






关注公众号,发现CV技术之美
本篇分享 ICME 2022 论文『FEDIC: Federated Learning on Non-IID and Long-Tailed Data via Calibrated Distillation』,通过校准蒸馏对非独立同分布和长尾数据进行联合学习。
详细信息如下:

论文链接:https://arxiv.org/abs/2205.00172
代码链接:https://github.com/shangxinyi/FEDIC
01
背景与引言
深度学习技术被部署在移动设备中,以处理来自不同来源的数据,但在数据传输过程中对于服务供应商和移动设备使用者都是高风险的,可能存在隐私泄露风险。联邦学习技术通过在每个客户端本地存储数据和训练模型来保证数据隐私,但是由于每个客户端中的数据可能来自不同的分布,因此在此类数据上进行训练会导致全局模型的泛化能力较差。
先前方法往往通过改进本地训练过程或者采用特定的模型聚合机制来缓解数据异质性的负面影响,虽然上述方法在一定程度上解决了Non-iid问题,但它们通常假设通用类分布是平衡的,从实际角度来看这可能并不正确。
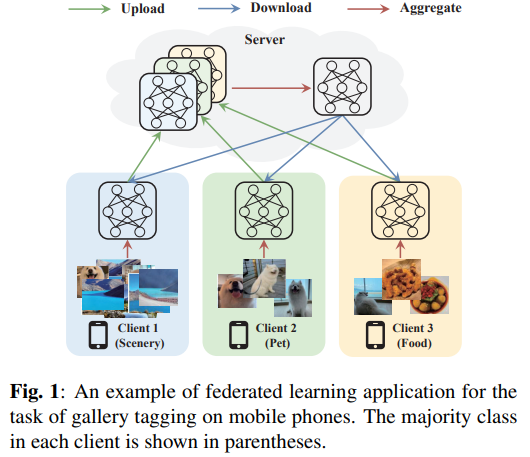
如下图1所示,如果我们考虑整体客户,像风景这样的少数类有大量样本,而像宠物或食品这样的许多类只占一小部分,这种分布上建立分类模型称为长尾学习。由于缺乏对通用长尾分布的考虑,联邦学习中非独立同分布数据的现有解决方案通常在尾类数据上表现不佳。全局模型通过聚合客户端上的本地模型往往也在尾部数据上产生偏差,最近有工作提出比率损失来评估全局不平衡状态从而改善本地模型优化,然而随着数据非独立同分布程度的增加也会导致模型性能逐渐下降。
本文主要研究Non-iid和长尾分布上的联邦学习问题,无需事先了解全局类分布情况下,提出了一种有效的服务器端优化方法,称为不平衡校准的联邦集成蒸馏。基于FedIC算法,在服务器上采用知识蒸馏技术将知识从集成模型转移到全局模型,但是在长尾设置中,集成模型可能仍然偏向于头类数据,因此可能导致迁移的知识没有帮助。
因此,本文提出一种新的集成校准方法,以在进行知识蒸馏之前消除集成模型的偏差。具体来说,作者首先提出了一种新的 logit校准方法,分别从客户端和类的角度重构集成模型。然后,提出了一种校准门控网络以有效地融合基于集成表示的调整后的logits,最终的集成模型在校准后在头类和尾类数据上都能很好地泛化。
02
FedIC方法
Problem Settings:学习场景基于一个典型的联邦学习系统,其中K个客户端持有潜在的Non-iid本地数据集(D1,D2,…,DK)。此外,数据集D是满足长尾分布情况,即D∈(X,Y)且Y∈{1,…,C}。联邦学习模型是神经网络并且包含两个组件:特征抽取器fw(将样本映射到d维向量)以及分类器hw(用于输出置信度的全连接神经网络层)。
Proposed Method:FedIC是一种基于FedAvg的服务器端方法,而无需干预每个客户端的本地训练过程:相比通过参数平均产生的全局模型,通过集成本地客户端模型具有更好的泛化能力。由于本地模型是在Non-iid数据上进行训练,因此它们的预测结果高度多样化,这是使集成模型比单个本地模型工作得更好的重要因素之一。
