







觉得总结的不错,所以记录一下。
原文:http://distill.pub/2016/augmented-rnns/
译文:http://geek.csdn.net/news/detail/106118
递归神经网络是一种主流的深度学习模型,它可以用神经网络模型来处理序列化的数据,比如文本、音频和视频数据。它能把一个序列浓缩为抽象的理解,以此来表示这个序列,乃至新产生一个序列。
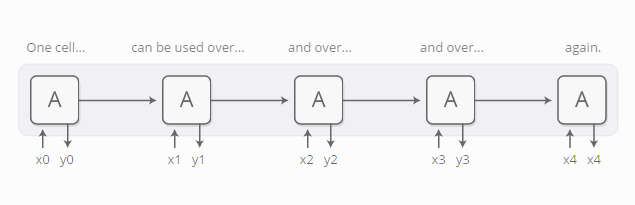
基本的RNN网络设计对长序列串往往束手无策,但是它的特殊变种 —— “长短期记忆模型(LSTM)” —— 则能处理这些数据。这类模型被认为非常强大,在许多类别的任务上取得了显著的成绩,包括机器翻译、语音识别、和看图写话等。因此,递归神经网络在过去几年内变得非常流行。
随着递归神经网络的流行,我们看到人们试图用各种方法来提升RNN模型的效果。其中,有四个方向的改进效果比较显著:
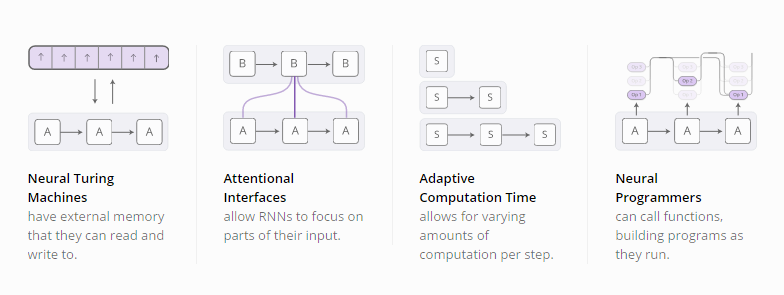
这些技术都是RNN模型可能的扩展方向,但真正让我们兴奋的是可以将这些技术都合并起来,就像是更广阔空间中的一些点聚合。而且,这些技术所基于的底层技术都相同 —— 被称作聚焦机制(attention)。
我们猜测这些“增强神经网络”在今后几年内对于拓展深度学习的能力将会扮演重要的角色。
神经图灵机器
神经图灵机器(Graves, et al., 2014)将RNN模型与一个外部记忆模块结合。由于向量表达是神经网络界的自然语言,所以记忆的是一组向量值:
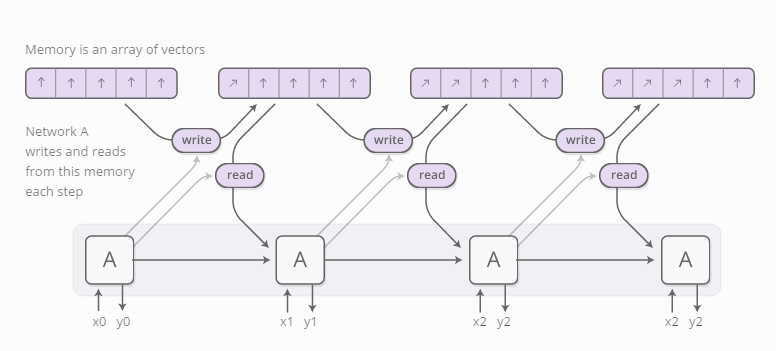
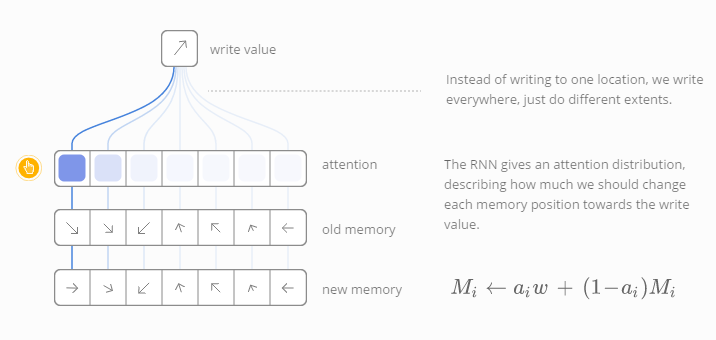
但是,读和写的过程又是怎样的呢?这里的挑战在于我们想区分这两个过程。具体说来,我们想区分读和写的区域,那么我们就能学会从哪儿去读取,写入到什么位置。由于存储地址本质上是离散化的,因此这个问题比较棘手。神经图灵机器采用了一种非常聪明的解决方案:它们在每一步以不同的程度来读和写各个位置。
