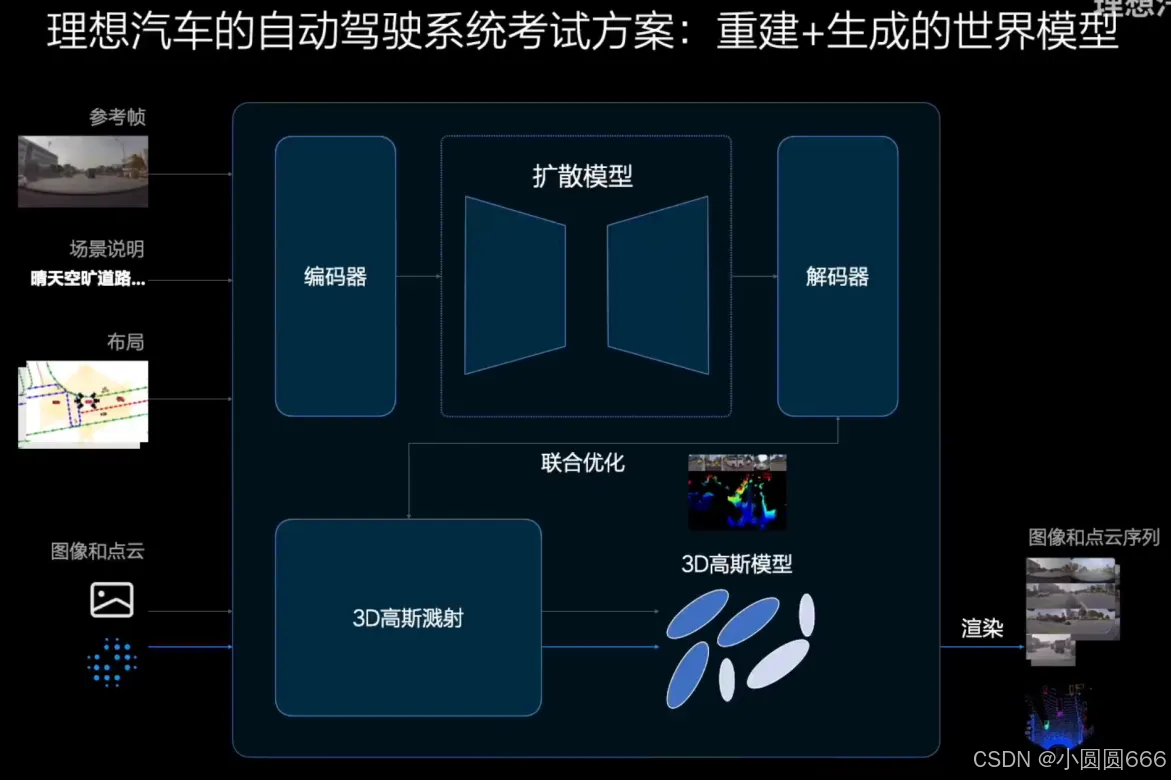
理想:重建加生成结合的世界模型的方式
下半部分,GS重建的过程,利用真实数据的先验,给出layout做约束,然后再加上prompt,再给一些这种参考图片,生成新的视角。优点:①如果转换新视角,它也不会出现之前模糊的这个问题;②生成的部分它可以独立的运行。那有了这种layout的先验,再加上这种Reference的图片,再加prompt,其实可以生成很多符合真实世界规律,但是没见过的场景。它的泛化性会更好。
通过分离视频中的动态和静态元素,利用3DGS算法对静态背景建模,并对动态部分进行360度新视角生成,最后将两者结合创建出一个可操控的3D物理世界。在这个世界中,可以自由移动视角,调整动态障碍物的位置和轨迹,为系统测试提供了良好的泛化能力。
生成模型比单纯的重建拥有更好的泛化性,能够控制天气、时间、车流等变量,生成多样化的场景来测试模型的适应性和泛化能力,实现了“15秒经历一年四季”的效果。这些技术不仅为自动驾驶技术的学习和评估提供了无限的环境,还保证了最终软件产品的高效性、安全性和舒适性。

















 1393
1393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