但是由于模型的异构性,集成模型无法引导客户端进行进一步更新,因此考虑使用知识蒸馏将泛化能力从本地客户端集成模型转移到全局模型。
具体来说,在服务器上,我们可以构建集成模型作为教师模型(如下公式(1)所示,其中ek代表第k个本地客户端的模型参数权重):
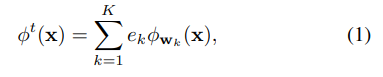
接着,我们得到全局模型w (基于FedAvg聚合),并将其看作对应的学生模型:
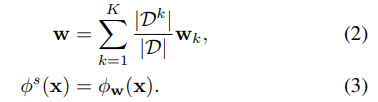
但是存在一个问题:当通用类分布是长尾分布时,集成模型对尾类的泛化能力会很差,因此它不能为尾部类的学生模型提供有用的指导。因此,作者提出在服务器上使用一个小的辅助数据集Daux(有标签且类平衡的),从而针对长尾分布来校准集成模型。
利用辅助数据的主要原因是服务端和客户端的全局不平衡程度都是未知的,这使得大多数长尾学习方法不可行,并且所有辅助数据都是在服务器上独立收集的而不涉及数据传输或数据共享。关于FedIC模型架构图如下图2所示,接下来将详细描述FedIC两个核心组件:集成校准与集成蒸馏。
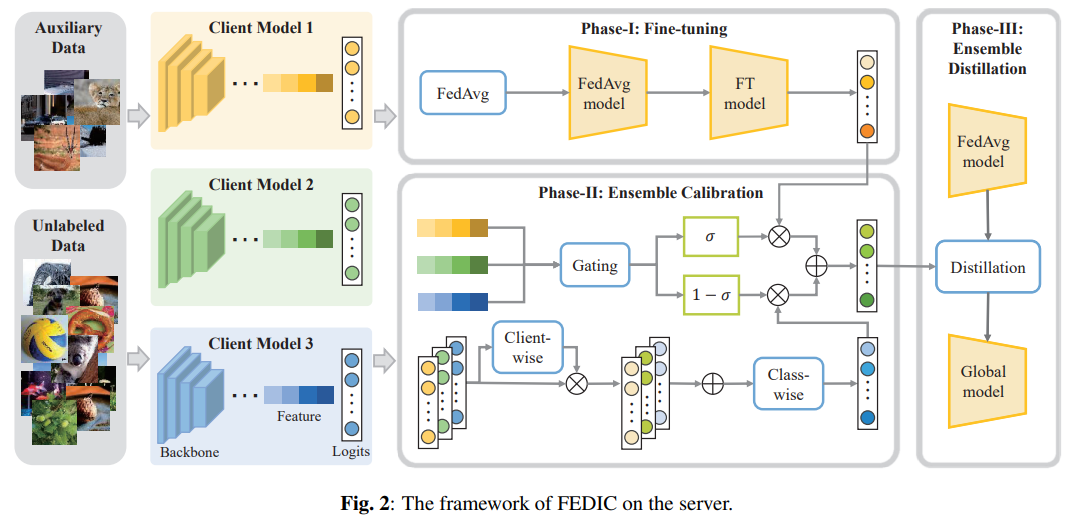
Ensemble Calibration:基于不同分布的局部数据进行训练,因此每个本地模型在尾类上的表现可能不同。进一步提出:为在尾类上表现良好的本地模型分配更高的集成权重以提高集成模型的泛化能力。提出了客户端logit调整策略:通过可学习参数搜索合适的集成权重ek。给定数据样本x∈Daux,我们首先计算本地模型Wk(x)的logits,通过非线性变换来计算集合权重ek:
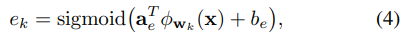
然后可以计算局部模型的加权logits,如公式(1)所示,但是由于长尾分布导致加权集成仍然偏向于头部类。因此作者提出class-wise logit,通过可学习的参数az和bz进一步增强尾类数据的logit:将原始加权集成logits进行线性转换:
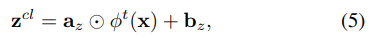
进一步而言,logit调整的有效性前提是特征提取得好,因此作者建议更新特征提取器从而增强logit调整。具体地说,我们可以通过在Daux上对全局模型进行微调来更新模型,由于Daux是平衡的,因此通过调整可以获取无偏特征提取的能力,最后通过微调后的模型基于输入x进行特征提取得到logits为Zft。基于Zcl和Zft从而处理长尾分布,但它们来自不同的角度,其中Zcl根据模型集成产生,使用固定的特征提取器;而Zft基于Daux微调后的全局模型产生。
此外,作者还提出了一种校准门控网络来控制Zft和Zcl之间的权衡,以便有效地整合集成和微调的逻辑,使它们相辅相成。该校准门控网络将特征集合作为输入,通过一个非线性层输出权重,使得每个样本根据自己的特征获得不同的权重,其公式如下(其中u是一个可学习参数,而v则是集成后的本地客户端模型特征feature ensemble):