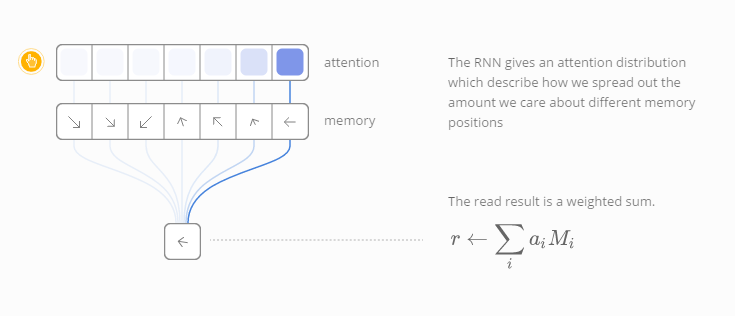
以读取为例,不同于指定一个位置读取,RNN模型给出了“聚焦分布(attention distribution)”,描述了我们对不同记忆位置的关注程度。因此,读取操作是带权重的累加。
同样的,我们每次以不同的程度写入内容。聚焦分布描述了我们在每个位置的写入量。记忆单元中某个位置的新值是旧的记忆内容与新写入内容的组合,它们之间的位置由聚焦权重所决定。
但是,神经图灵机器是如何决定需要聚焦在哪一块记忆区域呢?事实上,它们结合了两种不同的方法:基于内容的聚焦和基于位置的聚焦。基于内容的方法让神经图灵机器搜索遍历它们的记忆库,然后关注在与内容相符合的区域,而基于位置的方法则允许在记忆区域的相对运动,使得神经图灵机器可以循环。
这种读写能力使得神经图灵机器可以进行很多种简单的运算,超越了普通神经网络的能力。比如,它们可以学习记忆一段长序列,然后不断地循环重复。随着它们不断地循环,我们能观测到它读写的位置,能够更全面地理解其工作原理:
它们还能学习模仿查询表,甚至学习对数字排序!然而,它们却无法完成许多基本任务,比如加法或者乘法运算。
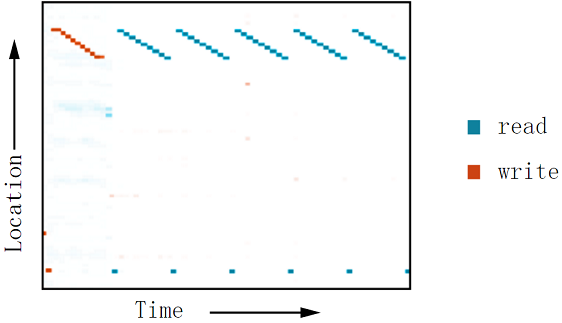
Graves, et al., 2014文中介绍了大量的实验。这张图片展现了“重复复制”的实验。
自最初的神经图灵机器论文发表之后,在这一领域方向又涌现出了大量优质论文。神经GPU(Kaiser & Sutskever, 2015) 克服了神经图灵机器无法计算加法和乘法的缺陷。Zaremba & Sutskever, 2016采用强化学习的方法训练NTM。神经随机访问机器(Neural Random Access Machines Kurach et al., 2015)基于指针运行。一些论文尝试了不同的数据结构,比如堆栈和队列(Grefenstette et al. 2015; Joulin & Mikolov, 2015)。记忆网络(Weston et al., 2014; Kumar et al., 2015)是解决类似问题的另一种方式。
