







Wayve发表在ICRA2024上关于端到端大语言模型自动驾驶的文章。
摘要: 大语言模型(LLMs)在自动驾驶领域显示出前景,尤其是在泛化能力和可解释性方面。我们引入了一种独特的对象级多模态LLM架构,该架构将矢量化的数值模态与预训练的大语言模型相结合,以改善驾驶情境中的上下文理解。我们还提供了一个新的数据集,该数据集包含16万对问答对,源自1万个驾驶场景,并与通过强化学习代理收集的高质量控制命令以及由教师LLM(GPT-3.5)生成的问答对配对。我们设计了一种独特的预训练策略,通过使用矢量标注语言数据将数值矢量模态与静态LLM表示对齐。我们还引入了一种用于驾驶问答的评估指标,并展示了我们的LLM驾驶员在解释驾驶场景、回答问题和决策方面的能力。我们的研究结果突出了基于LLM的驾驶行为生成在与传统行为克隆方法相比时的潜力。我们提供了我们的基准、数据集和模型供进一步探索。
1. 引言
大语言模型(LLMs)的卓越能力展示了人工通用智能(AGI)的早期迹象【1】。这些能力包括分布外推理、常识理解、知识检索以及与人类自然交流的能力。这些能力与自动驾驶和机器人技术的重点领域高度契合【2】【3】。
现代可扩展的自动驾驶系统,无论是采用使用单一网络的端到端方法【4】,还是结合可学习的感知和运动规划模块的组件化配置【5】【6】,都面临着共同的挑战。这些系统在决策过程中通常表现为“黑箱”,这使得赋予它们分布外推理和可解释性能力尤其困难。尽管在解决这些问题方面已经取得了一些进展【7】,但这些问题依然存在。
文本或符号模态由于其在逻辑推理、知识检索和人类交流方面的内在适用性,是利用大语言模型(LLMs)能力的绝佳媒介【8】。然而,其线性顺序性质限制了对细致空间理解的能力,而空间理解是自动驾驶的关键方面。视觉语言模型(VLMs)中的开创性工作已开始通过融合视觉和文本模态来弥合这一差距【9】,使预训练的LLMs能够进行空间推理。然而,将新模态有效地融入语言表示空间需要大量标注图像数据的广泛预训练。
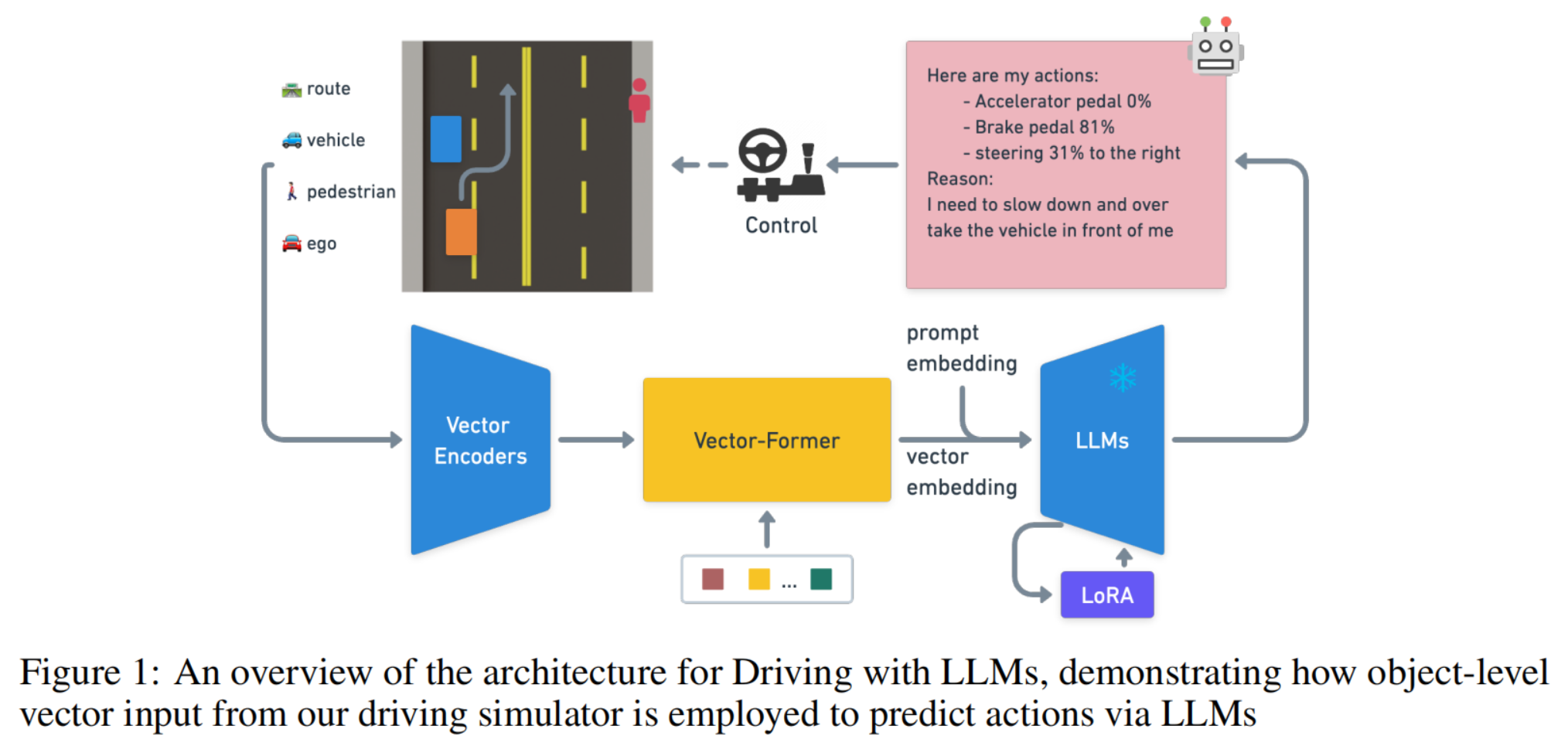
我们提出了一种将数值向量模态(一种在机器人技术中常用于表示速度、执行器位置和距离测量的数据类型)整合到预训练大语言模型(LLMs)中的新方法。这种模态比视觉模态更紧凑,从而缓解了一些视觉语言模型(VLM)扩展的挑战。具体来说,我们将常用于自动驾驶的对象级二维场景表示的矢量化数据,通过适配器【10】融合到预训练的LLM中。这种融合使模型能够直接解释和推理综合的驾驶情境。结果是,LLMs能够作为自动驾驶系统的“大脑”,直接与模拟器交互,以促进推理和动作预测。
