







0
写在前面
基于Self-Attention的Transformer结构,首先在NLP任务中被提出,最近在CV任务中展现出了非常好的效果。然而,大多数现有的Transformer直接在二维特征图上的进行Self-Attention,基于每个空间位置的query和key获得注意力矩阵,但相邻的key之间的上下文信息未得到充分利用。
本文设计了一种新的注意力结构CoT Block,这种结构充分利用了key的上下文信息,以指导动态注意力矩阵的学习,从而增强了视觉表示的能力。
作者将CoT Block代替了ResNet结构中的3x3卷积,来形成CoTNet,最终在一系列视觉任务(分类、检测、分割)上取得了非常好的性能,此外,CoTNet在CVPR上获得开放域图像识别竞赛冠军。
1
论文和代码地址

论文地址:https://arxiv.org/abs/2107.12292
代码地址:https://github.com/JDAI-CV/CoTNet
核心代码:https://github.com/xmu-xiaoma666/External-Attention-pytorch#22-CoTAttention-Usage
2
Motivation
起初,CNN由于其强大的视觉表示学习能力,被广泛使用在各种CV任务中,CNN这种局部信息建模的结构充分使用了空间局部性和平移等边性。但是同样的,CNN由于只能对局部信息建模,就缺少了长距离建模和感知的能力,而这种能力在很多视觉任务中又是非常重要的。
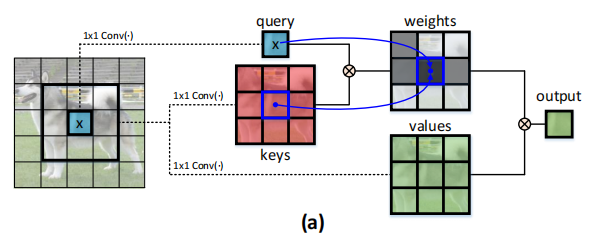
Transformer由于其强大的全局建模能力,被广泛使用在了各种NLP任务中。受到Transformer结构的启发,ViT、DETR等模型也借鉴了Transformer的结构来进行长距离的建模。然而,原始Transformer中的Self-Attention结构(如上图所示)只是根据query和key的交互来计算注意力矩阵,因此忽略了相邻key之间的联系。
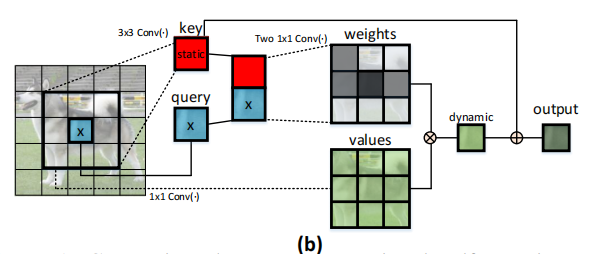
基于此,作者提出了这样一个问题——“有没有一种优雅的方法可以通过利用二维特征图中输入key之间的上下文来增强Transformer结构?”因此作者就提出了上面的结构CoT block。传统的Self-Attention只是根据query和key来计算注意力矩阵,从而导致没有充分利用key的上下文信息。
因此作者首先在key上采用3x3的卷积来建模静态上下文信息,然后将query和上下文信息建模之后的key进行concat,再使用两个连续的1x1卷积来自我注意,生成动态上下文。静态和动态上下文信息最终被融合为输出。(简单的说,就是作者先用卷积来提取了局部了信息,从而充分发掘了key内部的静态上下文信息 )
3
方法
3.1. Multi-head Self-attention
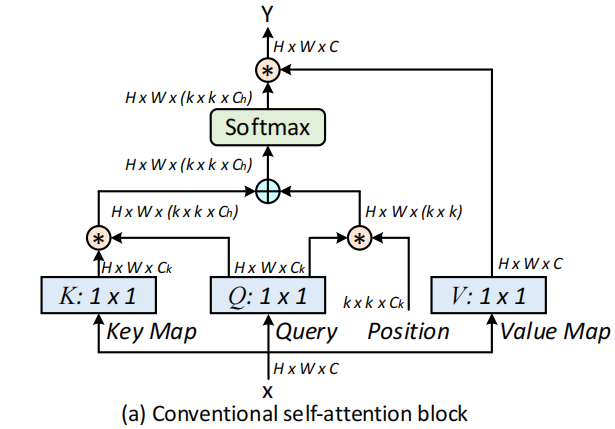
目前在视觉的backbone中,通用的可扩展的局部多头自我注意(scalable local multi-head self-attention),如上图所示。首先用1x1的卷积上X映射到Q、K、V三个不同的空间,Q和K进行相乘获得局部的关系矩阵:

由于原始的Self-Attention对输入特征的位置是不敏感的,所以还需要在Q上加上位置信息,然后将结果与关系矩阵相加:
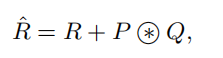
接着,我们还需要对上面得到的结果进行归一化,得到Attention Map:

得到Attention Map之后,我们需要将kxk的局部信息进行聚合,然后与V相乘,得到Attention之后的结果:
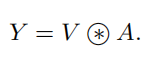
3.2. Contextual Transformer Block
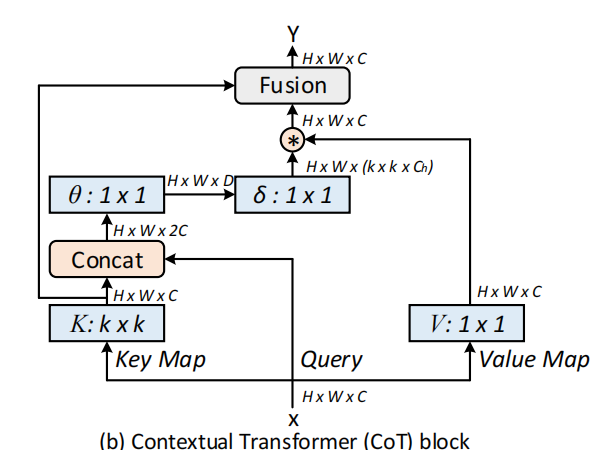
传统的Self-Attention可以很好地触发不同空间位置的特征交互。然而,在传统的Self-Attention机制中,所有的query-key关系都是通过独立的quey-key pair学习的,没有探索两者之间的丰富上下文,这极大的限制了视觉表示学习。
因此,作者提出了CoT Block,如上图所示,这个结构将上下文信息的挖掘和Self-Attention的学习聚合到了一个结构中。
首先对于输入特征 ,首先定义了三个变量
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2538
2538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