这些模型能解决的任务并没有太复杂,比如数字的相加,传统的程序就能轻而易举地解决。但神经网络模型不仅局限于此,例如神经图灵机器在能力上有了深远的突破。
代码
这些模型有许多开源的实现版本。神经图灵机器的开源实现版本有Taehoon Kim’s (TensorFlow), Shawn Tan’s (Theano), Fumin’s (Go), Kai Sheng Tai’s (Torch), and Snip’s (Lasagne)。神经GPU论文的代码已经开源,合并到了 TensorFlow模型代码库。记忆网络的开源实现有Facebook’s (Torch/Matlab), YerevaNN’s (Theano), and Taehoon Kim’s (TensorFlow)。
聚焦的接口(Attention Interface)
在翻译句子时,我们会尤其关注当前正在翻译的词语。在转换语音记录时,我们会集中注意认真聆听正在书写的片段。如果你让我描述我所在的屋子,我肯定会瞥一眼正在描述的屋内物品。
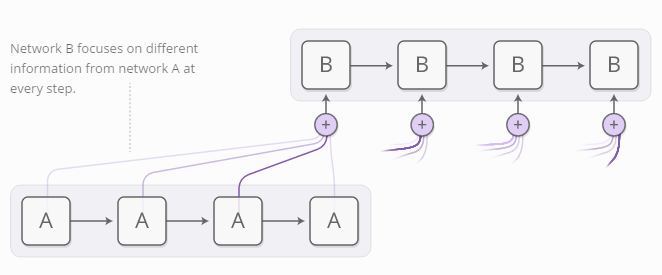
神经网络模型可以使用聚焦来实现同样的动作,专注于所提供信息的某一部分。例如,一个RNN模型可以输入另一个RNN模型的输出。它在每一步都会关注另一个RNN模型的不同位置。
我们希望聚焦点是可区分的,从而能学会需要关注哪些位置。因此,我们借用了神经图灵机器的技巧:关注所有位置,只是程度不一样。
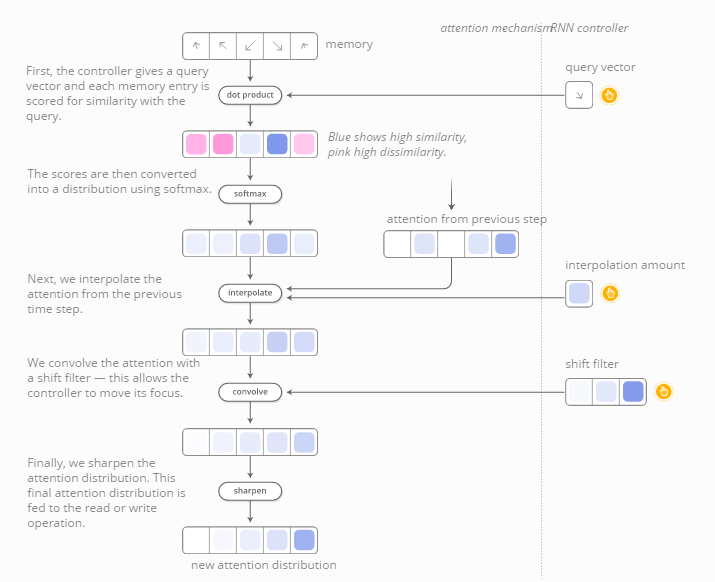
聚焦分布通常是由基于内容的聚焦产生。RNN模型生成一个搜索词描述其希望关注的位置。然后计算每条内容与搜索词的点乘得分,表示其与搜索词的匹配程度。这些分数经过softmax函数的运算产生聚焦的分布。