为了以可扩展的方式获取训练数据,我们首先使用定制的二维模拟器,并训练一个强化学习(RL)代理来解决驾驶场景,作为人类驾驶专家的替代。**为了将对象级向量映射到LLMs中,我们引入了一个语言生成器,将这些数值数据翻译成文本描述以进行表示预训练。**我们进一步利用教师LLM(GPT)生成一个基于1万个不同驾驶场景的语言描述的问题回答数据集。我们的模型首先经历一个预训练阶段,以增强数值向量模态与潜在语言表示之间的对齐。接下来,我们训练我们的新架构,建立一个稳健的基准模型,LLM-driver,用于驾驶动作预测和驾驶问题回答任务。我们提供了我们的数据集、评估基准和预训练模型,以便重现并希望激发和促进该领域的进一步发展。本文的后续部分详细介绍了理论背景、我们提出的架构和实验设置、初步结果、未来研究的潜在方向,以及我们工作的意义对自动驾驶领域的广泛影响。
本文的贡献如下:
- 新颖的对象级多模态LLM架构:我们提出了一种新颖的架构,将对象级矢量化数值模态与任何LLMs融合,采用两阶段预训练和微调方法。
- 驾驶场景问答任务和数据集:我们提供了一个包含16万个问答对的数据集,涉及1万个带有控制命令的驾驶情境,这些数据是由RL专家驾驶代理和基于专家LLM的问答生成器收集而来的。此外,我们还概述了进一步数据收集的方法论。
- 新颖的驾驶问答(DQA)评估和预训练基准:我们提出了一种新的方法来评估驾驶问答性能,使用了相同的专家LLM评分器。我们提供了初步的评估结果和使用我们的端到端多模态架构的基准。
我们的工作提供了将LLMs集成到模拟驾驶任务中的首创性基准方法。这包括一个全面的框架,涵盖了模拟器、自动数据收集、将新的对象级矢量模态整合到LLMs中以及基于GPT的评估方法。
2. 相关工作
2.1 端到端自动驾驶系统
近年来,在自动系统的端到端深度学习方法方面取得了显著进展【11】【12】【4】,其中一些最早的工作可追溯至ALVINN【13】,更近期的作品包括【14】。然而,现代自动驾驶系统面临的一个根本性挑战是在决策过程中缺乏可解释性【15】。理解为何做出某个决策对于识别不确定性领域、建立信任、实现有效的人工智能协作以及确保安全至关重要【16】。我们通过向端到端自动驾驶中添加矢量/文本模态和预训练LLMs,延续了这一研究方向。
