







参加过两次天池上的数据挖掘比赛,成绩不是很好,在此期间也看过不少比赛冠军答辩ppt,查看大量的资料。在此总结下,同时也分享给对数据挖掘比赛有兴趣的同学。希望下次比赛能取得个好的成绩。
下面我将从下图的流程开始讲起。
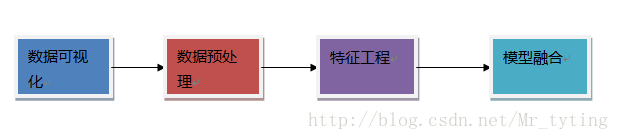
上面每一部分我都另外写了博文专门讲解,下面有链接。
数据可视化
可以通过数据可视化来验证我们对数据分布的一些猜想,使我们对数据分布有一个清晰的认识和理解,并且由此设计一些合理的人工规则。
对数据进行可视化可以清晰辨别数据样本中是否有离群点,对后来的数据预处理有很大的帮助。
我的另外一篇博客专门讲如何对数据以及高维数据做可视化处理。数据可视化处理
数据预处理
一: 数据清洗
检测异常样本方法
根据对具体业务的理解和认识去除一些异常极端的数据。例如在对网页浏览量的分析,可能需要去除爬虫用户的浏览数据。具体的处理方法请看我另外一篇博文的总结 机器学习–>检测异常样本方法总结
缺省字段的处理:分为四种情况
①缺省值极多:如果缺值的样本占总数比例极高,我们可能就直接舍弃了,作为特征加入的话,可能反倒带入noise,影响最后的结果了。
②非连续特征缺省值适中:如果缺值的样本适中,而该属性非连续值特征属性(比如说类目属性),那就把NaN作为一个新类别,加到类别特征中
③连续特征缺省值适中:如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。
④缺省较少:考虑利用填充的办法进行处理。这里又有许多种填充的方法和技巧。以下我列出最常用的几种办法。
- 均值,众数,中位数等填充办法
>>> import numpy as np
>>> from sklearn.preprocessing import Imputer
>>> imp = Imputer(missing_values='NaN',strategy='mean', axis=0)
>>> imp.fit([[1, 2], [np.nan, 3], [7, 6]])
Imputer(axis=0, copy=True, missing_values='NaN', strategy='mean', verbose=0)
需要注意的是:均值容易受到极端值的影响,不太稳定,故当用均值填充时,最好先剔除极端值,然后再算均值。或者用中位数填充,中位数受极端值影响较小。
- 模型填充办法:比如用sklearn里面的RandomForest模型去拟合数据样本训练模型,然后去填充缺失值
from sklearn.ensemble import RandomForestRegressor
### 使用 RandomForestClassifier 填补缺失的年龄属性
def set_missing_ages(df):
# 把已有的数值型特征取出来丢进Random Forest Regressor中
age_df = df[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
# 乘客分成已知年龄和未知年龄两部分
known_age = age_df[age_df.Age.notnull()].as_matrix()
unknown_age = age_df[age_df.Age.isnull()].as_matrix()
# y即目标年龄
y = known_age[:, 0]
# X即特征属性值
X = known_age[:, 1:]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型进行未知年龄结果预测
predictedAges = rfr.predict(unknown_age[:, 1::])
# 用得到的预测结果填补原缺失数据
df.loc[ (df.Age.isnull()), 'Age' ] = predictedAges
return df, rfr
- 拉格朗日插值法
import pandas as pd
from scipy.interpolate import lagrange
inputfile = 'catering_sale.xls'
outputfile= 'sales.xls'
data = pd.read_excel(inputfile)#读取excel
data[u'销量'][(data[u'销量']<400)|(data[u'销量']>5000)]=None#异常值变为空值
def ployinterp_column(s,n,k=5):#默认是前后5个
#tem=list(range(n-k,n))+list(range(n+1,n+1+k))