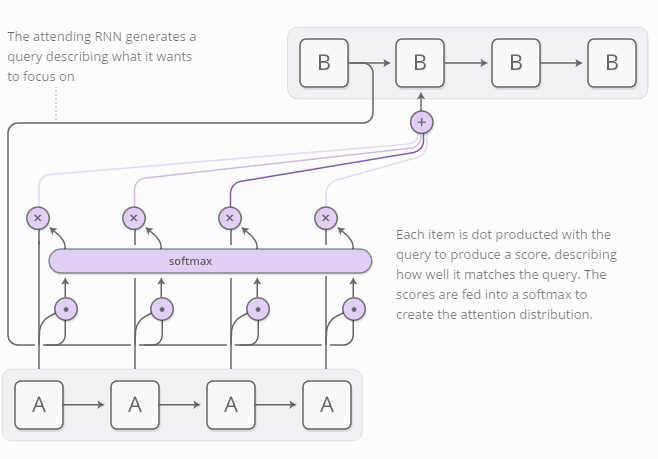
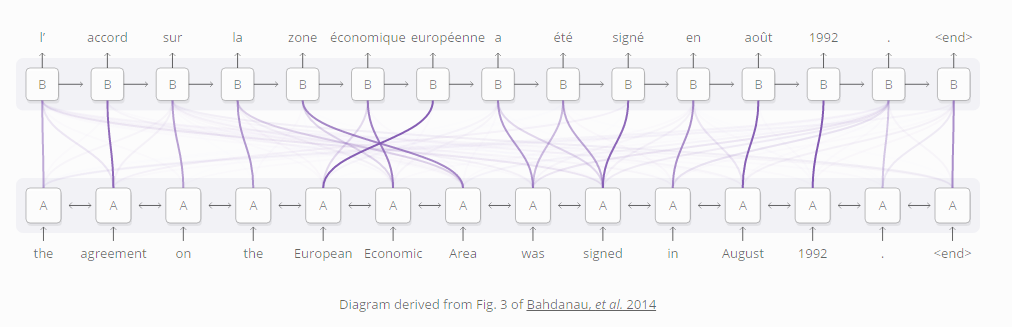
聚焦机制在RNN模型的使用场景之一是语言翻译(Bahdanau, et al. 2014)。若用传统的序列到序列模型做翻译,需要把整个输入词汇串缩简为单个向量,然后再展开恢复为序列目标语言的词汇串。聚焦机制则可以避免上述操作,RNN模型逐个处理输入词语的信息,随即生成相对应的词语。
RNN模型之间的这类聚焦还有许多其它的应用。它可以用于语音识别(Chan, et al. 2015),其中一个RNN模型处理语音信号,另一个RNN模型则滑动处理其输出,然后关注相关的区域生成文本内容。
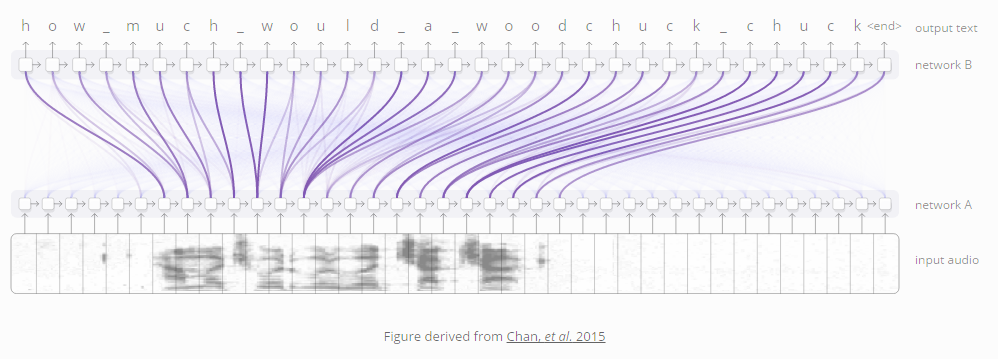
图片来自于 Chan, et al. 2015
聚焦机制的其它用途还包括文本解析(Vinyals, et al., 2014)生成一棵解析树,以及
用于会话模型(Vinyals & Le, 2015),模型可以根据之前的会话内容生成回复。
聚焦机制还能用作卷积神经网络CNN和RNN模型的接口。这使得RNN模型每一步都在关注图片的不同区域。这种方法的用途之一就是给图片添加描述。首先,用卷积神经网络处理图像,提取高层次的特征。然后运行RNN模型,生成图像的描述。随着RNN模型在图像的卷积网络特征的关注部位不同,生成相对于的描述文字。我们来将这个过程可视化:

图片来自 Xu, et al., 2015
推而广之,若某个神经网络的输出具有重复性的结构,就能使用聚焦接口(attentional interfaces)与这个神经网络相衔接。
聚焦接口被认为是一项非常普及和有效的技术,受到了越来越多的应用。
适应性计算时间(Adaptive Computation Time)
标准的RNN模型每一步所消耗的计算时间都相同。这似乎与我们的直觉不符。我们在思考难题的时候难道不需要更多的时间吗?