2.2 自动驾驶系统的可解释性
已经引入了各种解释方法【17】,以理解深度神经网络的基础决策过程。例如,[18]、[19]和[20]是已经建立的模型无关的解释性方法,可以生成单个预测的解释。其他方法,如基于梯度的方法【21】、显著性图【22】和注意力图【23】,针对模型内部的操作,以解释决策过程。在自动驾驶领域,视觉注意力图提出了在驾驶图像中突出显示因果关系的区域【24】。在[25]中,作者将基于注意力的方法与自然语言相结合,创建了一种基于注意力的车辆控制器,根据一系列图像帧提供自然语言动作描述和解释。这项工作在[26]中进一步扩展,作者通过整合词性预测和特殊标记惩罚改进了架构。其他人认为仅仅使用注意力还不够【27】,因此进行了多种将这种方法与其他解释方法结合的努力。例如,[28]提出了利用关注类激活标记、编码特征、它们的梯度和它们的注意力权重同时解释transformers的方法。基于这项研究,我们提议在自动驾驶中使用文本模态进行可解释性解释。
2.3 自动驾驶任务中的多模态LLMS
最近,将多种模态集成到统一的大规模模型中的趋势引人注目。值得注意的例子包括VLMs,如[29]、[30]、[31]和[32],它们有效地结合了语言和图像,完成了图像字幕、视觉问答和图像-文本相似性等任务。另一个值得注意的进步[33]涉及从六个不同模态融合信息:文本、图像/视频、音频、深度、热度和惯性测量。这一激动人心的发展不仅扩展了使用多样化的数据输入和输出类型生成内容的可能性,还实现了更广泛的多模态搜索能力。
由于摄像头传感器是自动驾驶中最常用的传感器之一【34】,通过VLMs将语言整合到自然的步骤已成为自然之举。例如,[35]使用图像和语言指令来训练驾驶策略。[36]提出了一种学习车辆控制的方法,通过人类辅助。系统学会用自然语言总结其视觉观察,预测适当的动作响应(例如,“我看到行人过马路,所以我停下来”),并相应地预测控制。使用语言来解释模型内部运作也在[37]中进行了探索,在这里为自动车辆控制和行动的每个决策步骤提供了用户友好的自然语言叙述和推理。