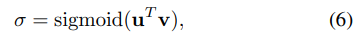
因此,通过校准门控网络的最终校准后的logits被表示为:
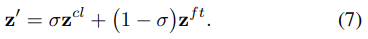
在集成校准的整个过程中,所有可学习的参数都通过交叉熵损失来更新,并且数据(X,Y)~Daux,具体损失函数如下:

Ensemble Distillation:为了更好地从教师模型(校准的集成模型)向学生模型(全局模型)传输无偏知识,进行了知识蒸馏工作:LCE(学生模型自身的交叉熵损失函数)+LKL(教师模型和学生模型之间的Kullback Leibler损失函数)。基于数据集Daux计算LCE,并使用另一个未标记的数据集Dulb计算LKL来进一步提高蒸馏知识的性能。因此,最终的损失LFedIC由权衡超参数λ(通常λ=0.5)构成:
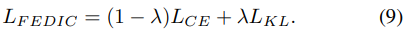
03
实验验证
3.1.实验设置
数据集设置:
CIFAR-10/100-LT:首先从训练数据中去除全局平衡的辅助数据集Daux,然后将其余数据塑造成具有不同不平衡因子(IF)的长尾分布,其基于最大类的样本数与最小类的样本数之比计算。对于未标记的数据集Dulb,对于CIFAR-10-LT使用CIFAR-100作为未标记数据集,对于CIFAR-100-LT数据集使用下采样的ImageNet数据集。
ImageNet-LT:ImageNet的长尾版本。它包含来自1000个类别的115.8K图像,其中最大和最小的类别分别包含1280张和5张图像。类似的从平衡评估数据中获得辅助数据Daux,并使用过采样CIFA R-100数据集(图像大小为224)作为Dulb。
实验准备:CIFAR-10-LT和CIFAR-100-LT使用ResNet-8作为主干网络,ImageNet-LT使用ResNet-50作为主干网络。默认情况下,运行200轮全球通信,总共有20个客户端,每轮的活跃用户率C=40%,对于本地训练,批次大小设置为128,SGD为优化器(学习率为0.1),知识蒸馏则使用Adam作为优化器(学习率为0.001)运行100个step。Non-iid划分则基于狄利克雷分布(α=0.1)。
基准比较:为了验证FedIC的有效性,我们将该方法与以下联邦学习方法进行了比较:FedAvg, FedAvgM, FedProx, FedNova,以及基于蒸馏的联邦学习方法:FedDF与FedBE。此外还比较了面向不平衡的联邦学习方法:Fed-Focal Loss, Ratio Loss, FedAvg with post-hoc方法。
3.2.结果分析:
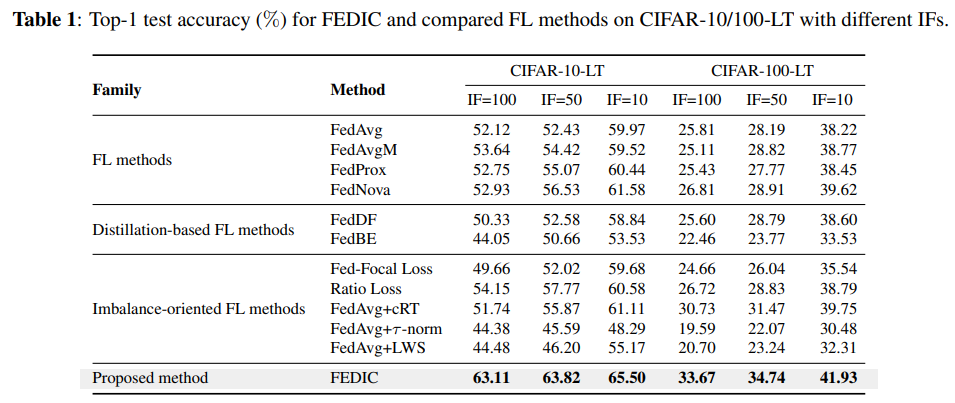
Results on CIFAR-10/100-LT:从下表1中可以看出,FedIC在具有不同不平衡因子的两个数据集上实现了最高的测试精度,与FedAvg相比,当IF=100时FedIC的性能增益最高,这无疑表明了FedIC在普适类分布高度长尾情况下的泛化能力。