适应性计算时间(Adaptive Computation Time Graves, 2016)是解决RNN每一步消耗不同计算量的方法。笼统地说:就是让RNN模型可以在每个时间片段内进行不同次数的计算步骤。
为了让网络模型学会需要计算多少步,我们希望步数有区别性。因此我们采用了之前提到过的技巧:我们给需要计算的步数设了聚焦分布,而不是指定具体的数值。输出的是每一步的带权重结合。
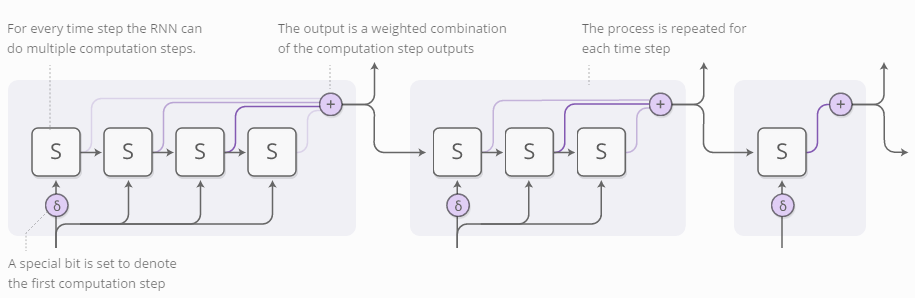
上图省略了不少细节内容。下图是一个时间片段的完整示意图,包括了三个计算步骤。
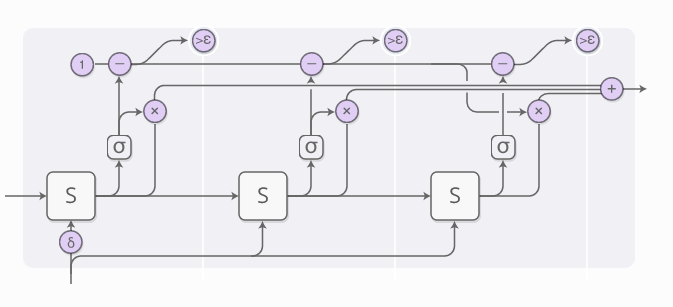
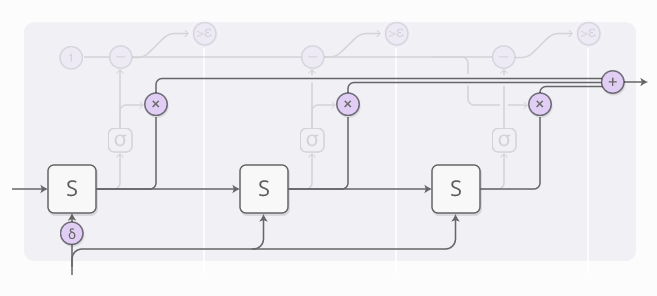
看上去有点儿复杂,所以我们一步步往下看。从较高的层次观察,我们仍旧运行RNN模型,输出各个状态的带权重组合:
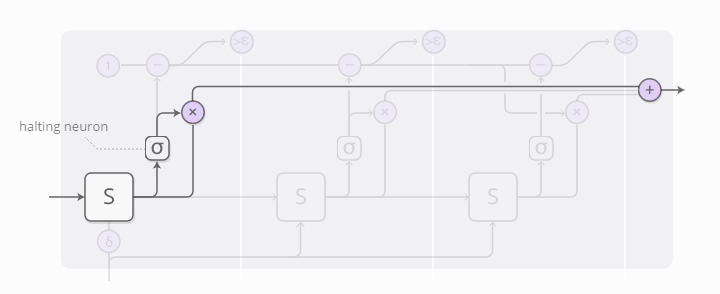
每一步的权重值由“halting neuron”决定。这个神经元事实上是一个sigmoid函数,输出一个终止权重,可以理解为需要在当前步骤终止的概率值。
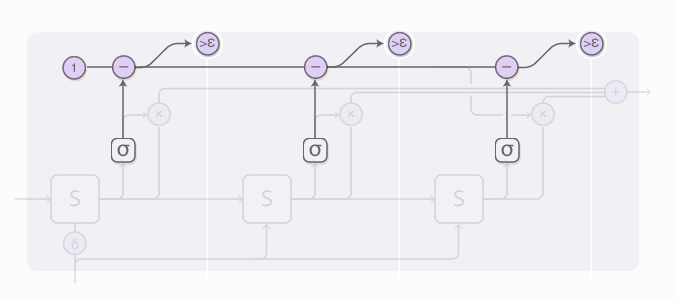
停止权重值的总和等于1,每一步结束后要减去相应的值。一旦这个值小于了epsilon,我们就停止计算。
当训练Adaptive Computation Time模型时,可以在损失函数添加一项“ponder cost”,用来惩罚模型的累积计算时间。这一项的值越大,就更不倾向于降低计算时间。
ACT仍是一个非常新的概念,但是我们相信它以及其它类似的概念今后一定会发挥作用。
代码
目前开源的ACT代码貌似只有 Mark Neumann’s (TensorFlow)
展望
在某种程度上,事先有准备的人会比两手空空的人更聪明。我们使用数学符号能解决许多新问题,而我们依靠计算机则可以完成更多不可思议的任务,远远超出了我们的个人能力。