y=s[list(range(n-k,n))+list(range(n+1,n+1+k))]#取数,n的前后5个,这里有可能取到不存在的下标,为空
y=y[y.notnull()]#如果y里面有空值的话就去掉
#teml=lagrange(y.index,list(y))#这里代表的就是参数ai
return lagrange(y.index,list(y))(n)#最后的括号就是我们要插值的n
for i in data.columns:
if i==u'日期':
continue
for j in range(len(data)):
if(data[i].isnull())[j]:#空值进行插值
data[i][j] = ployinterp_column(data[i],j)
data.to_excel(outputfile)在保证原有数据样本分布不变情况下进行随机填充
在[mean-std,mean+std]内随机取数进行填充。
二: 数据采样
在数据正负样本不均衡情况下,当然正负样本不要求1:1,但是也不能太大。这里我们以正负样本比例 1:10为例,把这样不均衡的数据直接放进模型中进行训练,准确率肯定很高,因为大部分都可以预测为负样本。但是在测试集上效果很差。其泛化能力很弱。这时需要对数据进行采样,使得数据样本均衡。通常有四种办法来进行采样。
1. 从负样本中抽取部分样本出来和正样本结合。(欠采样,容易造成信息损失)
将负样本分为若干小份,即是对负样本进行随机的,有放回的采样,将每一小份和正样本结合成一个新的小的数据集,然后将这些若干个小的数据集放进不同分类器中进行训练,然后在进行一个Bagging融合得出结果。
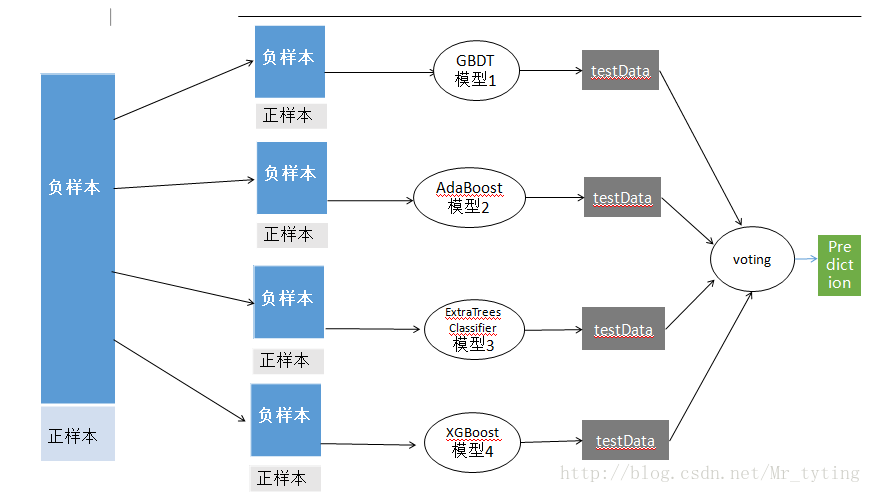
2 . 正样本重复若干次(上采样,保留的数据信息但是有可能放大其噪声数据)。
同上面道理一样,对正样本进行随机的有放回的重复采样使其数量上和负样本比例均衡,这个过程进行多次,那么就得出多个数据集。然后进行bagging。与欠采样相比,效果往往略差。
3 . SMOTE(合成少数过采样技术)

实现代码:
#encoding=gbk
from sklearn.neighbors import NearestNeighbors
import numpy as np
import random
class Smote:
#samples的最后一列是类标,都是1
def __init__(self, samples, N=10,k=5):
self.n_samples, self.n_attrs=samples.shape
self.N=N
self.k=k
self.samples=samples
def over_sampling(self):
if self.N<100:
old_n_samples=self.n_samples
print "old_n_samples", old_n_samples
self.n_samples=int(float(self.N)/100*old_n_samples)
print "n_samples", self.n_samples
keep=np.random.permutation(old_n_samples)[:self.n_samples]
print "keep", keep
new_samples=self.samples[keep]
print "new_samples", new_samples
self.samples=new_samples
print "self.samples", self.samples
self.N=100
N=int(self.N/100) #每个少数类样本应该合成的新样本个数
self.synthetic=np.zeros((self.n_samples*N, self.n_attrs))
self.new_index=0
neighbors=NearestNeighbors(n_neighbors=self.k).fit(self.samples)
print "neighbors", neighbors
for i in range(len(self.samples)):
nnarray=neighbors.kneighbors(self.samples[i],return_distance=False)[0]
#存储k个近邻的下标
self.__populate(N, i, nnarray )
return self.synthetic
#从k个邻居中随机选取N次,生成N个合成的样本
def __populate(self, N, i, nnarray):