其余基准方法的性能类似于FedAvg,因为只处理数据Non-iid,而不考虑全局不平衡的类长尾分布,而基于蒸馏的方法,FedDF和FedBE的表现甚至比FedAvg更差,这是由于全局分布不平衡,集成模型在尾类上的表现可能甚至比全局模型更差,从而导致更差的蒸馏教师模型。
这一观察结果也证实了FedIC中集成校准组件的必要性。对于面向不平衡的FL方法,与FedAvg相比,其中一些方法在某些情况下表现得很好,但是仍与FedIC存在性能差距,因为它们忽略了数据Non-iid问题。
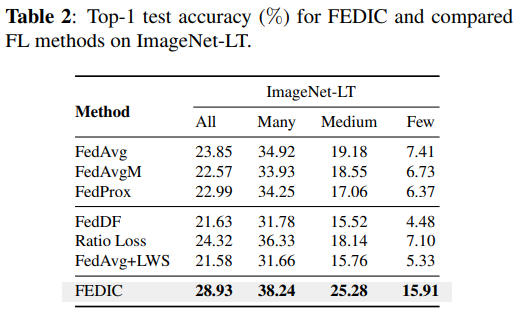
Results on ImageNet-LT:在ImageNet-LT上评估FedIC,其结果如下表2所示,与其他方法相比,FedIC在目前所尝试的所有案例上都取得了最好结果。其中在Few上准确率达到了15.91%,与基线相比显著提升了8.5%。
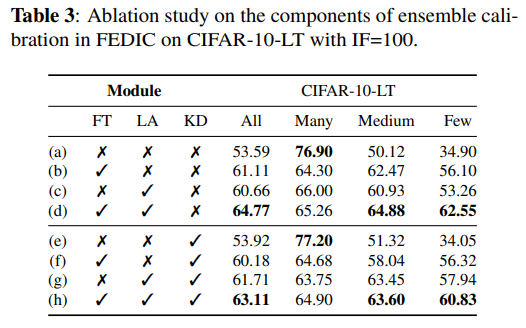
消融实验:进行消融实验以评估FedIC各个组件的必要性,如下表3所示,主要评估了FedIC的三个组件:微调(FT), 集成校准(LA)以及知识蒸馏(KD)。我们可以看出与基线相比,校准后的模型总体精度提高了11.2%,而教师模型(d)与学生模型(h)之间的总体精度差距仅有1.7%,这说明了处理长尾分布的泛化能力被成功转移。
Daux与Dulb影响:Daux和Dulb的大小在FedIC中起着关键作用,因此我们评估了其对FedIC性能影响:与基准FedAvg和使用Daux微调的全局模型(FT)进行了比较,如图3所示(图中不同的曲线表示用于蒸馏的未标记数据的数据量)。可以看出,FedIC的性能表现始终优于FedAvg和FT。
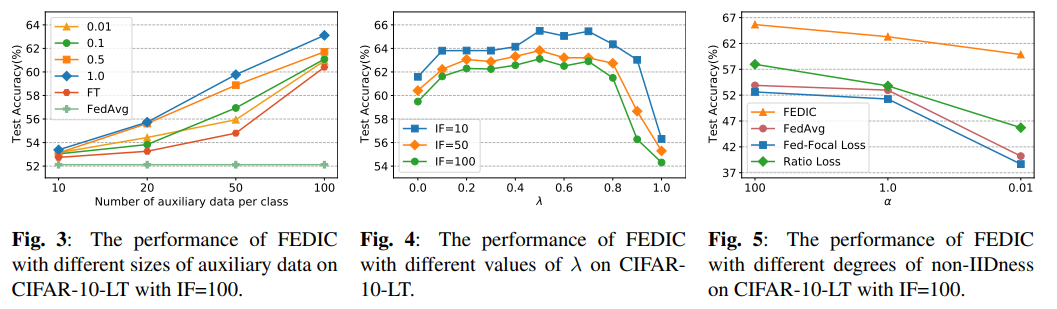
超参数分析:此外,还调查了蒸馏权衡系数λ的影响,是在损失函数中用于控制蒸馏强度。从上图4中可以看出,FedIC对于大多数λ是健壮的,然而,当λ达到1时,性能会严重下降,这表明对于一个好的全局模型来说,仅使用未标记数据的蒸馏是不够的。
Non-iid程度影响:如上图5所示,进一步显示了四种方法在不同程度的非独立同分布下的测试精度。我们可以观察到,所有方法的性能都随着非独立同分布程度的增加而下降,然而当α从1.0时降至0.01时,其余方法性能下降比FedIC更加严重。
04
总结归纳
FedIC用以解决联邦学习框架中Non-iid和长尾数据分布的全局模型训练困难问题,其是一种服务器端方法:首先通过使用校准门控网络以及集成校准方法来针对长尾分布校准本地客户端集成模型,然后使用校准后的集成模型作为教师模型,将知识传递到全局模型(学生模型),以便在客户端进行进一步的优化。总得来看,FedIC通过集成校准消除本地客户端集成模型的异构性(统计异构性与长尾分布)偏差,然后将该logits作为知识传递给全局模型。

END
加入「计算机视觉」交流群👇备注:CV


















 712
712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