一般来说,智慧的表现形式往往是人类启发式直觉与更细腻的媒介的交互过程,比如语言和公式。有时候,这种媒介是实实在在存在的物体,可以用来存储信息,避免我们犯错误或是进行繁重的计算任务。在其它情况下,这种媒介是我们脑子里的模型。无论如何,它似乎是智慧的基础。
机器学习领域的最新研究成果已经带有这种味道了,将神经网络的直觉与其他东西结合。一种方法是所谓的“启发式搜索”。例如,AlphaGo (Silver, et al., 2016) 建立了一个下围棋的模型,在神经网络的指导下探索如何进行游戏。同样的,DeepMath (Alemi, et al., 2016)利用神经网络处理数学表达式。我们在本文中提到的“增强RNN”属于另一种方法,我们将RNN模型与工程媒介相结合,以提高它们的泛化能力。
与媒介的互动自然会涉及到一系列的采取行动、观察情况、继续行动步骤。这就产生了一个重大的挑战:我们如何学习该采取哪些行动?这听起来像是一个强化学习的问题,我们当然可以采取强化学习方法。但是强化学习也正在攻坚解决这些难题,其解决办法目前也很难被采用。聚焦的好处在于它让我们比较轻松地绕开了这个问题,我们可以不同程度地采取所有行动。而强化学习只允许我们选择一条道路,从中学习经验。聚焦机制在岔路口会选择所有的方向,然后将各条路径的结果合并起来。
聚焦机制的一大弱点就是每一步都需要执行一个“行动”。这导致消耗的计算资源呈线性增长。有一种解决方式是将聚焦稀疏化,因此只需要处理其中的一部分记忆单元。然而,也许你希望聚焦点是基于记忆单元的,这样势必需要浏览所有的内存单元,这又带来了不小的挑战。我们看到了一些初步的解决方案,例如Andrychowicz & Kurach, 2016,似乎还有很大的提升空间。
增强RNN和其背后的聚焦技术真的领入兴奋。我们期待看到它们取得更大的进展!















 814
814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