for i in range(N):
nn = np.random.randint(0, self.k)
dif=self.samples[nnarray[nn]]-self.samples[i] #包含类标
gap=np.random.rand(1,self.n_attrs)
self.synthetic[self.new_index]=self.samples[i]+gap.flatten()*dif
self.new_index+=1 4.代价敏感学习Cost Sensitive Learning
在lossFunction里面给正样本赋予较高权重,使得能够更多的关注正样本。
特征工程
一:特征处理
数值型:各种标准化,离散化(等频,等宽离散化,长尾分布直接二类化),归一化,数据域变换(当你在原始数据上看不到数据内在的规律时,进行log,指数,Box-Cox变换可能会了解到数据的分布情况),或者和其他特征做一些组合特征。
类别型:one-hot编码
时间型:时间是否为一个节日,是否在一个时间段(类别型);或者计算距离某个日子变成间隔型;或者某个时间段内发生了多少次变成组合型等等;这个需要结合具体应用场景。使其变成离散型。
文本型:抽取特征,n-gram;Bag of words;TF-IDF;word2vector等等。
统计型:根据具体应用场景,统计一些对结果有影响的数据,比如方差,均值等等。
组合特征:对不同的特征做个组合,比如我们利用基于树的模型,挑选出最重要的一些特征,我们对这些特征两两做一些运算,比如加,减等运算,得到一些新的特征集,在利用xgboost或者gbdt等对得到的新特征集单独训练模型,并且得出新特征集中特征重要性排名,选取top k个特征加入到原来的特征集中。
上面处理的代码sklearn都有,可以查看我的一篇博文和sklearn相关内容,上面有详细的说明
数据预处理
sklearn特征抽取
二:连续特征离散化
离散化的重要性及其优势:
离散特征的增加和减少都很容易,易于模型的快速迭代;
稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰;
逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合;
离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问;
特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险。
可以将缺失作为独立的一类带入模型。
将所有变量变换到相似的尺度上。
那么如何对连续特征进行离散化呢?详情请看我的另外一篇博文: 金融风控–>申请评分卡模型–>特征工程(特征分箱,WOE编码)
三:特征选择
特征维度很高时,需要进行降维,可以查看我的另一篇关于sklearn中特征选择的博文sklearn特征选择
过滤型(不常用)
sklearn.feature_selection.SelectKBest
包裹型
sklearn.feature_selection.RFE
嵌入型
feature_selection.SelectFromModel
Linear model,L1正则化
需要注意的是:如果在特征选择之前,最好不要用one-hot或者dummiesVriable对类别型进行编码,因为特征选择时可能会剔除经one-hot衍生的一个特征。
四:模型选择
1 交叉验证
1.1 K折交叉验证:选择不同的模型,查看其在cross_validation上的好坏,取结果的平均值,增加结果的可信度。确定使用哪个模型。这部分可以查看我的另一篇博文sklearn.cross_validation
2 模型参数选择
确定了某种模型,然后需要确定超参数。
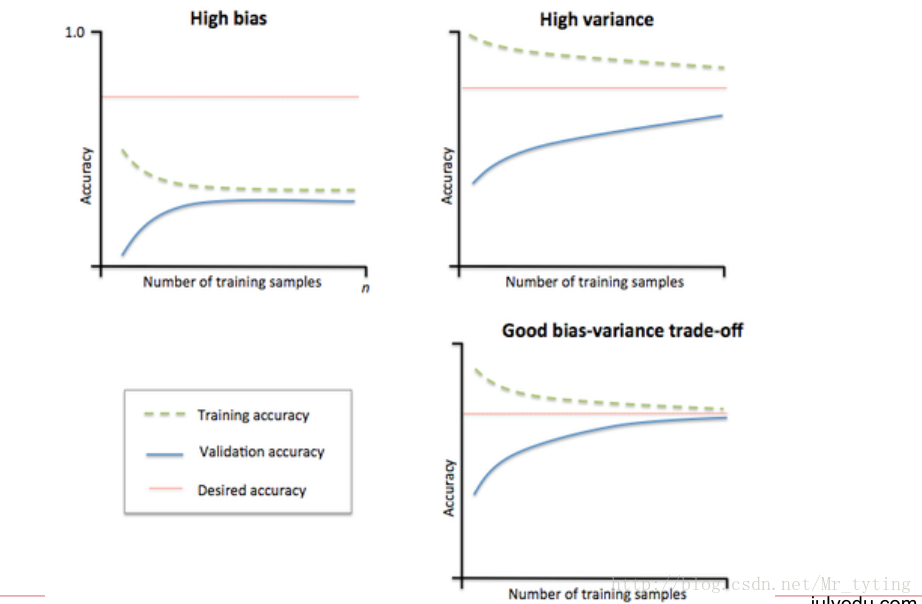
3 模型状态评估
查看当前参数的当前模型过拟合状态还是欠拟合状态。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.learning_curve import learning_curve
# 用sklearn的learning_curve得到training_score和cv_score,使用matplotlib画出learning curve
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1,
train_sizes=np.linspace(.05, 1., 20), verbose=0, plot=True):
"""
画出data在某模型上的learning curve.
