







 本文探讨了论文《Attacking and Defending Deep Reinforcement Learning Policies》中关于深度强化学习的对抗攻击和防御方法。作者提出了一种贪婪攻击算法和防御算法,通过对抗训练提高策略的鲁棒性。实验表明,所提攻击算法能更有效地降低策略回报,而防御算法在对抗多种攻击时展现出更高韧性。
本文探讨了论文《Attacking and Defending Deep Reinforcement Learning Policies》中关于深度强化学习的对抗攻击和防御方法。作者提出了一种贪婪攻击算法和防御算法,通过对抗训练提高策略的鲁棒性。实验表明,所提攻击算法能更有效地降低策略回报,而防御算法在对抗多种攻击时展现出更高韧性。
关注公众号,发现CV技术之美
本篇文章分享论文『Attacking and Defending Deep Reinforcement Learning Policies』,深度强化学习中的对抗攻击和防御。

论文链接:https://arxiv.org/abs/2205.07626v1
01
引言
该论文是关于深度强化学习对抗攻击的工作。在该论文中,作者从鲁棒优化的角度研究了深度强化学习策略对对抗攻击的鲁棒性。在鲁棒优化的框架下,通过最小化策略的预期回报来给出最优的对抗攻击,相应地,通过提高策略应对最坏情况的性能来实现良好的防御机制。
考虑到攻击者通常无法在训练环境中攻击,作者提出了一种贪婪攻击算法,该算法试图在不与环境交互的情况下最小化策略的预期回报;另外作者还提出一种防御算法,该算法以最大-最小的博弈来对深度强化学习算法进行对抗训练。
在Atari游戏环境中的实验结果表明,作者提出的对抗攻击算法比现有的攻击算法更有效,策略回报率更差。论文中提出的对抗防御算法生成的策略比现有的防御方法对一系列对抗攻击更具鲁棒性。
02
预备知识
2.1对抗攻击
给定任何一个样本(x,y)和神经网络f,生成对抗样本的优化目标为:
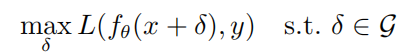
其中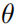 是神经网络f的参数,L是损失函数,
是神经网络f的参数,L是损失函数,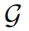 是对抗扰动集合,
是对抗扰动集合,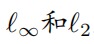 是以x为中心,
是以x为中心,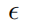 为半径的范数约束球。通过PGD攻击生成对抗样本的计算公式如下所示:
为半径的范数约束球。通过PGD攻击生成对抗样本的计算公式如下所示:
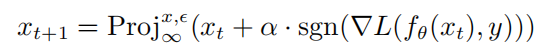
其中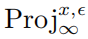 表示的是投影操作,如果输入在范数球外,则将输入投影到以x中心,
表示的是投影操作,如果输入在范数球外,则将输入投影到以x中心,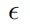 为半径的
为半径的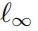 球上,
球上, 表示的是PGD攻击的单步扰动大小。
表示的是PGD攻击的单步扰动大小。
2.2强化学习和策略梯度
一个强化学习问题可以被描述为一个马尔可夫决策过程。马尔可夫决策过程又可以被定义为一个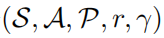 的五元组,其中S表示的是一个状态空间,A表示的是一个动作空间,
的五元组,其中S表示的是一个状态空间,A表示的是一个动作空间,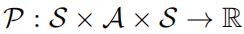 表示的是状态转移概率,r表示的是奖励函数,
表示的是状态转移概率,r表示的是奖励函数,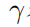 表示的是折扣因子。强学学习的目标是去学习一个参数策略分布
表示的是折扣因子。强学学习的目标是去学习一个参数策略分布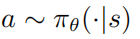 使得价值函数最大化
使得价值函数最大化
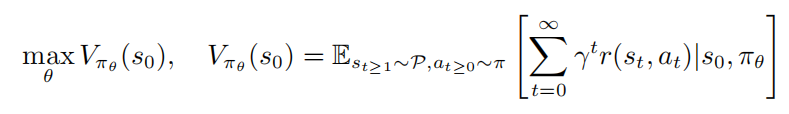
其中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7194
7194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