在机器人技术中,我们已经看到将语言与其他模态融合的努力。虽然在自动驾驶领域之外,但与我们最接近的工作[38]利用了具有潜在对象候选的3D边界框的点云。它还使用了一个指向场景中目标对象的语言话语,来训练一个能够从一组潜在候选中识别目标对象的模型。最近,RT-2论文[39]展示了一种类似的方法,利用LLMs进行低级机器人控制任务,包括联合训练VQA和控制任务。然而,他们的框架局限于视觉模态,而我们引入了一种新颖的方法,将基于向量的对象级模态与LLMs联系起来,促进可解释的控制和驾驶问答任务。与这些现有方法相比,据我们所知,本文提出的工作是首次在自动驾驶领域特别是在自动车辆领域将数值向量模态与语言融合。
3. 方法
3.1 使用RL生成数据
为了生成基于语言的基础驾驶数据集,我们使用了一个定制的现实感十足的二维模拟器,该模拟器能够生成驾驶场景。我们使用一个RL代理,该代理使用驾驶场景的对象级真实表示来解决模拟场景。在我们的方法中,我们使用基于注意力的神经网络架构,将环境使用向量表示映射到车辆动态动作。这个模型使用Proximal Policy Optimization(PPO)进行优化【40】。随后,我们从15个不同的虚拟环境中收集了连续的驾驶数据,这些环境具有随机生成的交通条件。我们的收集包括一个用于预训练的10万数据集,一个用于QA标记和微调的1万数据集,以及一个专门用于评估的1千数据集。
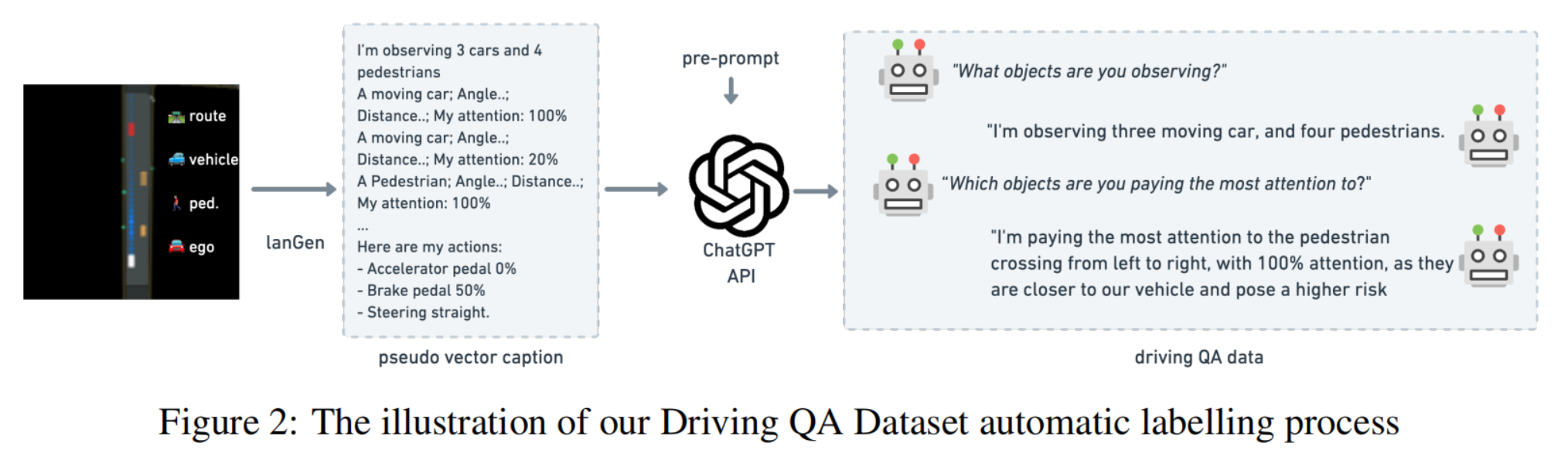
3.2 伪矢量字幕的结构化语言生成
在我们的框架中,我们旨在使用结构化语言生成器将向量表示转换为语言,以便将向量表示转化为LLMs。由于我们的对象级向量包含了重要的语义属性,如汽车和行人的数量,它们的位置、方向、速度、边界框和其他属性,我们使用了一个结构化语言生成器(lanGen)函数来制作从向量空间衍生的伪语言标签,如下所示:
在此函数中,变量 v c a r , v p e d , v e g o , v r o u t e v_{car},v_{ped},v_{ego},v_{route} vcar,vped,vego,vroute分别表示与汽车、行人、自车和路线对应的向量信息。可选项 [ o r l ] [o_{rl}] [orl]表示来自RL代理的输出,包括用于引导动作
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 996
996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