参数解释
----------
estimator : 你用的分类器。
title : 表格的标题。
X : 输入的feature,numpy类型
y : 输入的target vector
ylim : tuple格式的(ymin, ymax), 设定图像中纵坐标的最低点和最高点
cv : 做cross-validation的时候,数据分成的份数,其中一份作为cv集,其余n-1份作为training(默认为3份)
n_jobs : 并行的的任务数(默认1)
"""
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, verbose=verbose)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
if plot:
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel(u"训练样本数")
plt.ylabel(u"得分")
plt.gca().invert_yaxis()
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std,
alpha=0.1, color="b")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std,
alpha=0.1, color="r")
plt.plot(train_sizes, train_scores_mean, 'o-', color="b", label=u"训练集上得分")
plt.plot(train_sizes, test_scores_mean, 'o-', color="r", label=u"交叉验证集上得分")
plt.legend(loc="best")
plt.draw()
plt.gca().invert_yaxis()
plt.show()
midpoint = ((train_scores_mean[-1] + train_scores_std[-1]) + (test_scores_mean[-1] - test_scores_std[-1])) / 2
diff = (train_scores_mean[-1] + train_scores_std[-1]) - (test_scores_mean[-1] - test_scores_std[-1])
return midpoint, diff
plot_learning_curve(clf, u"学习曲线", X, y)
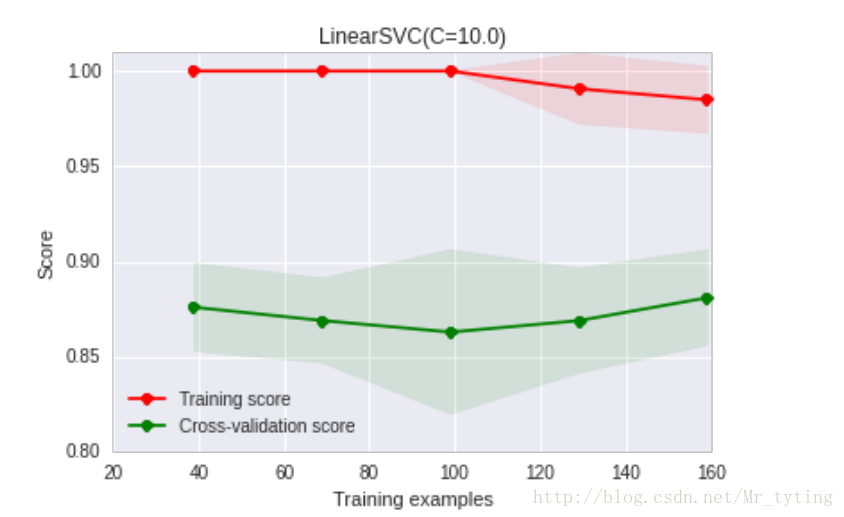
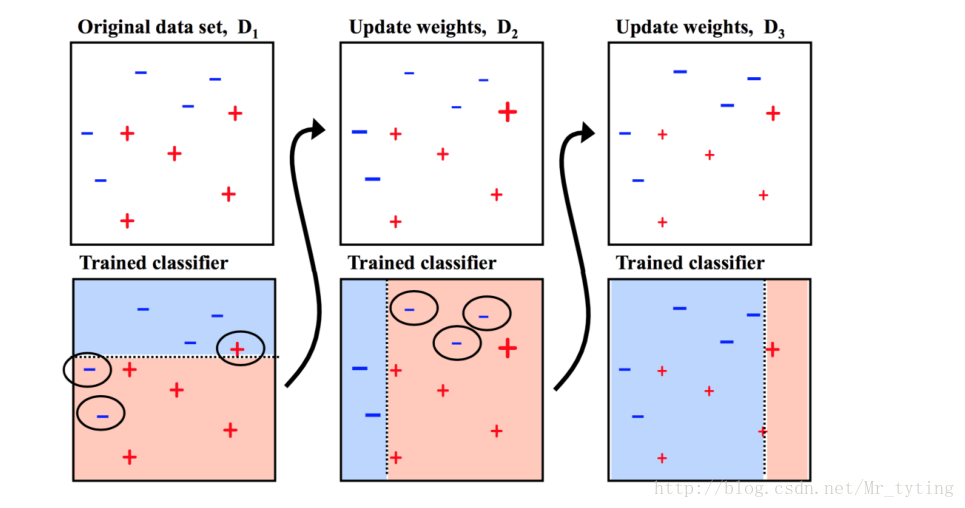
模型融合
这部分可以查看我的另一篇博文Bagging,Stacking,Boosting详细说明
1 Bagging(RandomForest)
1.1 用一个算法
不用全部的数据集,每次取一个子集训练一个模型
分类:用这些模型的结果做vote
回归:对这些模型的结果取平均
1.2 用不同的算法
用这些模型的结果做vote 或 求平均
2 Stacking
用多种predictor结果作为特征训练

















 2650
2650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









